Offener KI-Web-Agent MolmoWeb bedient Websites allein anhand von Bildschirmfotos
Kurz & Knapp
- Das Allen Institute for AI veröffentlicht mit MolmoWeb einen vollständig offenen Web-Agenten, der Websites ausschließlich anhand von Screenshots bedient, ohne auf Quellcode oder Seitenstruktur zuzugreifen.
- Das Training stützt sich auf einen der größten öffentlichen Datensätze seiner Art, bestehend aus menschlichen Browsing-Aufzeichnungen, automatisch erzeugten Durchläufen und Millionen von Screenshot-Frage-Antwort-Paaren.
- Trotz seiner kompakten Größe übertrifft MolmoWeb das bisher beste offene Modell auf allen getesteten Benchmarks und kommt nah an die Leistung proprietärer Systeme von OpenAI heran. Trainingsdaten, Modellgewichte und Werkzeuge sind frei verfügbar.
Das Forschungsteam hinter Molmo veröffentlicht einen Web-Agenten, der Websites allein anhand von Bildschirmfotos bedient. Die kompakten Modelle übertreffen dabei teilweise größere proprietäre Systeme.
Wer heute einen KI-Agenten will, der eigenständig im Browser Flüge sucht, Formulare ausfüllt oder Produktlisten durchforstet, ist auf geschlossene Systeme angewiesen. Die leistungsfähigsten Web-Agenten stammen von Unternehmen, die weder ihre Trainingsdaten noch ihre Methoden offenlegen.
Das Allen Institute for AI (AI2) will das ändern und veröffentlicht mit MolmoWeb einen vollständig offenen Web-Agenten in zwei Größen mit 4 und 8 Milliarden Parametern, zusammen mit sämtlichen Trainingsdaten, Modellgewichten und Evaluierungswerkzeugen.
"Web-Agenten befinden sich heute dort, wo große Sprachmodelle vor OLMo waren", schreibt das Team in seiner Ankündigung. Die Open-Source-Gemeinschaft brauche ein offenes Fundament.
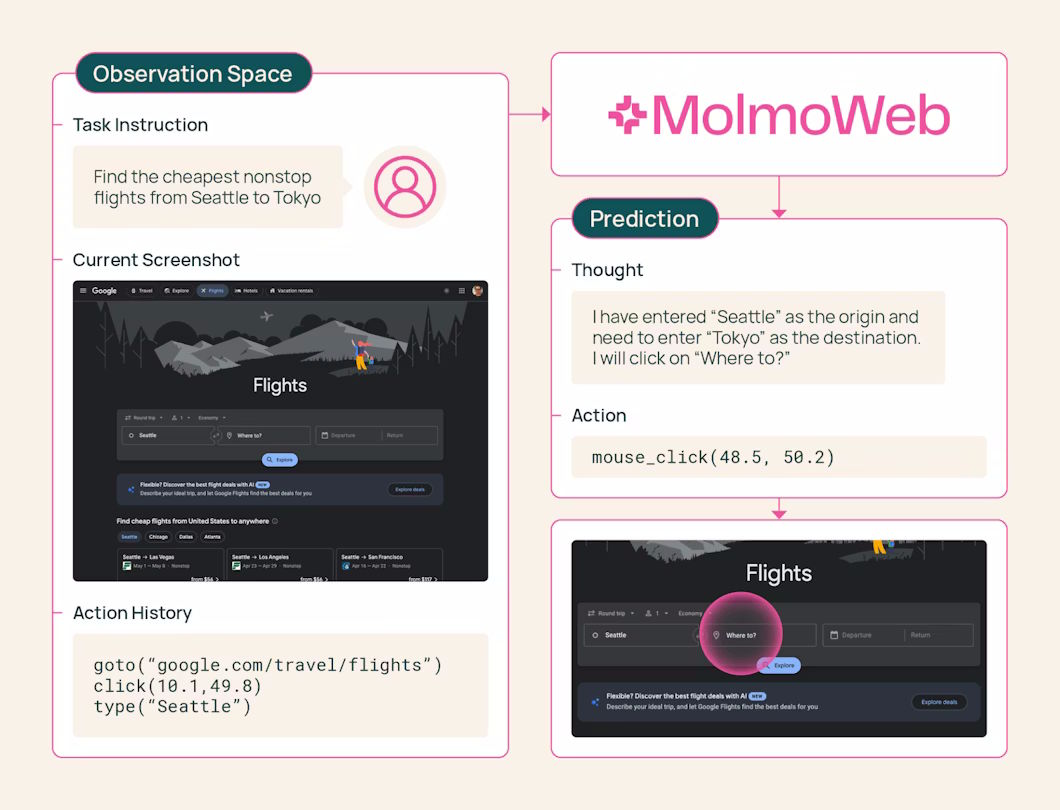
MolmoWeb soll genau das liefern, und zwar ohne dabei das Wissen proprietärer Systeme zu distillieren. Stattdessen speist sich das Training aus einer eigenen Mischung menschlicher Demonstrationen und automatisch erzeugter Browsing-Durchläufe. Trainiert wurde ausschließlich mit überwachtem Feintuning auf 64 H100-GPUs, ohne Reinforcement Learning. Als Basis dient die Molmo2-Architektur mit Qwen3 als Sprachmodell und SigLIP2 als Vision-Encoder.
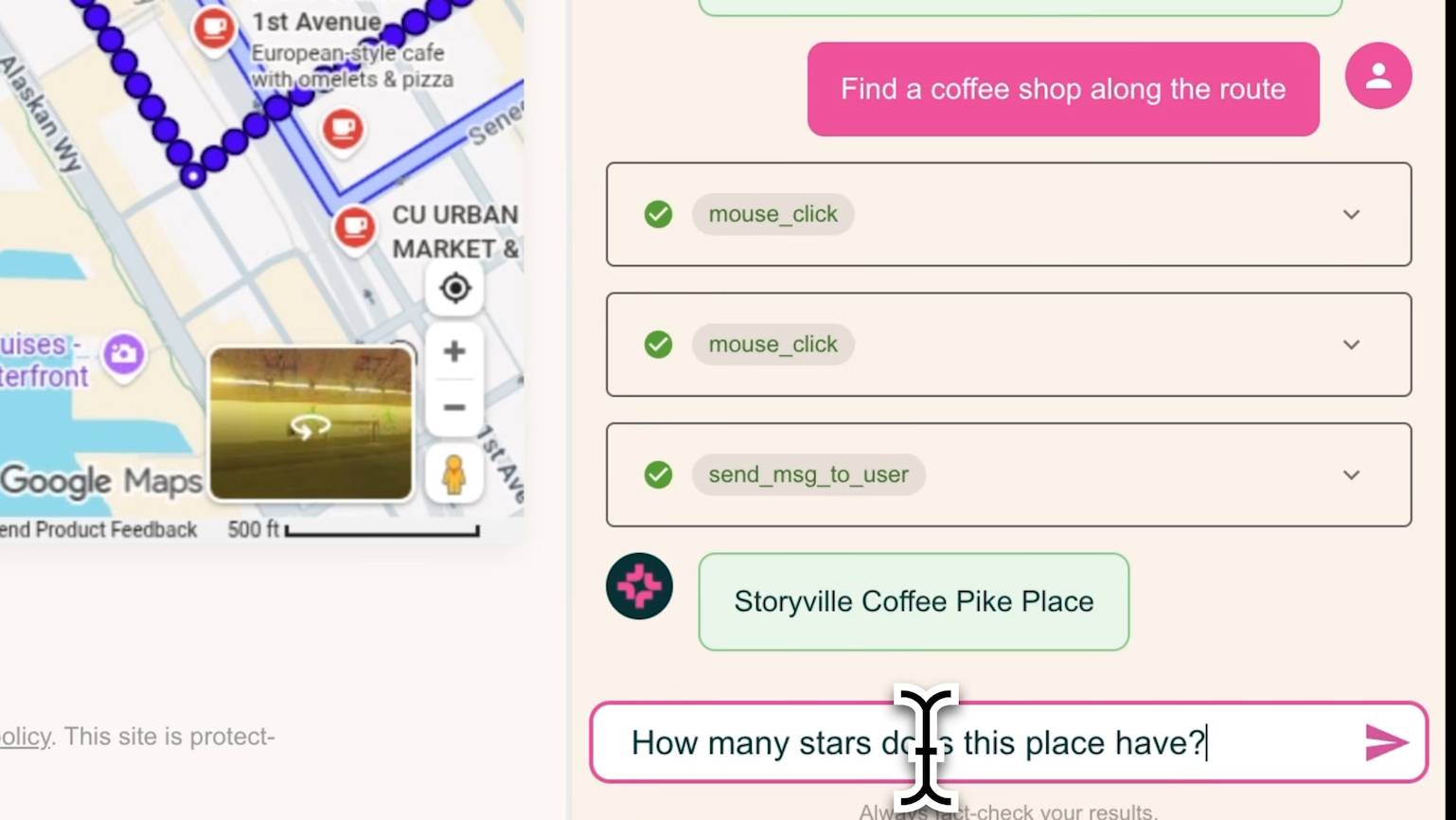
Der Agent sieht, was der Nutzer sieht
Der Agent bekommt ein Bildschirmfoto der aktuellen Browseransicht, formuliert einen kurzen Gedanken darüber, was als Nächstes zu tun ist, und führt dann eine Aktion aus: Klicken, tippen, scrollen, Tabs wechseln oder eine URL aufrufen. Danach macht er ein neues Foto und beginnt von vorn.
MolmoWeb liest dabei keinen Quellcode der Webseite und greift nicht auf die technische Seitenstruktur zu. Es arbeitet ausschließlich mit dem, was auch ein Mensch auf dem Bildschirm sehen würde. Das macht den Agenten laut den Entwicklern robuster, weil sich das Aussehen einer Website seltener ändert als ihr zugrundeliegender Code. Außerdem lässt sich so leichter nachvollziehen, warum der Agent eine bestimmte Entscheidung trifft.
Der größte öffentliche Datensatz seiner Art
Die eigentliche Neuerung dürfte weniger das Modell selbst sein als der dazugehörige Trainingsdatensatz namens MolmoWebMix. Denn das Hauptproblem beim Bau offener Web-Agenten war bisher schlicht der Mangel an geeigneten Daten.
MolmoWebMix setzt sich aus drei Bausteinen zusammen: Zum einen ließen die Forscher Crowdworker reale Browsing-Aufgaben erledigen und zeichneten jeden Klick und jeden Seitenwechsel auf. Daraus entstanden 36.000 vollständige Aufgabendurchläufe auf mehr als 1.100 Websites. Das Team bezeichnet dies als den größten bisher öffentlich verfügbaren Datensatz menschlicher Web-Aufgabenausführung.
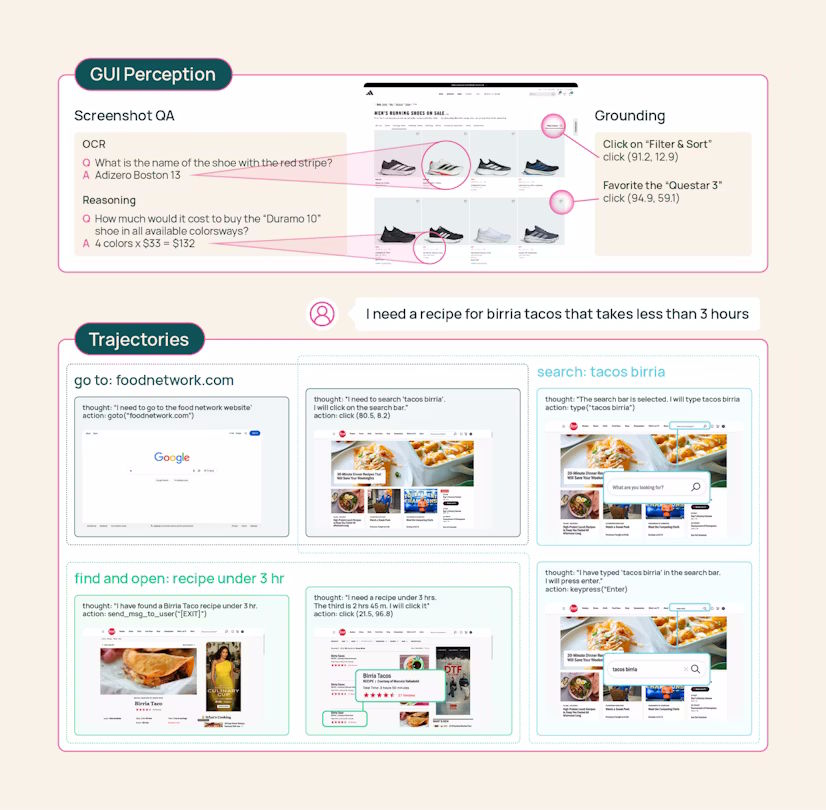
Zum anderen erzeugten automatisierte Agenten zusätzliche Durchläufe, um die Datenmenge über das hinaus zu skalieren, was menschliche Annotation allein leisten kann. Dabei kam unter anderem ein Drei-Rollen-System zum Einsatz: Ein Planer auf Basis von Gemini 2.5 Flash zerlegt Aufgaben in Teilziele, ein Operator führt die einzelnen Browser-Aktionen aus, und ein Verifizierer auf Basis von GPT-4o prüft anhand von Screenshots, ob das jeweilige Teilziel erreicht wurde.
Und schließlich enthält der Datensatz mehr als 2,2 Millionen Screenshot-Frage-Antwort-Paare zum Lesen und Verstehen von Webseiteninhalten. Die Lokalisierung von UI-Elementen wird in einem separaten Grounding-Datensatz mit über sieben Millionen Beispielen trainiert.
Ein kontraintuitives Ergebnis aus dem zugehörigen Paper: Bei identischen Aufgaben lernt MolmoWeb besser aus synthetisch erzeugten Browsing-Durchläufen als aus menschlichen Demonstrationen. Die Forscher erklären das damit, dass Menschen auf unbekannten Websites mehr herumprobieren und Umwege nehmen.
Die automatisierten Agenten hingegen haben Zugriff auf die technische Seitenstruktur und finden direktere Wege, was das Imitationslernen erleichtere. Gleichzeitig zeigen die Datenablationen, dass bereits zehn Prozent des Datensatzes 85 bis 90 Prozent der Endleistung liefern.
Klein schlägt Groß auf mehreren Benchmarks
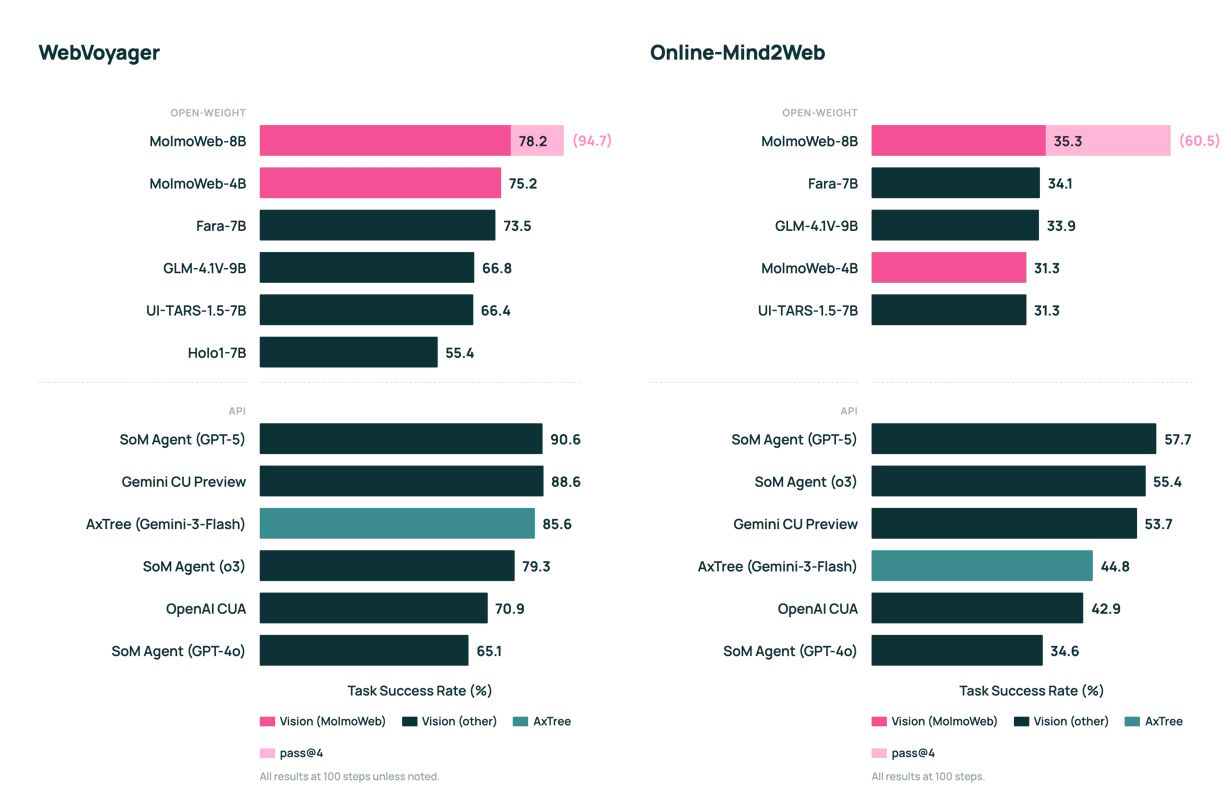
Trotz ihrer überschaubaren Größe erreichen beide MolmoWeb-Modelle nach Angaben der Entwickler Bestwerte unter den offenen Web-Agenten. Auf dem WebVoyager-Benchmark, der die Navigation auf 15 populären Websites wie GitHub oder Google Flights testet, kommt das 8B-Modell auf 78,2 Prozent.
Es übertrifft damit das bislang führende offene Modell Fara-7B auf allen vier getesteten Benchmarks und erreicht annähernd die Leistung von OpenAIs o3 (79,3 Prozent). Auf dem DeepShop-Benchmark liegt MolmoWeb-8B nur sechs Punkte hinter GPT-5.
MolmoWeb schneidet laut den Entwicklern auch besser ab als Agenten, die auf dem weitaus größeren GPT-4o aufbauen und dabei zusätzlich auf annotierte Screenshots und strukturierte Seitendaten zugreifen können. Beim präzisen Lokalisieren von Oberflächenelementen übertrifft ein spezialisiertes 8B-Modell Anthropics Claude 3.7 und OpenAIs CUA auf den ScreenSpot-Benchmarks, allerdings hat sich Ai2 eher ältere proprietäre Modelle als Vergleichswert herausgepickt.
Gegenüber seinem eigenen "Lehrer", einem Gemini-basierten Agenten mit Zugriff auf die technische Seitenstruktur, liegt MolmoWeb allerdings noch fünf Punkte zurück. Das zeigt den Preis des rein visuellen Ansatzes: Wer nur auf Screenshots schaut, muss implizit auch Texterkennung leisten, die ein Agent mit Zugang zur Seitenstruktur geschenkt bekommt.
Ein weiterer Befund: Lässt man den Agenten eine Aufgabe mehrfach unabhängig versuchen und wählt das beste Ergebnis, steigt die Erfolgsrate auf WebVoyager von 78,2 auf 94,7 Prozent. Zusätzliche Rechenzeit bei der Ausführung kann die Zuverlässigkeit also erheblich verbessern.
Kein Login, kein Bezahlen, viele offene Fragen
Die Entwickler benennen die Grenzen ihres Systems offen. Als rein visuelles Modell kann MolmoWeb Text auf Screenshots falsch lesen. Bei mehrdeutigen Anweisungen oder vielen Nebenbedingungen sinkt die Leistung. Aufgaben, die eine Anmeldung oder Finanztransaktionen erfordern, hat das Team aus Sicherheitsgründen bewusst nicht trainiert.
In der gehosteten Demo sind nur bestimmte Websites erlaubt, Eingaben in Passwort- und Kreditkartenfelder werden blockiert, und eine Schnittstelle von Google prüft Anfragen auf problematische Inhalte. Diese Sicherheitsvorkehrungen sind allerdings Teil der Demo-Umgebung, nicht des Modells selbst.
Grundsätzlichere Fragen bleiben unbeantwortet: Wie sollen Web-Agenten mit den Nutzungsbedingungen von Websites umgehen? Wie lässt sich verhindern, dass sie auf illegale Inhalte zugreifen oder irreversible Aktionen ausführen? Das Team argumentiert, dass gerade die vollständige Offenlegung aller Komponenten es mehr Menschen ermögliche, an diesen Problemen zu arbeiten. MolmoWeb steht über Hugging Face und GitHub unter Apache-2.0-Lizenz bereit.
Erst kürzlich verfolgte das akademische Projekt OpenSeeker einen ähnlichen Ansatz für KI-Suchagenten: vollständig offene Daten, Code und Modellgewichte gegen das Datenmonopol großer Konzerne. MolmoWeb erweitert diesen Trend nun auf die Browser-Automatisierung.
Das Allen Institute for AI (Ai2), bekannt für seine Ambition, transparente KI voranzutreiben, musste jüngst einen schmerzhaften Aderlass hinnehmen: Microsoft stellt mehrere führende KI-Forscher ein. Sie sollen in Microsofts neuem Superintelligenz-Team, geleitet vom DeepMind-Mitgründer Mustafa Suleyman, künftig die Modellentwicklung beim Konzern vorantreiben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren