Sparsification: Graphcore und Aleph Alpha zeigen schlankes KI-Sprachmodell

Die europäischen KI-Unternehmen Graphcore und Aleph Alpha zeigen ein erstes Ergebnis ihrer Kooperation: ein um 80 Prozent schlankeres Sprachmodell.
Große Sprachmodelle wie OpenAIs GPT-3 oder Googles PaLM haben weit über hundert Milliarden Parameter. Trotz neuer Erkenntnisse zur Rolle von Trainingsdaten in Deepminds Chinchilla sind noch größere Modelle zu erwarten.
Tatsächlich gibt es mit Sprachmodellen wie Googles Switch Transformer bereits solche mit 1,6 Billionen Parametern, diese setzen allerdings auf Sparse-Modeling, im Fall von Google konkret auf eine Mixture-of-Experts Transformer-Architektur.
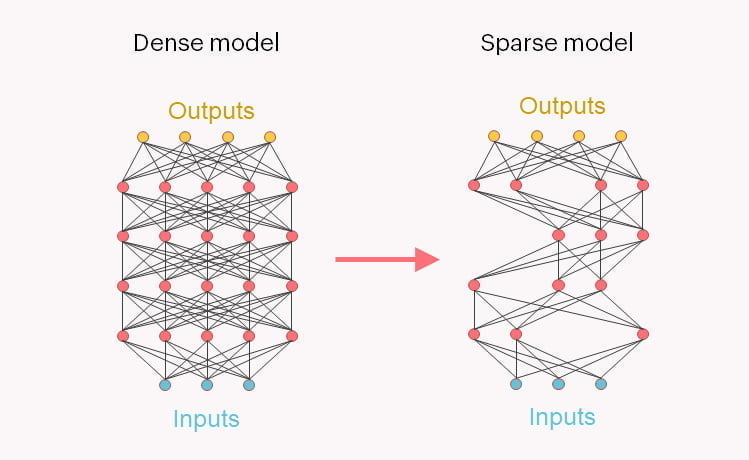
Während etwa bei GPT-3 bei jeder Verarbeitung alle Teile des neuronalen Netzes beteiligt sind, nutzen Sparse-Modelle wie Switch Transformer Verfahren, bei denen nur noch für die Aufgabe relevante Teile des Netzes aktiv werden. Damit lässt sich die benötigte Rechenleistung für Anfragen an das Netz stark reduzieren.
Erste Früchte einer europäischen KI-Kooperation?
Google nutzt Sparse-Modeling im Fall von Switch Transformer, um Sprachmodelle weiter zu skalieren. Doch umgekehrt lassen sich damit auch kleinere Netze mit ähnlicher Leistung wie große Modelle trainieren.
Genau das haben nun der KI-Chip-Hersteller Graphcore und das KI-Startup Aleph Alpha getan. Die beiden europäischen KI-Unternehmen kündigten im Juni 2022 eine Kooperation an, deren Ziel unter anderem die Entwicklung großer europäischer KI-Modelle ist.
Aleph-Alpha-CEO Jonas Andrulis wies im vergangenen Sommer auf die Vorteile der Graphcore Hardware für Sparse-Modeling hin: "Die IPU von Graphcore bietet die Möglichkeit, fortschrittliche technologische Ansätze wie Conditional Sparsity zu evaluieren. Diese Architekturen werden zweifellos eine Rolle in der zukünftigen Forschung von Aleph Alpha spielen."
Graphcore und Aleph Alpha zeigen schlankes Luminous-Sprachmodell
Die beiden Unternehmen konnten das 13 Milliarden Parameter große "Luminous Base"-Sprachmodell von Aleph Alpha auf 2,6 Milliarden Parameter verschlanken. Die Unternehmen zeigten zudem eine verschlankte Variante von Lumi, einem "Conversational Module" für Luminous.
Das genutzte Sparse-Modeling habe knapp 80 Prozent des Modellgewichts eliminiert und gleichzeitig die meisten seiner Fähigkeiten erhalten, heißt es in der Pressemitteilung.
Das neue Modell nutzt die von der Graphcores Intelligence Processing Unit (IPU) unterstützten Point Sparse Matrix Multiplications und benötige nur noch 20 Prozent der Rechenleistung und 44 Prozent des Speichers des ursprünglichen Modells.
Durch die geringe Größe könne das 2,6 Milliarden Parameter Modell vollständig auf dem Ultra-High-Speed On-Chip-Memory eines Graphcore IPU-POD16 Classic gehalten werden - und so maximale Leistung erzielen. Das Modell benötige zudem 38 Prozent weniger Energie.
"Sparsification" zentral für nächste Generation von KI-Modellen
Für die nächste Generation von Modellen werde die "Sparsification" von entscheidender Bedeutung sein, so die Unternehmen. Spezialisierte Teilmodelle würden durch sie in die Lage versetzt, ausgewähltes Wissen effizienter zu beherrschen.
"Dieser Durchbruch beim Sparse Modeling wirkt sich auf das kommerzielle Potenzial von KI-Unternehmen wie Aleph Alpha aus, die damit in der Lage sind, leistungsstarke KI-Modelle mit minimalen Anforderungen an die Rechenleistung für Kunden bereitzustellen", heißt es weiter.
Auch Google folgt diesem Weg. Im Oktober 2021 sprach KI-Chef Jeff Dean das erste Mal über die KI-Zukunft des Suchgiganten: Pathways soll einmal eine Art KI-Mehrzwecksystem werden - und setzt als zentrales Element auf Sparse-Modeling.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.