Alibabas Qwen-Team trainiert KI-Bildverständnis mit automatisch erzeugten Denkaufgaben

Kurz & Knapp
- Vision-Language-Modelle scheitern regelmäßig an Aufgaben, die mehrere aufeinander aufbauende Denkschritte über ein Bild erfordern.
- Ein falsch gezähltes Objekt oder eine verwechselte räumliche Beziehung pflanzt sich durch die gesamte Denkkette fort und führt zu komplett falschen Ergebnissen.
- Das Framework HopChain des Alibaba-Qwen-Teams und der Tsinghua University erzeugt automatisch mehrstufige Bildfragen, bei denen jeder Schritt erneutes genaues Hinschauen erzwingt.
Wenn KI-Modelle über Bilder nachdenken, schaukeln sich kleine Wahrnehmungsfehler über mehrere Denkschritte zu falschen Ergebnissen auf. Das Framework HopChain erzeugt mehrstufige Bildfragen, die dieses Problem gezielt adressieren und 20 von 24 Benchmarks verbessern.
Vision-Language-Modelle (VLMs) schneiden auf vielen Bild-Text-Benchmarks gut ab. Sie scheitern aber regelmäßig an Aufgaben, die mehrere aufeinander aufbauende Denkschritte über ein Bild erfordern. Forschende des Qwen-Teams bei Alibaba und der Tsinghua University haben untersucht, woran das liegt, und stellen mit HopChain ein Framework vor, das gezielt dagegen arbeitet.
Produzieren VLMs lange Antworten mit Zwischenschritten, sogenannte Chain-of-Thought-Antworten, treten laut der Studie verschiedene Fehler auf. Die Modelle zählen Objekte falsch, verwechseln räumliche Beziehungen, halluzinieren Details oder ziehen logisch falsche Schlüsse. Diese Fehler pflanzen sich über die Denkkette fort. Ein falsch erkanntes Detail in einem frühen Schritt zieht eine scheinbar schlüssige, aber letztlich falsche Argumentation nach sich.
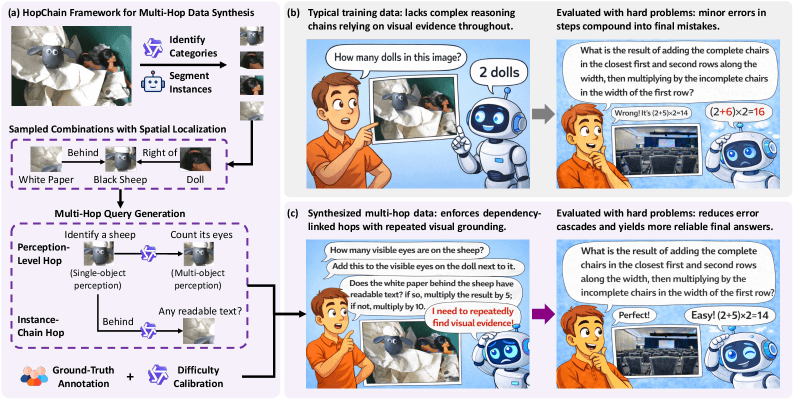
Die bisherigen Trainingsdaten für Reinforcement Learning with Verifiable Rewards (RLVR), bei dem Modelle anhand automatisch überprüfbarer Antworten lernen, enthalten kaum Aufgaben, die durchgehend genaues Hinschauen über mehrere Schritte verlangen.
Falsch gezählte Punkte, falsch gedeutete Parkmanöver
Die Fehleranalyse zeigt anschaulich, wie vielfältig die Probleme sind. In einem Beispiel soll das Modell die Punkte auf mehreren Marienkäfern zählen. Es verzählt sich bei drei von fünf Käfern jeweils um einen Punkt, was sich zu einem deutlich falschen Gesamtergebnis summiert.
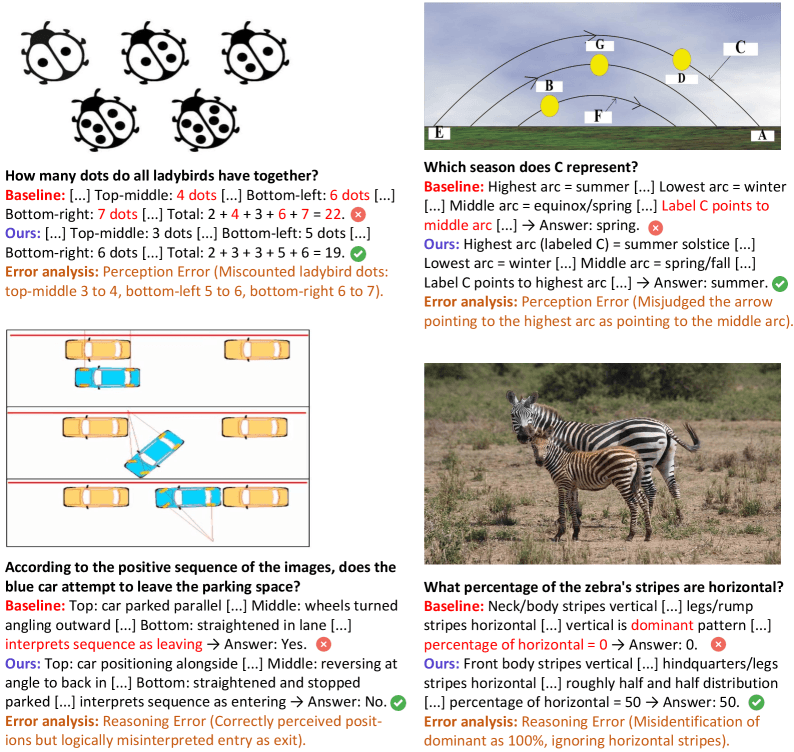
In einem anderen Fall erkennt das Modell die Positionen eines einparkenden Autos in einer Bildsequenz korrekt, interpretiert die Bewegung aber als Ausparken. Ein drittes Beispiel zeigt, wie das Modell in einem astronomischen Diagramm einen Pfeil dem falschen Bogen zuordnet und die falsche Jahreszeit ableitet.
Die Beispiele decken Fotos, Diagramme und wissenschaftliche Abbildungen ab, teilen aber dieselbe Struktur: Ein fehlerhafter Zwischenschritt wird von allen nachfolgenden Schritten übernommen.
Mehrstufige Bildfragen erzwingen wiederholtes Hinschauen
HopChain erzeugt automatisch Bildfragen, bei denen jeder Schritt auf den Ergebnissen vorheriger Schritte aufbaut und erneutes genaues Betrachten des Bildes erfordert. Die Forschenden bauen zwei Arten von Verknüpfungen ein: Zum einen wechselt die Aufgabe zwischen Einzelobjekt-Erkennung, etwa Textlesen oder Farbbestimmung, und dem Vergleich mehrerer Objekte, etwa Größenverhältnisse oder räumliche Anordnungen. Zum anderen folgt die Frage einer Abhängigkeitskette zwischen Objekten, bei der das nächste relevante Objekt nur über die zuvor identifizierten gefunden werden kann.
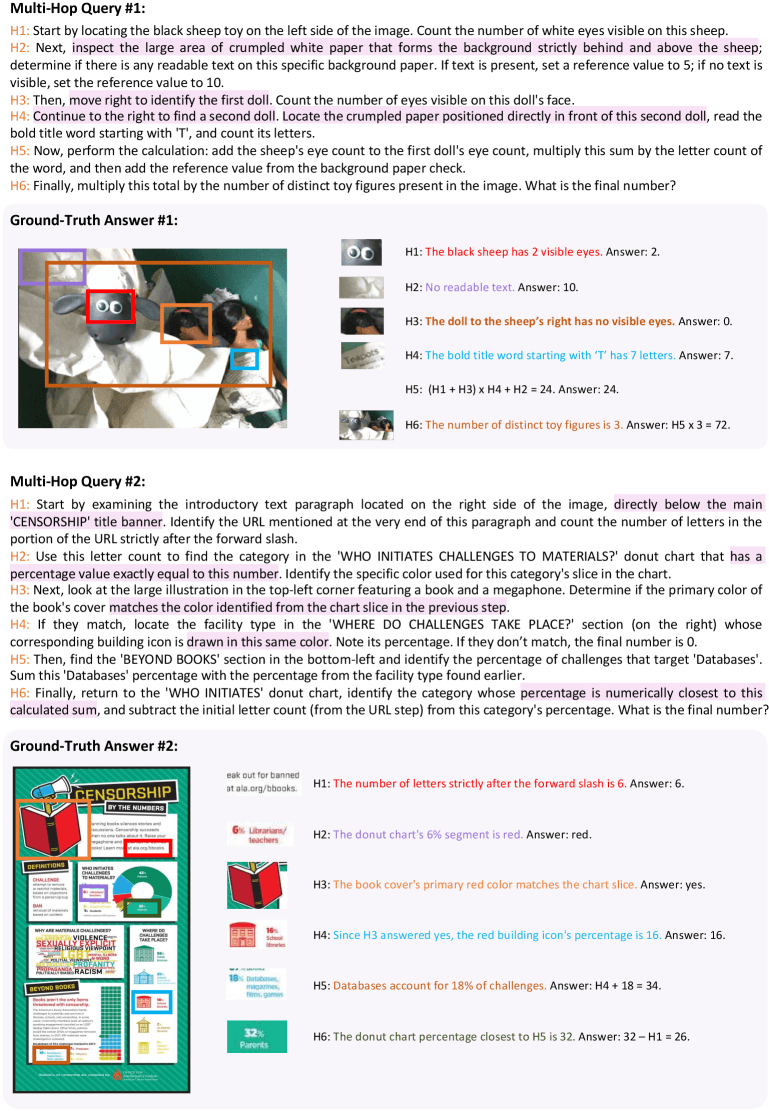
Jede Frage endet in einer eindeutigen Zahl, die sich automatisch überprüfen lässt. Ein Beispiel aus dem Paper verdeutlicht die Komplexität: Eine Frage verlangt zunächst, die Augen eines Spielzeugschafs zu zählen, dann zu prüfen, ob auf dem Hintergrundpapier Text steht.
Anschließend soll das Modell die Augen einer benachbarten Puppe zählen, ein Wort auf einem Papier vor einer zweiten Puppe lesen und dessen Buchstaben zählen, mehrere Rechenschritte durchführen und das Ergebnis mit der Gesamtzahl der Spielfiguren multiplizieren. Die korrekte Antwort: 72.
Vier Stufen mit menschlicher Qualitätskontrolle
Die Datenerzeugung läuft in vier Stufen ab. Zunächst identifiziert das Sprachmodell Qwen3-VL-235B-A22B-Thinking Objektkategorien in einem Bild. Dann lokalisiert Metas Segmentierungsmodell SAM3 einzelne Instanzen dieser Kategorien.
Im dritten Schritt generiert das Sprachmodell mehrstufige Bildfragen über Kombinationen von drei bis sechs Objekten. Im vierten Schritt lösen vier menschliche Annotatoren jede Frage unabhängig voneinander.
Nur Fragen, bei denen alle vier zur selben Antwort gelangen, werden behalten. Zusätzlich werden Fragen aussortiert, die ein schwächeres Modell problemlos löst. Pro Modell entstehen so etwa 60 000 bis 80 000 Trainingsbeispiele.
Verbesserungen bei 20 von 24 Benchmarks
Die Forschenden trainieren zwei Modelle mit diesem Ansatz: Qwen3.5-35B-A3B und Qwen3.5-397B-A17B. Verglichen wird RLVR nur mit den bisherigen Trainingsdaten gegen RLVR mit den bisherigen Daten plus den HopChain-Fragen, evaluiert über 24 Benchmarks in vier Kategorien: STEM und Rätsel, allgemeines Bildverständnis, Texterkennung und Dokumentenverständnis sowie Videoverständnis.
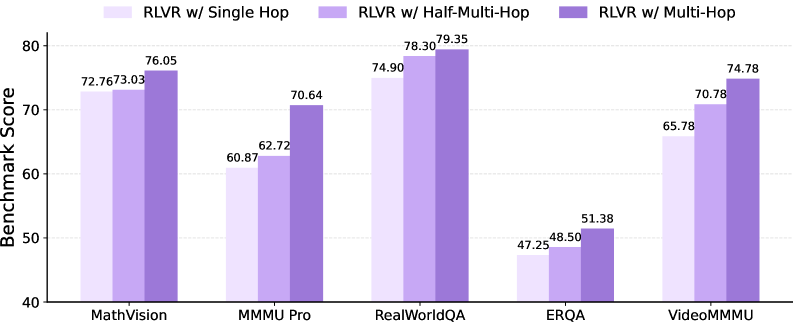
Bei beiden Modellgrößen verbessern die HopChain-Daten 20 von 24 Benchmarks. Beim kleineren Modell steigt etwa der EMMA-Score von 53 auf 58 und der CharXiv-Score von 69 auf 73,1. Beim größeren Modell klettert BabyVision von 28,61 auf 32,22 und ZeroBench verdoppelt sich von 4 auf 8. Die erzeugten Fragen sind dabei nicht auf bestimmte Benchmarks zugeschnitten, was die Forschenden als Beleg für echte Generalisierung werten.
Obwohl die Trainingsdaten ausschließlich aus Bildern stammen, verbessern sich bei beiden Modellen fünf von sechs Video-Benchmarks. Das deutet darauf hin, dass die trainierten Fähigkeiten über die Bilddomäne hinaus übertragbar sind.
Vollständige Fragenketten sind entscheidend
Eine Ablationsstudie belegt, dass die vollständige Verkettung der Fragen wichtig ist. Werden die Fragen auf ihren letzten Einzelschritt reduziert, sinkt der Durchschnittswert über fünf repräsentative Benchmarks von 70,4 auf 64,3. Behält man nur die zweite Hälfte der Kette, liegt er bei 66,7.
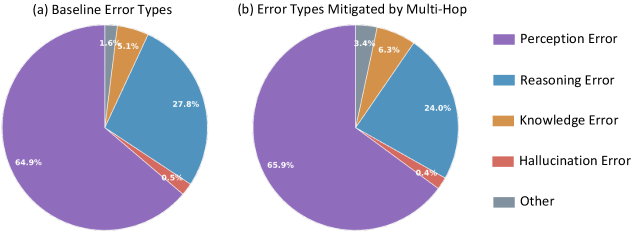
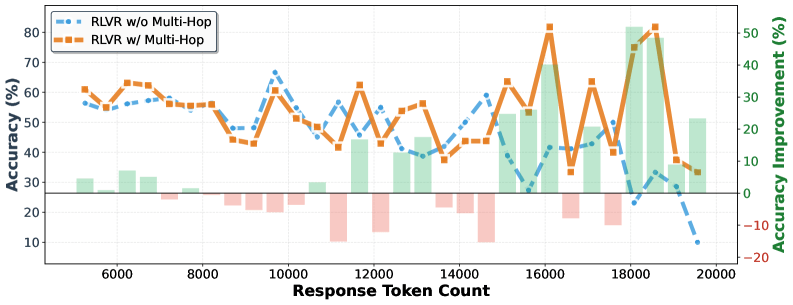
Laut der Analyse wachsen die Vorteile mit zunehmender Länge der Denkkette. Im Bereich besonders langer Antworten übersteigen die Genauigkeitsgewinne beim größeren Modell 50 Punkte. Die Fehlertypenanalyse zeigt zudem, dass die HopChain-Daten das Modell breit verbessern: bei Wahrnehmungs-, Logik-, Wissens- und Halluzinationsfehlern gleichermaßen. Die Verteilung der korrigierten Fehler ähnelt dem ursprünglichen Fehlerprofil.
Als Einschränkung nennen die Autoren, dass die Pipeline voraussetzt, dass SAM3 Objekte im Bild erkennen kann. Bilder ohne segmentierbare Objekte fallen aus der Datenerzeugung heraus.
Dass visuelle Wahrnehmung eine grundlegende Schwachstelle aktueller Modelle bleibt, zeigte kürzlich auch der WorldVQA-Benchmark von Moonshot AI. Selbst das beste getestete Modell erkannte weniger als die Hälfte der gezeigten Objekte korrekt. Alle Modelle überschätzten dabei systematisch ihre eigene Treffsicherheit.
Überdies zeigt eine Stanford-Analyse, dass Frontier-Modelle 70 bis 80 Prozent ihrer Bild-Benchmark-Ergebnisse erreichen, ohne jemals ein Bild gesehen zu haben – und dabei selbstbewusst visuelle Details beschreiben, die gar nicht existieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren