Langjähriges KI-Hindernis ARC fällt durch die unaufhaltsame Optimierungsmaschinerie

Update vom 25. Dezember 2025:
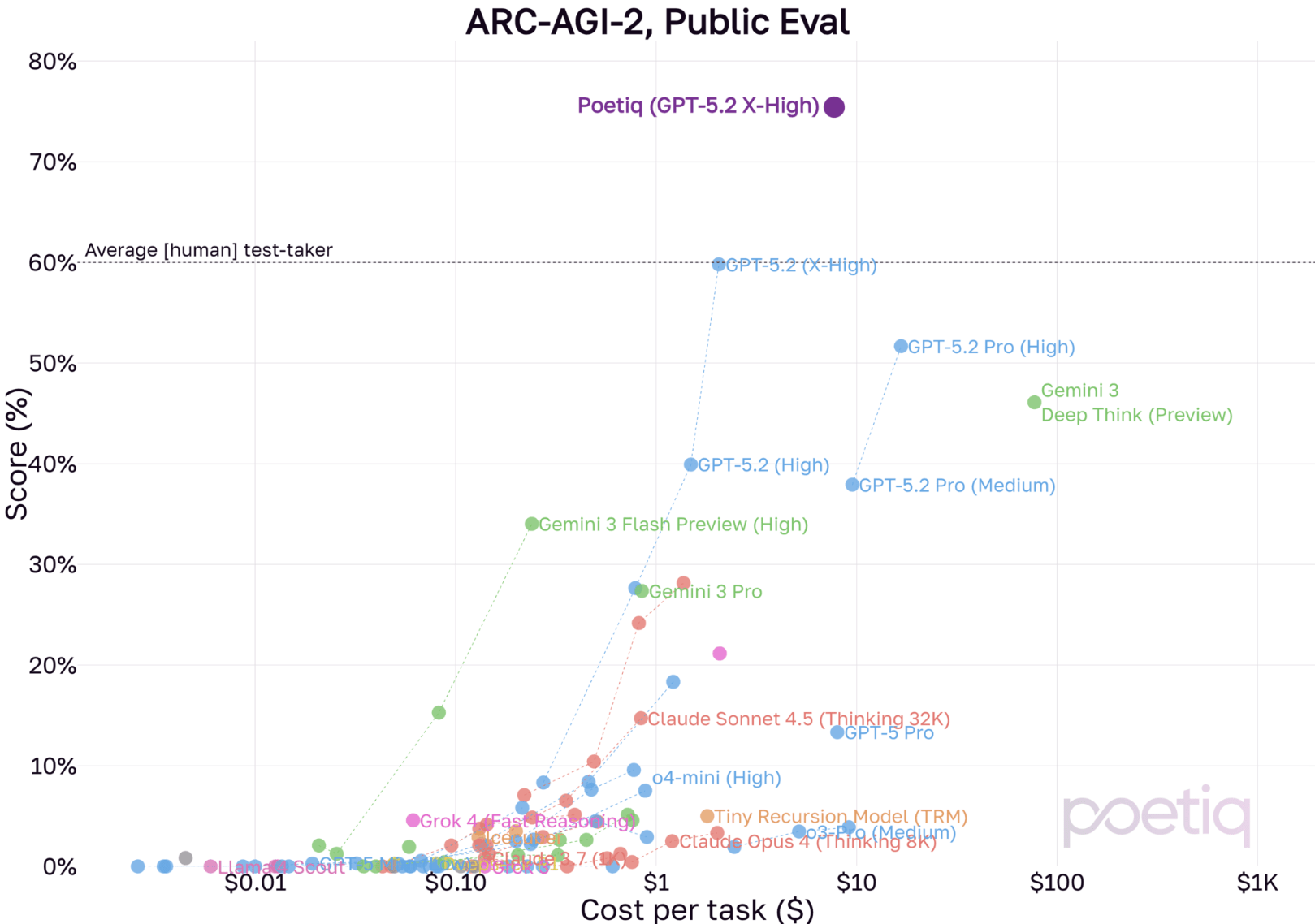
Poetiq hat die Messlatte beim ARC-AGI-2-Benchmark noch weiter nach oben verschoben. Das KI-Start-up erreichte mit OpenAIs GPT-5.2 X-High eine Trefferquote von 75 Prozent auf dem öffentlichen Testdatensatz. Das übertrifft den bisherigen Bestwert (siehe unten) um etwa 15 Prozentpunkte und liegt deutlich über menschlichem Niveau. Die Kosten lagen bei unter 8 Dollar pro Aufgabe, deutlich günstiger als zuvor.
Poetiq erklärt, dass die X-High-Variante wahrscheinlich günstiger pro Aufgabe ist als die High-Variante, weil das Modell schneller zu korrekten Antworten gelangt. Für das bessere Ergebnis waren laut Poetiq Anpassungen am Prompt und am Code, der "Reasoning-Strategie", notwendig. Der Code soll demnächst veröffentlicht werden.
Poetiq betont, dass für GPT-5.2 kein spezielles Training oder modellspezifische Anpassungen vorgenommen wurden. Das Unternehmen spricht von einer bemerkenswerten Verbesserung in kurzer Zeit – sowohl bei der Genauigkeit als auch beim Preis im Vergleich zu früheren Modellen.
Falls sich das Muster früherer Tests bestätigt, könnte GPT-5.2 X-High mit dem Poetiq-System auch bei den offiziellen halbprivaten Tests des ARC Prize deutlich besser abschneiden als alle bisherigen Konfigurationen.
Auf die Kritik, der Ansatz sei zu spezifisch für ARC-AGI und nicht auf reale Anwendungen übertragbar, antwortete Poetiq: Der ARC-AGI-Löser sei zwar spezialisiert, aber das übergeordnete Poetiq-Meta-System dahinter sei durchaus allgemein einsetzbar.
Der Poetiq-Löser leitet das zugrundeliegende Modell (hier GPT-5.2) an, Code zur Lösung jeder einzelnen Aufgabe zu schreiben. Anschließend führt das System den Code aus, prüft ihn auf Korrektheit und korrigiert ihn bei Fehlern. Mehrere unabhängige Durchläufe werden kombiniert, um die Zuverlässigkeit der Endergebnisse zu erhöhen.
Ursprünglicher Artikel vom 29. November:
Lange Zeit galt der ARC-Benchmark als nahezu unüberwindbares Hindernis für KI-Systeme und als Test für fluide Intelligenz. Neue Ergebnisse zeigen jedoch, dass selbst diese Bastion allmählich der unaufhaltsamen Optimierungsmaschinerie der KI-Labore nachgibt.
Der "Abstraction and Reasoning Corpus" (ARC), später ARC‑AGI, sollte einst die Spreu vom Weizen trennen – also zeigen, ob eine KI wirklich Neues lernen kann oder nur statistische Papageienarbeit leistet. Doch nun ereilt ihn das Schicksal vieler Benchmarks zuvor: Er wird von der Wucht neuerer Methoden überrollt.
Jüngstes Beispiel sind Ergebnisse des KI-Unternehmens Poetiq, die darauf hindeuten, dass der ursprüngliche ARC‑AGI‑1‑Benchmark weitgehend gelöst ist. Laut einer Ankündigung von Poetiq saturieren ihre Systeme, die auf großen Modellen von Herstellern wie OpenAI oder Google basieren, die Leistung auf dem ersten Datensatz. Noch bemerkenswerter ist die Behauptung zum deutlich schwierigeren Nachfolger: Auf dem ARC‑AGI‑2‑Datensatz habe das System Ergebnisse erzielt, die die durchschnittliche menschliche Leistung von 60 Prozent übertreffen.
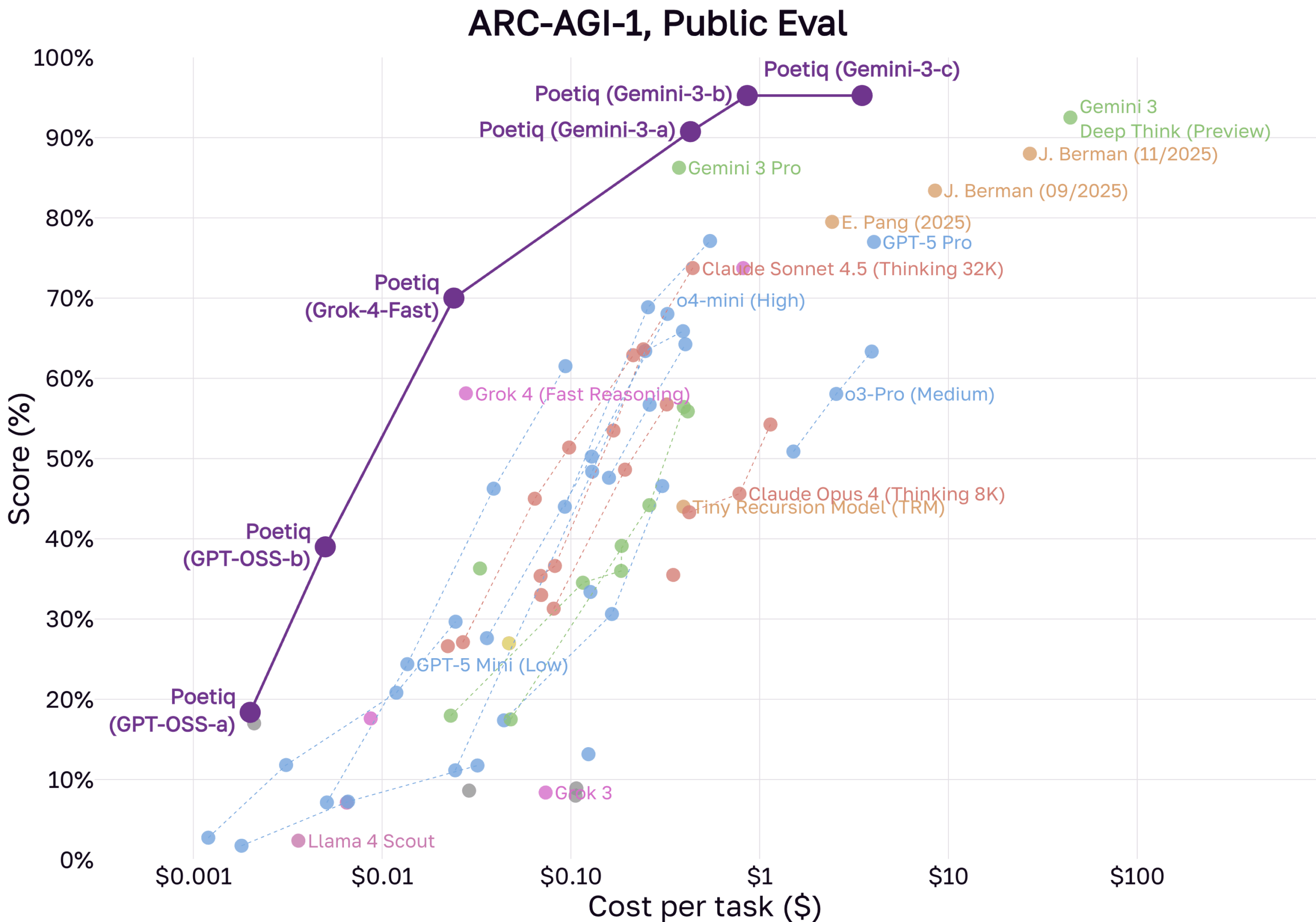
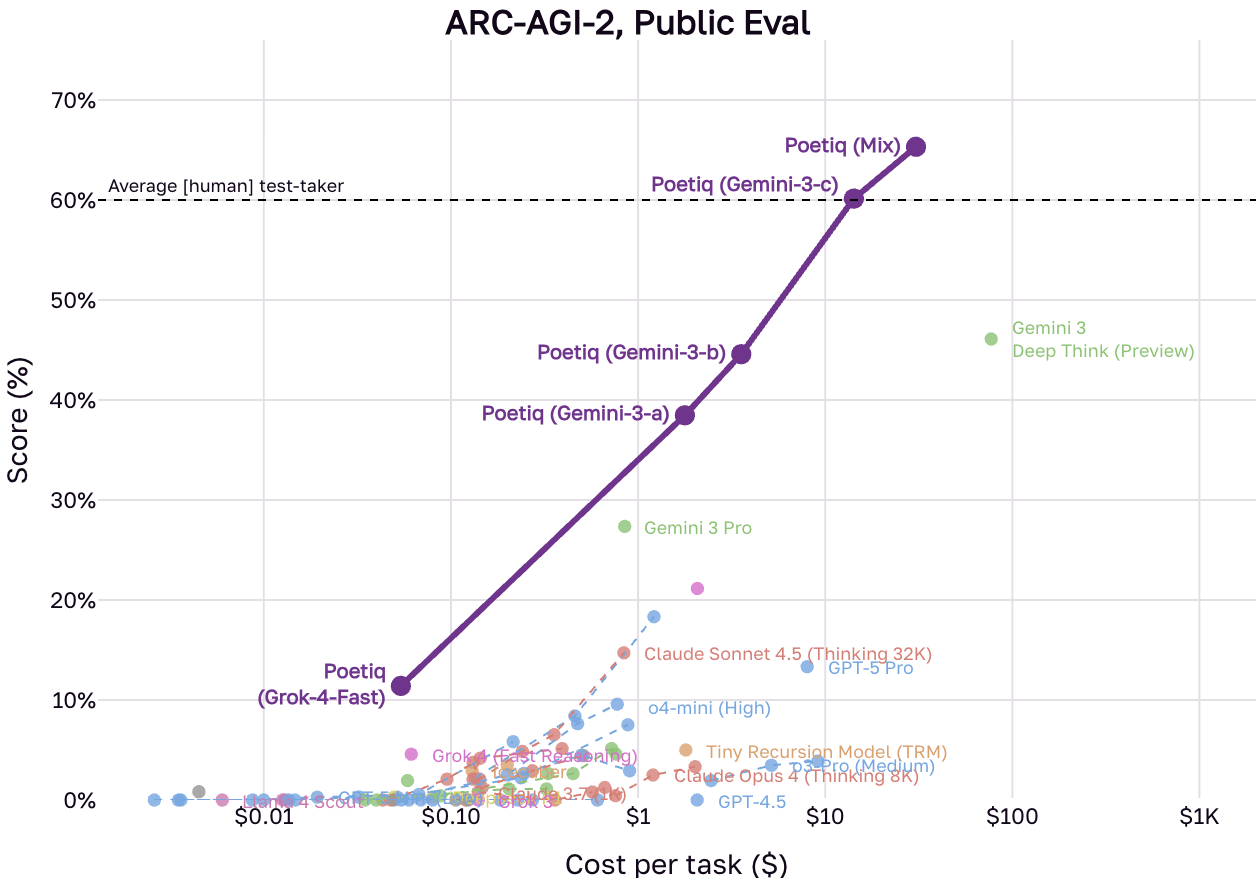
Poetiq setzt nach eigenen Angaben auf eine Kombination aus fortschrittlichen Modellen wie Gemini 3 und GPT‑5.1 sowie Open‑Source‑Modellen, die in eine eigene Architektur eingebettet sind. Das System nutzt laut Poetiq eine iterative Problemlösungsschleife: Es erzeugt Lösungsvorschläge, wertet Feedback aus und verfeinert die Antworten in einem „Selbst‑Audit“-Prozess, bevor es entscheidet, ob die Lösung zufriedenstellend ist.
Das Ende der Unschuld für Benchmarks
Als François Chollet, KI‑Forscher und Schöpfer von Keras, den ARC‑Test 2019 vorstellte, war er als Gegenentwurf zum vorherrschenden Deep‑Learning‑Paradigma gedacht. Statt massenhaft Daten auswendig zu lernen, sollte ein System seine „Skill Acquisition Efficiency“ zeigen – also, wie effizient es neue Fähigkeiten erwirbt.
Jahrelang bissen sich Forschende und Hobby‑Entwickler an den bunten Rasterrätseln die Zähne aus. Die Erfolgsquoten blieben niedrig, während Sprachmodelle in anderen Benchmarks längst Menschen übertrafen. Für manche wurde ARC zum „North Star“ der AGI‑Forschung, für andere zum Makel im Skalierungsversprechen großer Modelle.
Mit dem Aufkommen spezialisierter „Reasoning“-Modelle und Techniken wie Test‑Time Training (TTT) hat sich das Blatt jedoch gewendet. Den sichtbaren Wendepunkt markierte im Dezember 2024 OpenAIs o3‑preview, das im ARC‑AGI‑1 plötzlich über 75 Prozent erreichte. Was einst als Test menschlicher Abstraktionsfähigkeit galt, wird zunehmend zu einem Optimierungsproblem für Reinforcement Learning und Suchverfahren – und die Labore trimmen ihre Systeme zunehmend genau auf die Logiken, die ARC verlangt.
Das zeigt sich auch in der Effizienz: Laut Poetiq erreicht ihr auf dem offenen Modell GPT‑OSS‑120B basierendes System „Poetiq (GPT‑OSS‑b)“ mehr als 40 Prozent Genauigkeit im ARC‑AGI‑1 – für weniger als einen Cent pro Aufgabe. Die Zeiten, in denen ARC‑Lösungen enorme Rechenressourcen verschlangen, scheinen vorbei. Das unterstrich zuletzt auch das „Tiny Recursive Model“, das jedoch – anders als Poetiqs Ansatz – nicht LLM‑basiert war.
Die Falle der öffentlichen Daten
Die Werte beziehen sich zunächst jedoch nur auf die „Public“-Datensätze, nicht auf die „Semi‑Private“-Sets, die ausschließlich ARC vorliegen. Poetiq weist in seiner Analyse selbst darauf hin, dass viele zugrunde liegende LLMs deutliche Leistungseinbußen zeigen, sobald sie vom öffentlichen Evaluierungsset auf das semi‑private Set wechseln.
Der Grund ist naheliegend: Öffentliche Benchmarks landen häufig in den Trainingsdaten großer Modelle – ein Effekt, der als „Data Contamination“ bekannt ist. Echte Generalisierung zeigt sich erst an Aufgaben, die ein Modell garantiert noch nie zuvor gesehen hat. Poetiq erwartet diesen Leistungsrückgang daher auch für die eigenen Systeme auf ARC‑AGI‑1.
Interessanterweise könnte dieser Effekt beim neueren ARC‑AGI‑2 geringer ausfallen. Die Sets seien hier „enger kalibriert“, wie Poetiq schreibt, und das eigene System sei nie mit Aufgaben aus ARC‑AGI‑2 trainiert worden.
Wenn der Maßstab zur Zielscheibe wird
François Chollet hat diesen Wandel in der KI‑Entwicklung aufmerksam verfolgt und kommentiert. Für ihn liegen die jüngsten Erfolge in einem grundlegenden Strategiewechsel.
Chollet bezeichnete die Ergebnisse von Reasoning-Modellen wie o3 als „überraschenden und wichtigen Sprung in den KI‑Fähigkeiten“. Seine Analyse ist eindeutig: Das alte Paradigma, Intelligenz durch immer größere Modelle und mehr Trainingsdaten zu skalieren, stößt bei Aufgaben wie ARC an klare Grenzen. Stattdessen befinden wir uns laut Chollet nun „voll in der Ära der Test‑Time Adaptation“.
Dabei antworten Modelle nicht mehr statisch, sondern passen ihren Zustand zur Laufzeit an. Sie nutzen Techniken wie Programmsynthese oder Chain‑of‑Thought‑Reasoning, um sich für eine konkrete Aufgabe gewissermaßen selbst neu zu konfigurieren. Für Chollet bestätigt dies seine These, dass Intelligenz vor allem ein Anpassungsprozess ist – kein statischer Wissensspeicher.
Er betonte zudem stets, dass das Lösen von ARC nicht automatisch AGI bedeutet, sondern lediglich ein notwendiger Schritt auf dem Weg dorthin ist. Selbst die neuesten Modelle scheitern weiterhin an grundlegenden Aufgaben und zeigen kein tiefes Weltverständnis. Der Benchmark sollte die Forschung lediglich dazu bringen, bessere Systeme zu entwickeln.
Genau das ist eingetreten. Die Industrie hat geliefert – allerdings pragmatischer, als es kognitionswissenschaftliche Puristen wohl erhofft hatten. Statt einer „allgemeinen Intelligenz“ entstanden spezialisierte Reasoning‑Maschinen, die bei Poetiq und anderen mit iterativen Schleifen und Code‑Generierung die Rätsel angehen.
Der Benchmark ARC‑AGI‑1 ist damit de facto „gesättigt“, wie Poetiq schreibt. Und selbst der deutlich härter konzipierte ARC‑AGI‑2, der Systeme eigentlich zu echter Generalisierung zwingen sollte, fällt schneller als erwartet: Poetiqs System wurde nach eigenen Angaben nie mit Aufgaben aus ARC‑AGI‑2 trainiert und übertraf dennoch die menschliche Durchschnittsleistung.
Die Inflation der Herausforderungen
Damit erlebt ARC‑AGI das typische Schicksal vieler Benchmarks: Er wird zu einer weiteren Zeile in den Excel‑Tabellen der Marketingabteilungen. Sobald ein Messwert definiert und ein ausreichender Anreiz geschaffen ist – etwa der Millionen‑Dollar‑Preistopf des ARC Prize für kleine Teams –, wird er so lange optimiert, bis die Zahl stimmt.
Das bedeutet jedoch nicht, dass KI nun „menschlich“ denkt. Es zeigt vielmehr die enorme Anpassungsfähigkeit moderner KI‑Forschung, die nahezu jedes abstrakte Ziel durch eine Kombination aus massiver Rechenleistung, synthetischen Daten und ausgeklügelten Suchverfahren erreichen kann.
ARC‑AGI‑1 – und mutmaßlich auch ARC‑AGI‑2 – haben ihre Aufgabe erfüllt, indem sie den Fokus auf Reasoning und Adaption gelenkt haben. Dass sie jetzt selbst „gelöst“ werden, ist kein Scheitern der Benchmarks, sondern eher ein Beleg ihrer Wirksamkeit als Katalysator technologischer Entwicklung. Ob die Methoden, die diese Fortschritte ermöglichen, tatsächlich einen Schritt hin zu AGI oder zu fluider, menschenähnlicher oder sonstwie transformativer Intelligenz darstellen, wird sich erst in den kommenden Jahren zeigen.
Chollet sieht die Zukunft bereits in ARC‑AGI‑3, das mit interaktiven Umgebungen die „Agency“ – also die Handlungsfähigkeit – von Modellen testen soll.
Poetiq hat Code und Ergebnisse auf GitHub veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.