Feintuning mit Instruktionen: Google Brain verbessert große Sprachmodelle

Google Brain zeigt, dass große Sprachmodelle vom Feintuning mit Instruktionsdatensätzen profitieren.
Beim sogenannten "Finetuning" werden vortrainierte große Sprachmodelle mit weiteren Daten trainiert, um diese etwa auf bestimmte Anwendungsszenarien zu spezialisieren. Eine Forschungsgruppe von Google zeigt jetzt, dass das Feintuning mit Instruktionen die Leistung großer Sprachmodelle für viele Aufgaben verbessern kann.
Finetuning mit 1.836 Sprachaufgaben
Der Feintuning-Ansatz mit Instruktionen selbst ist nicht neu. Das Google-Brain-Team testete insbesondere die Skalierung der Methode und trainierte das eigene große Sprachmodell PaLM, U-PaLM und das Open-Source-Modell T5 mit insgesamt 1.836 Instruktionen nach.
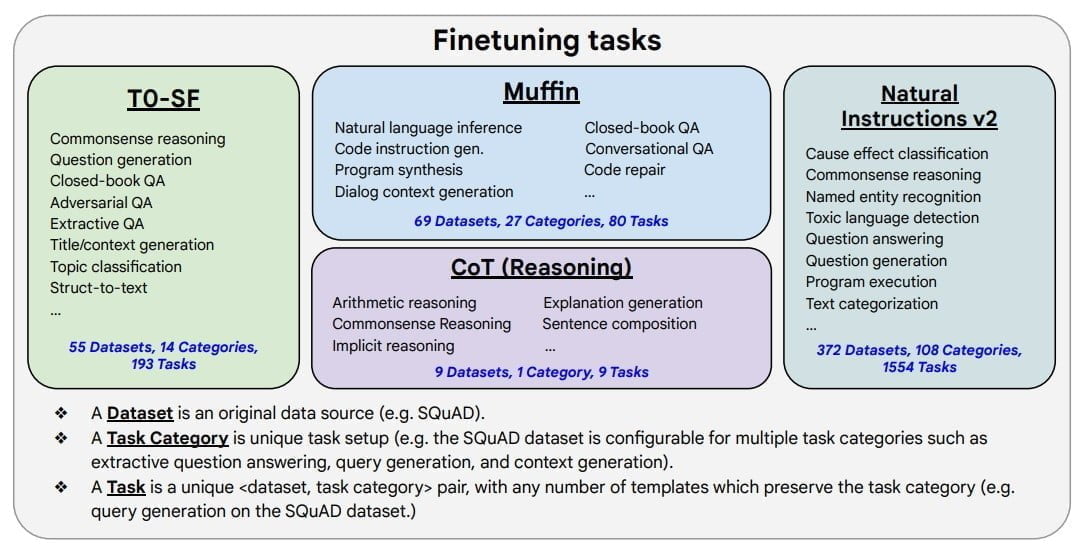
Der größte Teil der Aufgaben stammt aus dem Natural Instructions v2-Datensatz, der etwa Instruktionen zum Commonsense Reasoning beinhaltet. Auf letzteres zielt laut des Forschungsteams auch ein Feintuning mit Beispielen zum sogenannten Chain-of-Thought-Reasoning ein.
Mit Chain-of-thought-Prompts wird die KI aufgefordert, Sprachaufgaben Schritt für Schritt zu lösen und dabei jeden Schritt zu dokumentieren. Das Training mit nur neun CoT-Datensätzen sorgte für eine signifikante Verbesserung bei dieser Fähigkeit im Vergleich zu früheren FLAN-Modellen.
Zudem wird das Prompting vereinfacht, da das FLAN-Modell kein CoT-Beispiel im Prompt benötigt. Die Aufforderung zur Begründung genügt.
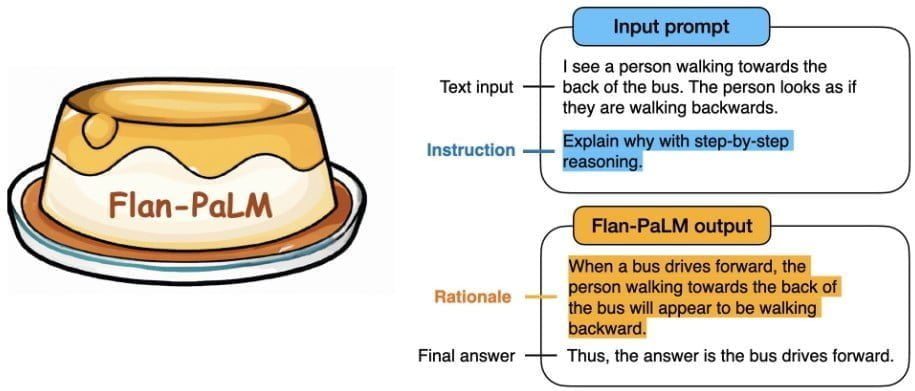
Insgesamt berichtet das Forschungsteam daher von einer "dramatischen Verbesserung" bei der Bedienung ("Prompting") und beim mehrstufigen Schlussfolgern. PaLM- und T5-Modelle profitieren in gängigen Benchmarks unabhängig ihrer Größe vom Feintuning mit Instruktionen und schlagen ohne Ausnahme Non-Flan-Modelle.
To show the generality of our method we train T5 (encoder-decoder trained with span-corruption), PaLM (decoder-only trained with next-token prediction) and U-PaLM (mixture of denoisers), covering a wide range of sizes (80M to 540B).
ALL models benefit significantly! pic.twitter.com/KYRvbiJf4e
— Hyung Won Chung (@hwchung27) October 21, 2022
In einer ersten Evaluation mit 20 menschlichen Tester:innen bewerteten diese die Nutzbarkeit des Flan-PaLM-Modells in knapp 80 Prozent der Fälle besser als die des Non-Flan-PaLM-Modells, etwa in Punkten wie Kreativität, kontextuellen und insbesondere komplexen Begründungen.
Feintuning mit Instruktionsdaten skaliert am Anfang stark
Die Skalierung der Performance des Sprachmodells durch das Instruktionsdaten-Training nimmt allerdings bei größeren Datenmengen signifikant ab. So gibt es einen deutlichen Sprung in der Performance zwischen Modellen ohne Feintuning und mit 282 Aufgaben feingetunten Modellen. Zwischen letztgenannten und dem 1.836-Aufgaben-Modell fällt der Unterschied allerdings geringfügig aus. Generell skaliert das Feintuning entlang der Modellgröße.
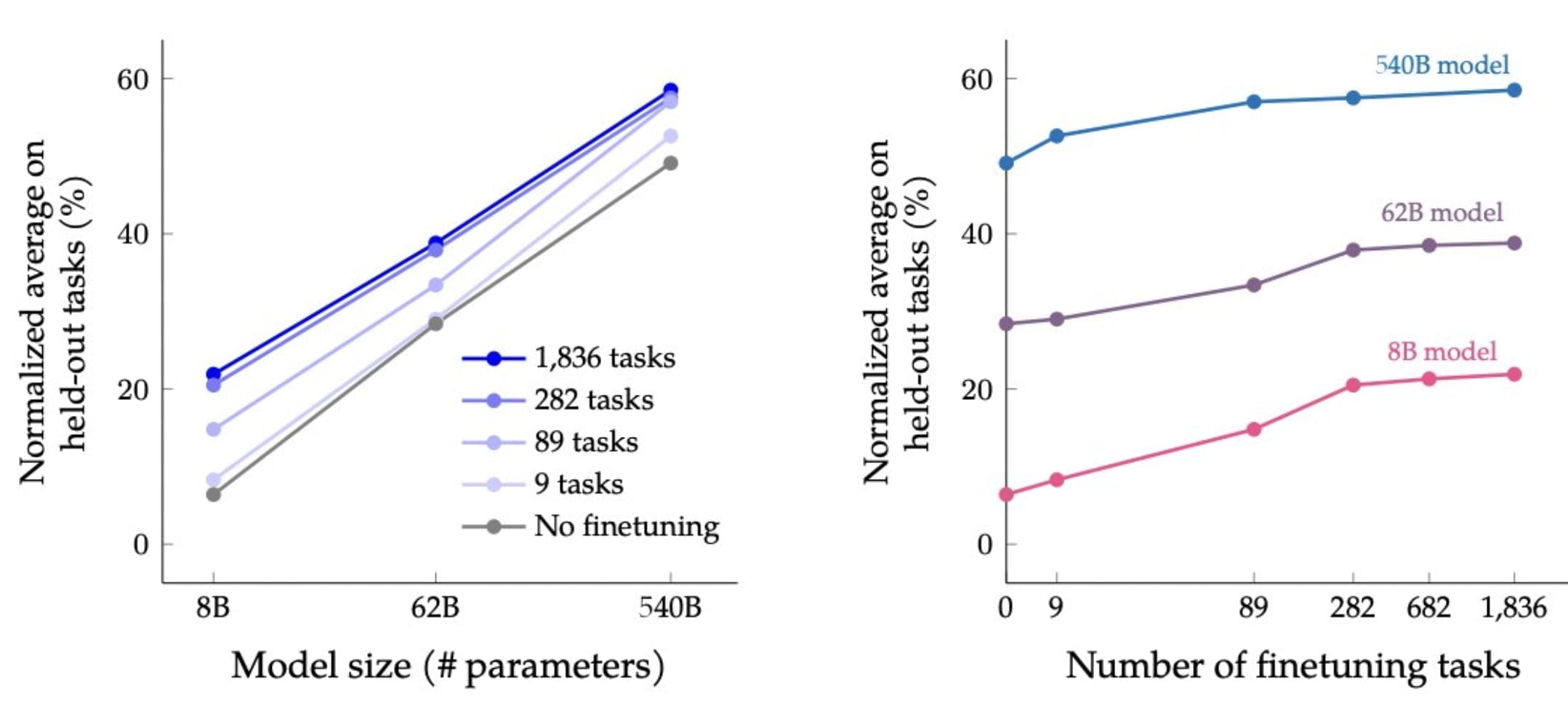
Flan-PaLM erreicht bei mehreren Benchmarks die beste Leistung, z. B. 75,2 % bei five-shot MMLU. Flan-PaLM hat auch eine verbesserte Benutzerfreundlichkeit - zum Beispiel kann es Zero-Shot-Reasoning ohne Prompt-Engineering- oder Few-Shot-Beispiele durchführen. Darüber hinaus zeigen wir, dass die Feinabstimmung der Prompts mit einer Reihe von Modellgrößen, Architekturen und Pretraining-Zielen kompatibel ist.
Fazit im Paper
Das Forschungsteam veröffentlicht das Flan-T5-Modell als Open Source bei Github. Eine Vergleichsdemo zwischen Flan-T5 und Vanilla T5 ist bei Hugging Face verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.