Deepmind will künstliche Wahrnehmung messbar machen
Benchmarks sind zentral für Fortschritte in der KI-Forschung. Mit einem neuen Test will Deepmind die Wahrnehmungsfähigkeiten Künstlicher Intelligenz messbar machen.
Benchmarks erfüllen in der KI-Forschung eine zentrale Rolle: Sie erlauben Forschenden, ihre Forschungsziele zu definieren und ihren Fortschritt auf dem Weg zu diesen Zielen zu messen. Damit formen einflussreiche Benchmarks wie ImageNet oder auch der Turing Test die KI-Forschung, statt sie nur zu messen.
Große Durchbrüche wie AlexNet, ein Deep-Learning-Modell, das im ImageNet-Benchmark das erste Mal andere KI-Ansätze deutlich schlug, wurden durch ihre jeweiligen Benchmarks und damit verbundene Datensätze ermöglicht.
Multimodale KI-Systeme sind auf dem Vormarsch - und benötigen einen neuen Benchmark
Aktuell werden KI-Modelle mit einer ganzen Anzahl von spezialisierten Benchmarks getestet, etwa für die Erkennung von Aktionen in Videos, die Klassifizierung von Audio, der Objektverfolgung oder der Beantwortung von Fragen zu Bildern. Diese Benchmarks haben direkten Einfluss auf Modell-Architekturen und Trainingsmethoden und sind so direkt an vielen KI-Fortschritten beteiligt.
Doch während AlexNet ein überwacht trainiertes KI-Modell für die Objekterkennung festgelegter ImageNet-Kategorien war, werden auf Wahrnehmung spezialisierte multimodale KI-Modelle heute vielfältiger und meist selbst-überwacht mit riesigen Datenmengen trainiert. Modelle wie Perceiver, Flamingo oder BEiT-3 versuchen oft, mehrere Modalitäten gleichzeitig maschinell wahrnehmbar zu machen und dabei vielfältige Wahrnehmungsaufgaben zu meistern.
Auch diese multimodalen Modelle werden aktuell mit verschiedenen spezialisierten Datensätzen verschiedener Benchmarks getestet - ein langsamer, teurer Prozess, der nicht alle Wahrnehmungsfähigkeiten der neuen Modelle vollständig abdeckt.
Damit fehlt ein zentraler Antrieb für den Fortschritt multimodaler KI-Modelle: ein Benchmark mit passendem Datensatz, der generalisierte Wahrnehmungsfähigkeiten testet.
Deepminds "Perception Test" soll zentraler Benchmark für Wahrnehmungsmodelle werden
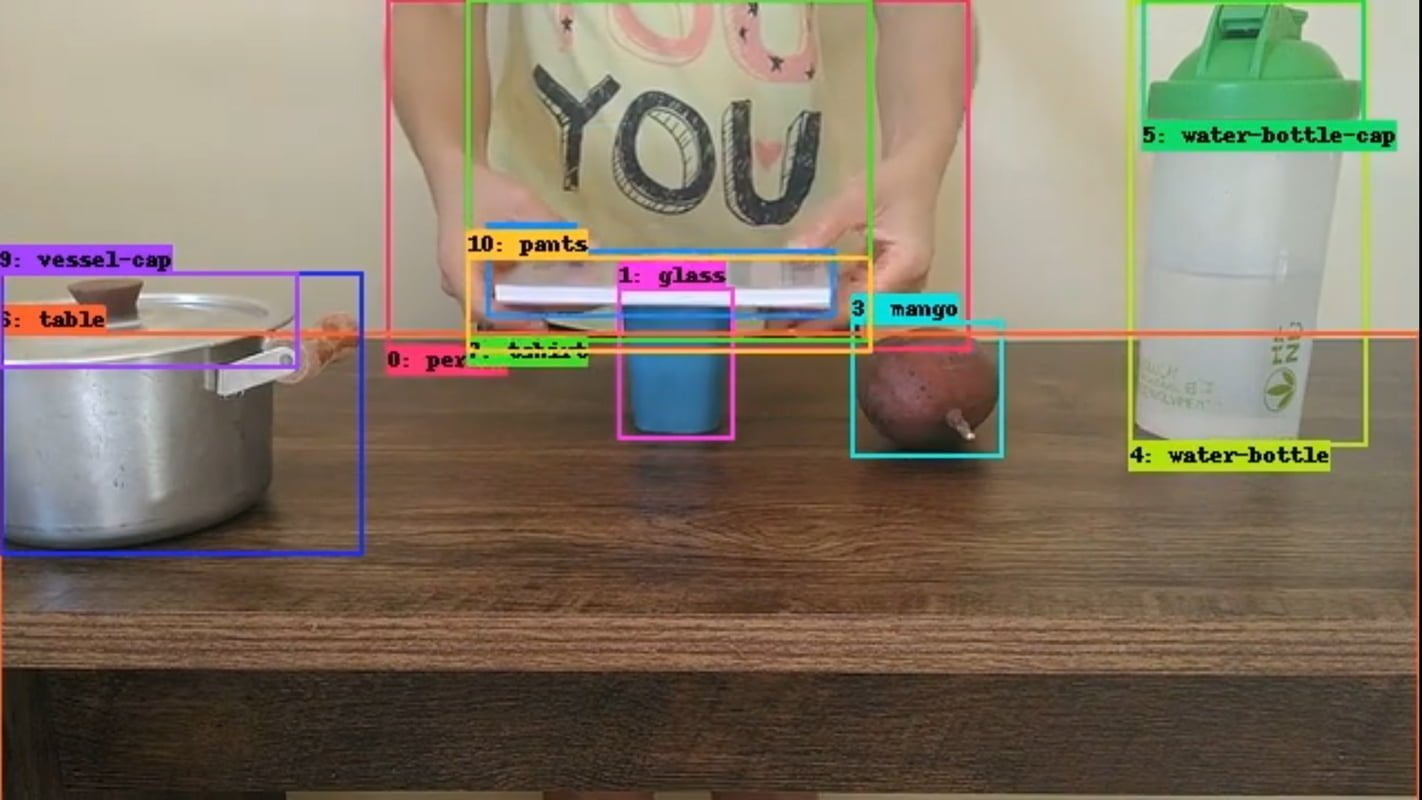
Forschende von Deepmind haben daher den "Perception Test" entwickelt, ein Datensatz und Benchmark von 11.609 gekennzeichneten Videos, die sechs verschiedene Aufgaben umfassen:
- Objektverfolgung: Ein Objekt wird zu Beginn des Videos mit einem Rahmen versehen, das Modell muss es über das gesamte Video hinweg verfolgen (auch durch Verdeckungen hindurch).
- Punktverfolgung: Ein Punkt wird zu Beginn des Videos ausgewählt, das Modell muss den Punkt während des gesamten Videos verfolgen (auch bei Verdeckungen).
- Zeitliche Aktionslokalisierung: Das Modell muss eine vordefinierte Menge von Aktionen zeitlich lokalisieren und klassifizieren.
- Zeitliche Lokalisierung von Geräuschen: Das Modell muss eine vordefinierte Gruppe von Geräuschen zeitlich lokalisieren und klassifizieren.
- Beantwortung von Multiple-Choice-Videofragen: Textfragen zum Video mit jeweils drei Auswahlmöglichkeiten für die Antwort.
- Beantwortung von fundierten Videofragen: Textfragen zum Video, das Modell muss eine oder mehrere Objektspuren zurückgeben.
Als Inspiration nennen die Forschenden Tests aus der Entwicklungspsychologie, sowie synthetische Datensätze wie CATER und CLEVRER. Die Videos des neuen Benchmarks zeigen einfache Spiele oder alltägliche Aktivitäten, in denen die KI-Modelle ihre Aufgaben lösen müssen. Um versteckten Bias vorzubeugen, wurden die Videos zudem von freiwillig Teilnehmenden aus verschiedenen Ländern, ethnischen Zugehörigkeiten und Geschlechtern aufgenommen.
Laut Deepmind benötigen die Modelle vier Fähigkeiten, um im Test zu bestehen:
- Kenntnisse der Semantik: Prüfung von Aspekten wie Aufgabenerfüllung, Erkennung von Objekten, Handlungen oder Geräuschen.
- Physikalisches Verständnis: Kollisionen, Bewegung, Verdeckungen, räumliche Beziehungen.
- Zeitliches Denken oder Gedächtnis: zeitliche Abfolge von Ereignissen, Zählen über die Zeit, Erkennen von Veränderungen in einer Szene.
- Abstraktionsvermögen: Formenvergleich, gleiche/unterschiedliche Begriffe, Mustererkennung.
Deepmind betreibt eigenen Testserver für Vergleiche
Das Unternehmen geht davon aus, dass am Benchmark teilnehmende KI-Modelle bereits mit externen Datensätzen und Aufgaben trainiert sein werden. Der Perception Test umfasst daher ein kleines Fine-Tuning-Set von etwa 20 Prozent der verfügbaren Videos.
Die restlichen 80 Prozent der Videos sind in einen öffentlich verfügbaren Teil für das Benchmarking, sowie einen zurückgehaltenen Teil aufgeteilt, bei dem die Leistung nur über Deepminds eigenen Evaluierungs-Server bewertet werden kann.
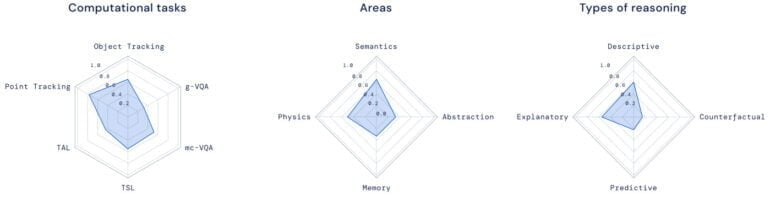
Die Ergebnisse der Modelle werden in Radarflächen und über verschiedene Dimensionen dargestellt, um die Stärken und Schwächen der Modelle deutlicher darzustellen. Ein ideales Modell würde auf allen Radarflächen und in allen Dimensionen die höchste Punktzahl erreichen.
Deepmind hofft, dass der Perception Test weitere Forschung zu generalisierenden Wahrnehmungsmodellen inspiriert und anleitet. In Zukunft will das Team mit der Forschungsgemeinschaft den Benchmark weiter verbessern.
Der Perception Test Benchmark ist auf Github öffentlich zugänglich und weitere Details sind im "Perception Test"-Paper zu finden. Ein Leaderboard und ein Challenge-Server sollen ebenfalls bald verfügbar sein.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.