Googles Open-Source-Modell MedGemma 1.5 versteht dreidimensionale CT- und MRT-Aufnahmen

Kurz & Knapp
- Google veröffentlicht MedGemma 1.5, ein Open-Source-Modell, das erstmals dreidimensionale CT- und MRT-Aufnahmen analysieren kann, indem es alle Schichten eines Scans gleichzeitig verarbeitet.
- Die Genauigkeit bei MRT-Befunden stieg um 14 Prozentpunkte auf 65 Prozent, das neue Spracherkennungsmodell MedASR produziert 82 Prozent weniger Fehler bei medizinischen Diktaten als OpenAIs Whisper large-v3.
- Der Wettbewerb um den Gesundheitsmarkt verschärft sich: OpenAI kaufte kürzlich das Start-up Torch für rund 100 Millionen Dollar, Anthropic stellte Claude for Healthcare vor.
Mit MedGemma 1.5 veröffentlicht Google ein Update seines Open-Source-Modells für medizinische Anwendungen. Erstmals soll damit ein öffentlich verfügbares Sprachmodell in der Lage sein, dreidimensionale CT- und MRT-Aufnahmen zu interpretieren.
Die Gesundheitsbranche übernimmt generative KI derzeit etwa doppelt so schnell wie die Gesamtwirtschaft, berichtet Google Research. Um diese Entwicklung zu unterstützen, stellt das Unternehmen nun MedGemma 1.5 4B vor, eine aktualisierte Version seines Open-Source-Modells für die medizinische Bildinterpretation. Ergänzt wird sie durch MedASR, ein neues Spracherkennungsmodell, das speziell für medizinische Diktate entwickelt wurde.
Das ursprüngliche MedGemma wurde im vergangenen Jahr veröffentlicht und verzeichnete laut Google Millionen von Downloads. Auf Hugging Face entstanden Hunderte Communityvarianten.
Das jetzt veröffentlichte Update erweitert die Fähigkeiten des Modells erheblich: Neben zweidimensionalen Bildern wie Röntgenaufnahmen oder Hautbildern soll MedGemma 1.5 nun auch dreidimensionale Volumendarstellungen von CT- und MRT-Aufnahmen sowie Histopathologie-Ganzobjektträger verarbeiten können.
Entwickler können dem Modell etwa alle Schichten eines CT-Scans auf einmal übergeben, statt nur einzelne Bilder. Das gleiche gilt für Histopathologie: Statt eines einzelnen Ausschnitts einer Gewebeprobe lassen sich mehrere Bereiche gemeinsam analysieren. So kann das Modell Zusammenhänge erkennen, die bei der Betrachtung einzelner Bilder verloren gehen würden. Nach Angaben von Google ist MedGemma 1.5 das erste öffentlich verfügbare Open-Source-Sprachmodell, das solche dreidimensionalen medizinischen Daten verarbeiten kann und gleichzeitig weiterhin normale Bilder und Text versteht.
Deutliche Verbesserungen bei Benchmark-Tests
Die Leistungsverbesserungen gegenüber der Vorgängerversion fallen laut internen Benchmarks von Google teils erheblich aus. Bei der Klassifikation von CT-Befunden stieg die Genauigkeit um drei Prozentpunkte auf 61 Prozent, bei MRT-Befunden um 14 Prozentpunkte auf fast 65 Prozent.
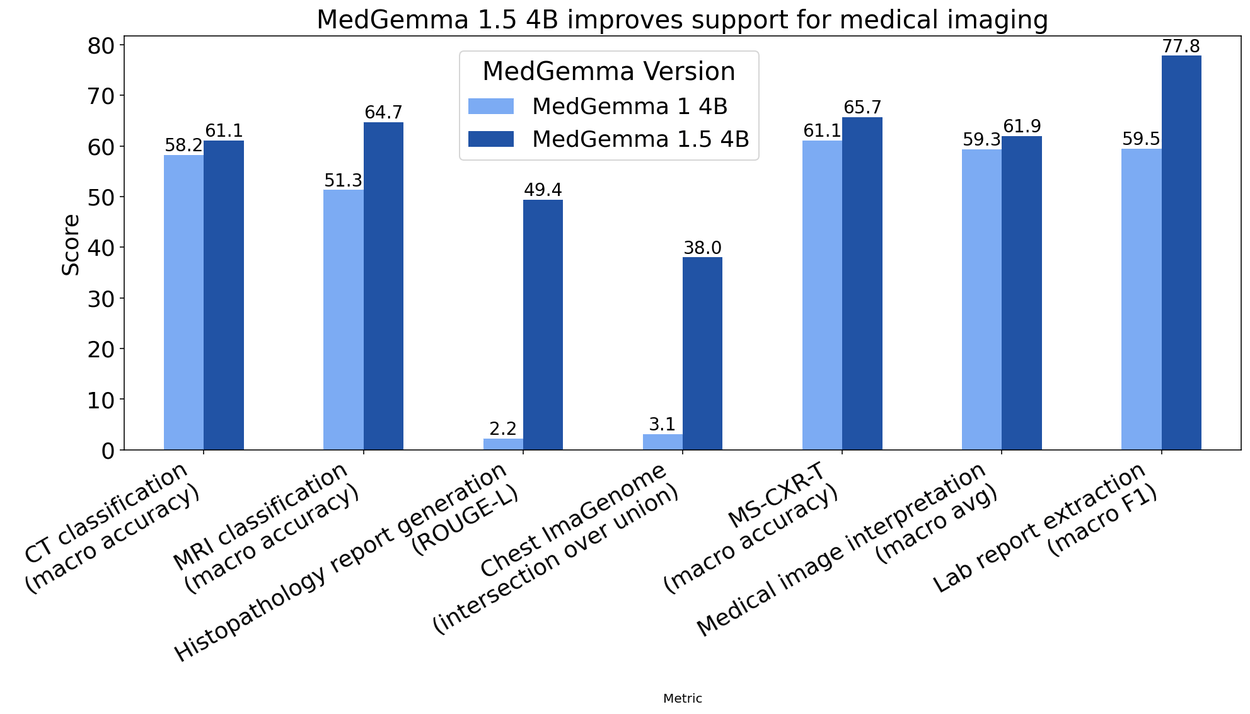
Auch bei Textaufgaben zeigt das Modell Fortschritte. Auf dem MedQA-Benchmark für medizinisches Reasoning erreicht MedGemma 1.5 4B 69 Prozent gegenüber 64 Prozent der Vorgängerversion. Bei der Informationsextraktion aus elektronischen Patientenakten stieg die Genauigkeit von 68 auf 90 Prozent.
Google betont allerdings, dass die Fähigkeiten noch in einem frühen Stadium seien und das Modell unvollkommen bleibe. Entwickler sollen durch Feinabstimmung auf eigenen Daten bessere Ergebnisse erzielen können.
Spracherkennung mit 82 Prozent weniger Fehlern
Parallel veröffentlicht Google MedASR, ein Spracherkennungsmodell, das speziell für medizinisches Vokabular trainiert wurde. Im Vergleich zum generalistischen Modell Whisper large-v3 von OpenAI produziert MedASR laut Google 58 Prozent weniger Fehler bei der Transkription von Röntgen-Diktaten und 82 Prozent weniger Fehler bei allgemeinen medizinischen Diktaten.
Das Modell soll sowohl für die Transkription medizinischer Aufnahmen als auch als natürliche Eingabeschnittstelle für MedGemma dienen. Entwickler könnten so Systeme bauen, bei denen Ärzte per Sprache mit dem KI-Modell interagieren.

Erste Anwendungen existieren bereits: Das malaysische Unternehmen Qmed Asia nutzt MedGemma für eine Konversationsschnittstelle zu den klinischen Behandlungsleitlinien des Landes. Taiwans Nationale Krankenversicherungsverwaltung hat das Modell eingesetzt, um mehr als 30 000 Pathologieberichte für die Analyse von Lungenkrebsoperationen auszuwerten.
Beide Modelle sind kostenlos für Forschung und kommerzielle Nutzung auf Hugging Face und Google Cloud Vertex AI verfügbar. Google weist darauf hin, dass die Modelle als Ausgangspunkt für Entwickler gedacht sind und nicht ohne Validierung und Anpassung für klinische Anwendungen eingesetzt werden sollen. Die Ausgaben seien nicht für direkte Diagnosen oder Behandlungsentscheidungen vorgesehen.
Strenge Auflagen für den klinischen Einsatz
Obwohl MedGemma als Open Source verfügbar ist, unterliegt das Modell den "Health AI Developer Foundations Terms of Use", einer speziellen Lizenz, die über die übliche Apache-2.0-Lizenz hinausgeht. Der Quellcode selbst steht zwar unter Apache 2.0, doch für die Nutzung der Modellgewichte gelten zusätzliche Einschränkungen: Wird MedGemma direkt zur Diagnose oder Behandlung von Patienten eingesetzt, ist dafür eine Zulassung als Medizinprodukt durch die zuständigen Behörden erforderlich.
Wer MedGemma weiterverbreitet oder darauf aufbauende Modelle entwickelt, muss diese Nutzungsbeschränkungen an Dritte weitergeben. Google schließt zudem jegliche Haftung aus und weist ausdrücklich darauf hin, dass das Unternehmen durch die Bereitstellung der Modelle keine medizinische Beratung erteilt. Google behält kein Urheberrecht am Output, aber der Nutzer ist allein verantwortlich für Nutzung und Folgen des Outputs.
KI-Wettlauf um den Gesundheitsmarkt
Erst vor wenigen Tagen kaufte OpenAI das Start-up Torch für rund 100 Millionen Dollar, das verstreute Gesundheitsdaten zu einem "medizinischen Gedächtnis für KI" zusammenführt. Parallel führte OpenAI einen eigenen ChatGPT-Health-Bereich ein und richtet sich mit einem Angebot gezielt an Healthcare-Unternehmen.
Auch Anthropic stellte mit Claude for Healthcare eine HIPAA-konforme Lösung vor, die auf US-Gesundheitsdatenbanken wie Medicare-Daten und PubMed zugreifen kann. Hinter dem Wettlauf steht die Vermutung eines Milliardenmarktes: Hunderte Millionen Chatbot-Konversationen weltweit drehen sich um Gesundheitsthemen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren