Flexiblere KI: Forscher stellen neue Trainingsmethode vor

KI-Forschende trainieren einen KI-Agenten in stetig komplexer werdenden Umgebungen. Der automatisierte Prozess läuft anderen Trainingsansätzen davon.
Beim bestärkenden Lernen lernt ein KI-Agent durch sehr viele Versuche, bestimmte Aufgaben in seiner Umgebung zu erfüllen. Die Lernmethode Künstlicher Intelligenz feierte in den letzten Jahren zahlreiche Erfolge und gilt als mögliche Lösung für Probleme im autonomen Fahren oder der Robotik. Prominente Beispiele sind etwa Deepminds KI-Systeme, die Video- und Brettspiele meistern.
Das Training eines Agenten für die Lösung einer einzigen Aufgabe in einer spezifischen Umgebung ist verhältnismäßig simpel. Ein Agent, der sich bloß in einem Labyrinth zurechtfinden muss, kann etwa den Weg auswendig lernen oder eine simple Strategie entwickeln, die in dieser Umgebung zum Erfolg führt.
In einer fixen Umgebung trainierte Agenten generalisieren jedoch nicht auf andere Umgebungen und scheitern daher schon bei kleinen Veränderungen. Die KI-Forschung setzt daher auf verschiedene Ansätze, um robuste KI-Agenten zu trainieren, die in zahlreichen Umgebungen viele Aufgaben erfüllen können.
Eine naheliegende Methode ist die Randomisierung der im Training gebotenen Umgebungen. So kann ein Roboter in einer Simulation etwa mit sich immer wieder ändernden Oberflächen, Stufen, Lücken oder mehreren Labyrinthen konfrontiert werden.
Flexiblere KI-Agenten: Randomisierung ist nicht genug
In der Praxis reicht eine zufällige Veränderung der Umgebung jedoch nicht aus, um robuste Agenten zu trainieren. KI-Forschende greifen daher auf Methoden mit "adaptiven Kurrikula" zurück, bei denen die Komplexität der Trainingsumgebungen sich an den aktuellen Fähigkeiten des Agenten orientieren. Ein Beispiel dafür ist eine Bauklotz-Simulation von OpenAI, in der ein simulierter Roboterarm einem anderen stetig komplexere Aufgaben stellt.
Solche adaptiven Methoden haben in der Praxis bereits gezeigt, dass sie robustere Agenten in weniger Trainingsschritten erzeugen können als randomisierte Methoden. Da sich bei den adaptiven Methoden die Verteilung der Trainingsumgebungen an die Fähigkeit des Agenten anpassen, gelte diese Methoden als eine Form des "unüberwachten Umgebungsdesigns" (UED), in der eine Art Lehrkraft die Umgebungen selbstständig auswählt und dem Agenten zum Training zuordnet.
ACCEL modifiziert herausfordernde Umgebungen selbstständig
In der Forschungsarbeit "Adversarially Compounding Complexity by Editing Levels" (ACCEL) stellen KI-Forschende der University of Oxford, des University College London, des University College Berkeley, der University Oxford und von Meta AI eine neue UED-Methode für das Training robusterer KI-Agenten.
Die Forschenden lassen Trainingsumgebungen nach dem Zufallsprinzip von einem Generator auswählen und nach ihrer Schwierigkeit beurteilen. Dafür bewertet ACCEL die Differenz zwischen der tatsächlichen Leistung eines Agenten in einer Umgebung und seiner möglichen besten Leistung, dem sogenannten "Regret".
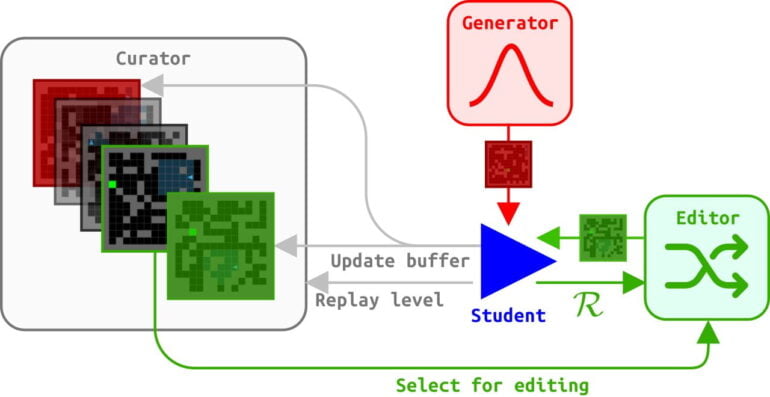
Soweit gleicht ACCEL dem "Prioritized Level Replay" (PRL), einer der aktuell stärksten UED-Methoden. Während PRL jedoch nach jedem Trainingsdurchgang immer wieder neue Trainingsumgebungen per Zufall auswählt, evaluiert ein Kurator in ACCEL die Trainingsergebnisse vor dem nächsten Durchgang.
Umgebungen, die bisher zu schwer für den Agenten waren, werden zufällig minimal modifiziert: In einem Labyrinth werden etwa Wände ausgetauscht oder hinzugefügt, in einer Laufsimulation die Anzahl an Stufen oder Höhenunterschiede verändert.
Die veränderten Umgebungen werden erneut dem Trainingskurrikulum zugeordnet - sofern ihr Regret-Wert auch nach der Modifikation noch hoch ist. ACCEL generiert so ständig neue Umgebungen an der Grenze der Fähigkeiten des Agenten.
ACCEL hängt andere Methoden ab
Im Vergleich mit anderen UED-Methoden trainiert ACCEL konsistent Agenten, die nach dem Training mit schwierigen Umgebungen umgehen können. So findet sich ein trainierter ACCEL-Agent etwa ohne zusätzliches Training in von Menschen entworfenen Labyrinthen zurecht und überträgt seine Fähigkeiten sogar mit Einschränkungen auf Labyrinthe, die deutlich größer als die Trainingsbeispiele sind.
Auch in der BidpedalWalker-Simulation generiert die ACCEL-Methode ein stetig schwerer werdendes Kurrikulum, das sich an den Fähigkeiten des Agenten orientiert. ACCEL schaffe einen hochgradig leistungsfähigen Agenten, der mit anderen UED-Methoden trainierte Agenten bei der Zero-Shot-Übertragung (siehe Labyrinth-Beispiel oben) durchweg übertrifft, so die Autoren. ACCEL erzeugt also fähige Generalisten.
Es sei allerdings wahrscheinlich, dass mit der Entwicklung schwierigerer Umgebungen auch Spezialisten zunehmend an Bedeutung gewinnen werde, die etwa die UED-Methode POET hervorbringt. POET entwickele Agenten-Umwelt-Paare gemeinsam und suche nach spezialisierten Strategien für die Lösung bestimmter Aufgaben.
ACCEL erstellt komplexer werdende Kurrikula. Am Ende spaziert der Agent davon. | Video: https://accelagent.github.io/
Diese Spezialisten seien möglicherweise effektiver bei der Entdeckung vielfältiger und komplexer Verhaltensweisen - allerdings für den Preis einer potenziellen Überanpassung an ihre jeweiligen Umgebungen: Das Modell lernt einzelne Lösungen auswendig, anstatt zu lernen, Merkmale zu erkennen, die zur Lösung führen. Das Zusammenspiel zwischen Generalisten und Spezialisten sei eine faszinierende offene Frage, so die Autoren.
Weitere Informationen über die UED-Methode und eine interaktive Demo gibt es auf der ACCEL-Projektseite.
Wer mehr über die Herausforderungen des bestärkenden Lernens und über den Unterschied zwischen Spezialisten und Generalisten erfahren will, kann in unseren DEEP MINDS KI-Podcast mit Mitautor Tim Rocktäschel reinschauen und -hören.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.