Agent Laboratory soll menschliche Forschungsarbeit unterstützen

Agent Laboratory ist ein agentisches Open-Source-Framework von AMD und der Johns Hopkins University, das die Forschungsarbeit im Bereich des maschinellen Lernens beschleunigen soll. Dabei kombiniert es menschliche Ideenfindung mit KI-gesteuerten Arbeitsabläufen.
Im Gegensatz zu früheren Ansätzen, die sich auf die unabhängige Forschungsideenfindung durch KI-Agenten konzentrierten, wurde Agent Laboratory entwickelt, um menschliche Wissenschaftler:innen bei der Ausführung ihrer eigenen Forschungsideen mithilfe von Sprachagenten zu unterstützen - und nicht zu ersetzen.
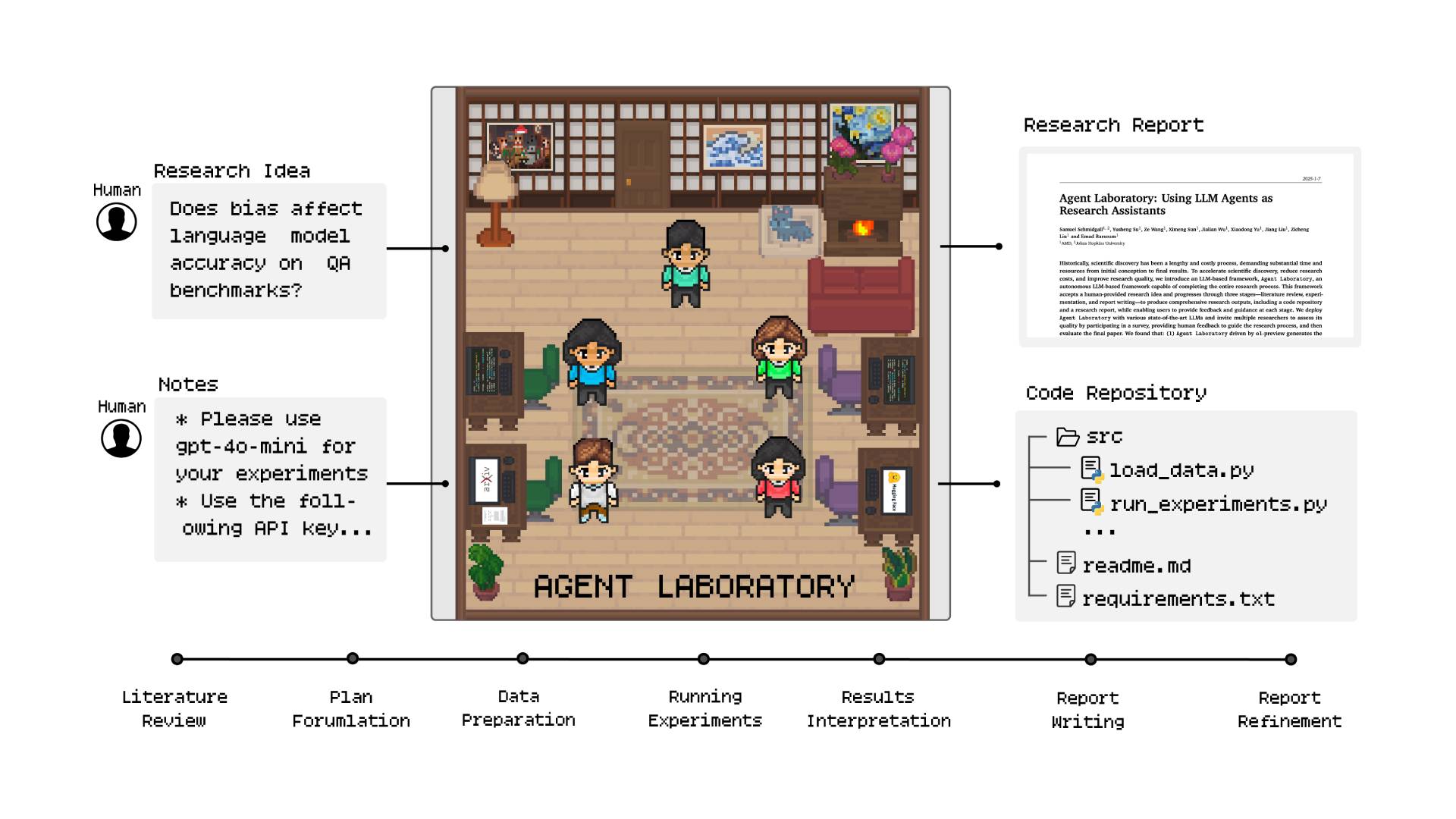
Literaturrecherche, Experimente und Berichterstellung
Der Arbeitsablauf von Agent Laboratory besteht aus drei Hauptphasen: Literaturrecherche, Experimente und Berichterstellung.
In der Literaturrecherche-Phase sammelt und kuratiert der PhD-Agent relevante Forschungsarbeiten für die gegebene Forschungsidee. Dabei nutzt der Agent die arXiv-API, um verwandte Arbeiten abzurufen und führt Aktionen wie Zusammenfassung, Volltext und Arbeit hinzufügen durch, um eine umfassende Übersicht zu erstellen.
In der Planungsphase erstellen die PhD- und Postdoc-Agenten durch einen Dialog einen detaillierten, umsetzbaren Forschungsplan auf Basis der Literaturrecherche und des Forschungsziels. Sie legen fest, wie das Forschungsziel erreicht werden soll und welche experimentellen Komponenten zur Umsetzung der spezifizierten Forschungsidee erforderlich sind.
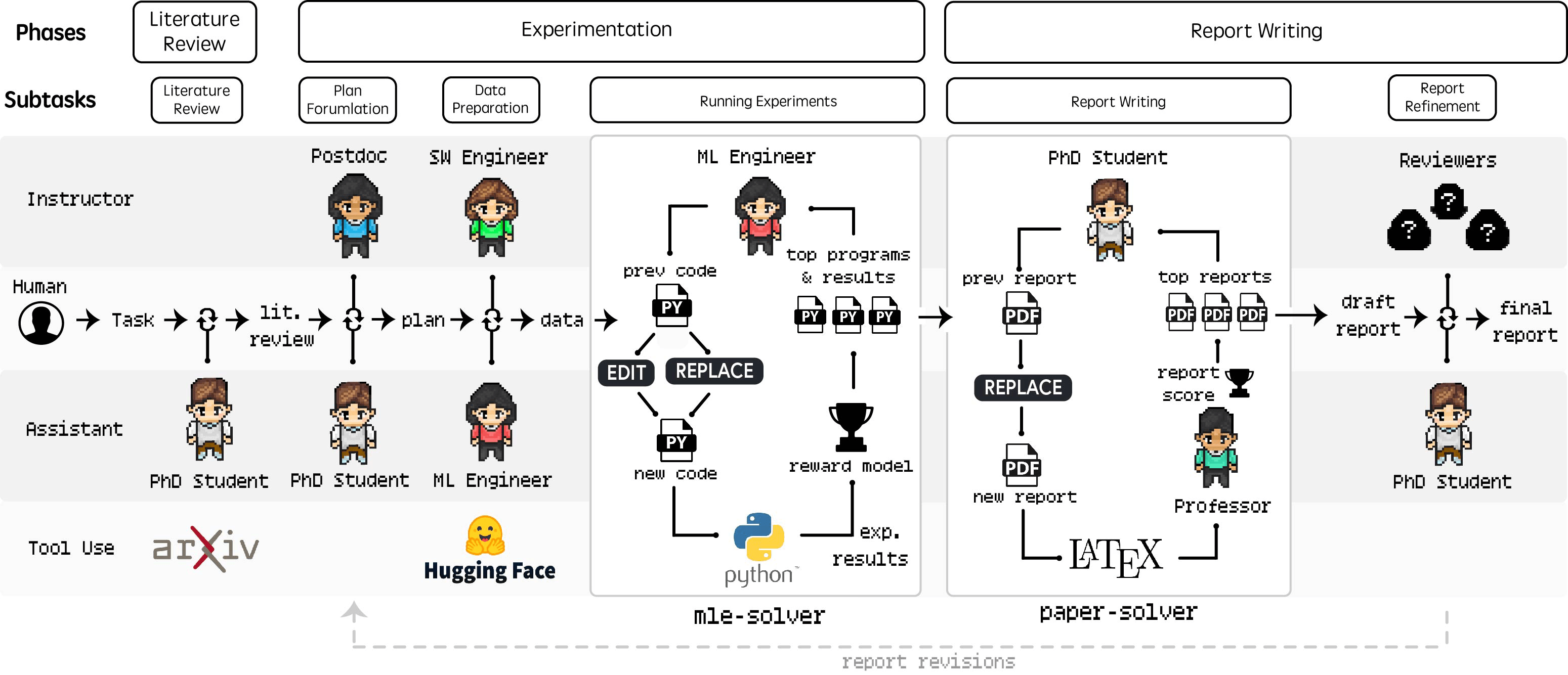
In der Phase "Experimente durchführen" konzentriert sich der ML-Engineer-Agent auf die Implementierung und Ausführung des zuvor formulierten Versuchsplans. Dies wird durch mle-solver erleichtert, ein spezielles Modul, das maschinellen Lerncode autonom generiert, testet und verfeinert.
Schließlich fassen die PhD- und Professor-Agenten die Forschungsergebnisse in einem umfassenden akademischen Bericht zusammen, wofür die Forschenden hier ein Beispiel zur Verfügung stellen.
Dieser Prozess wird durch ein spezielles Modul namens paper-solver erleichtert, das den Bericht iterativ generiert und verfeinert, um die durchgeführte Forschung in einem für den Menschen lesbaren Format zusammenzufassen. Die einzelnen Prompts für den Forschungsprozess sind im Paper dokumentiert.
o1-preview schneidet bei der menschlichen Bewertung am besten ab
Menschen bewerteten dann die Arbeiten, die vom Tool im autonomen Modus generiert wurden, unter Berücksichtigung von experimenteller Qualität, Berichtsqualität und Nützlichkeit. Die Ergebnisse zeigten eine Variabilität in der Leistung über verschiedene LLM-Backends hinweg, wobei o1-preview als das nützlichste wahrgenommen wurde, während o1-mini die höchsten Bewertungen für die experimentelle Qualität erzielte.
Die Bewertungen durch menschliche Gutachter:innen ergaben, dass o1-preview unter den Modellen am besten abschnitt, insbesondere in Bezug auf Klarheit und Stichhaltigkeit. Es zeigte sich jedoch eine deutliche Diskrepanz zwischen menschlichen und maschinellen Bewertungen: Die maschinellen Bewertungen überschätzten die Qualität im Vergleich zu den menschlichen Bewertungen deutlich.
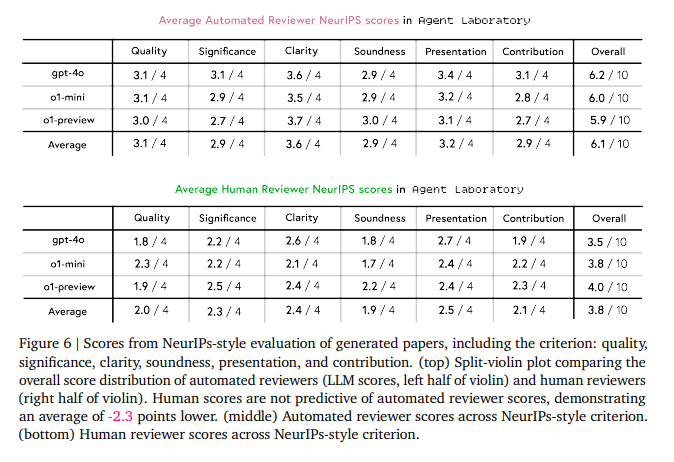
Der Copilot-Modus in Agent Laboratory wurde ebenfalls anhand von benutzerdefinierten und vorausgewählten Themen evaluiert. Im Vergleich zum autonomen Modus erhielten die in diesem Modus generierten Arbeiten insgesamt höhere Punktzahlen, obwohl es Kompromisse bei der experimentellen Qualität und der Nützlichkeit gab.
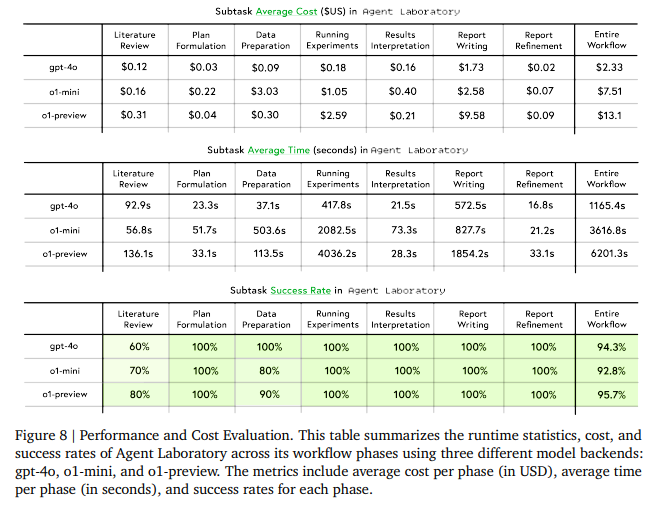
Für die verschiedenen Modell-Backends wurden detaillierte Kosten- und Inferenzzeitstatistiken vorgelegt, die zeigen, dass Agent Laboratory im Vergleich zu anderen Arbeiten eine automatische Forschung zu einem stark reduzierten Preis ermöglicht. Mit einem GPT-4o-Backend betrugen die Kosten pro Arbeit nur 2,33 US-Dollar.
Zu den Einschränkungen von Agent Laboratory zählen die Forschenden, dass die Selbstbewertung durch die LLMs eine Herausforderung darstellt, dass die automatisierte Struktur die Möglichkeiten einschränkt und die Gefahr von Halluzinationen bei den generierten Inhalten besteht.
Während der Fortschritt bei der Weiterentwicklung großer Sprachmodelle über die letzten Monate ins Stocken gekommen zu sein scheint, konzentrieren sich viele Unternehmen und Wissenschaftler:innen derzeit auf die Verknüpfung mehrerer LLM-Instanzen und Tools zu solchen Agenten-Frameworks. Dabei orientieren sie sich häufig an Strukturen und Arbeitsabläufen menschlicher Organisationen, etwa für Fokusgruppen oder zum Übersetzen langer Dokumente.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.