AI2 veröffentlicht offenen Mega-Datensatz zum Training von Sprachmodellen

Das Allen Institute for AI (AI2) hat Dolma vorgestellt, einen Open-Source-Datensatz mit drei Billionen Token aus einer vielfältigen Sammlung von Webinhalten, wissenschaftlichen Publikationen, Code und Büchern. Es ist das bisher größte öffentlich zugängliche Datensatz seiner Art.
Dolma ist Grundlage des Sprachmodells OLMo (Open Language Model), das sich derzeit bei AI2 in der Entwicklung befindet und Anfang 2024 erscheinen soll. Mit dem Ziel vor Augen, das "beste offene Sprachmodell" zu entwickeln, entstand der riesige Datensatz Dolma (Data to feed OLMo).
Dolma ist der derzeit größte Open-Source-Datensatz und steht ab sofort Entwickler:innen und Wissenschaftler:innen über Hugging Face zur Verfügung. Dort finden sich auch die Werkzeuge, die die Forscher:innen für die Erstellung verwendet haben, um die Reproduzierbarkeit der Ergebnisse zu gewährleisten.
Bereinigung der Daten, größtenteils auf Englisch
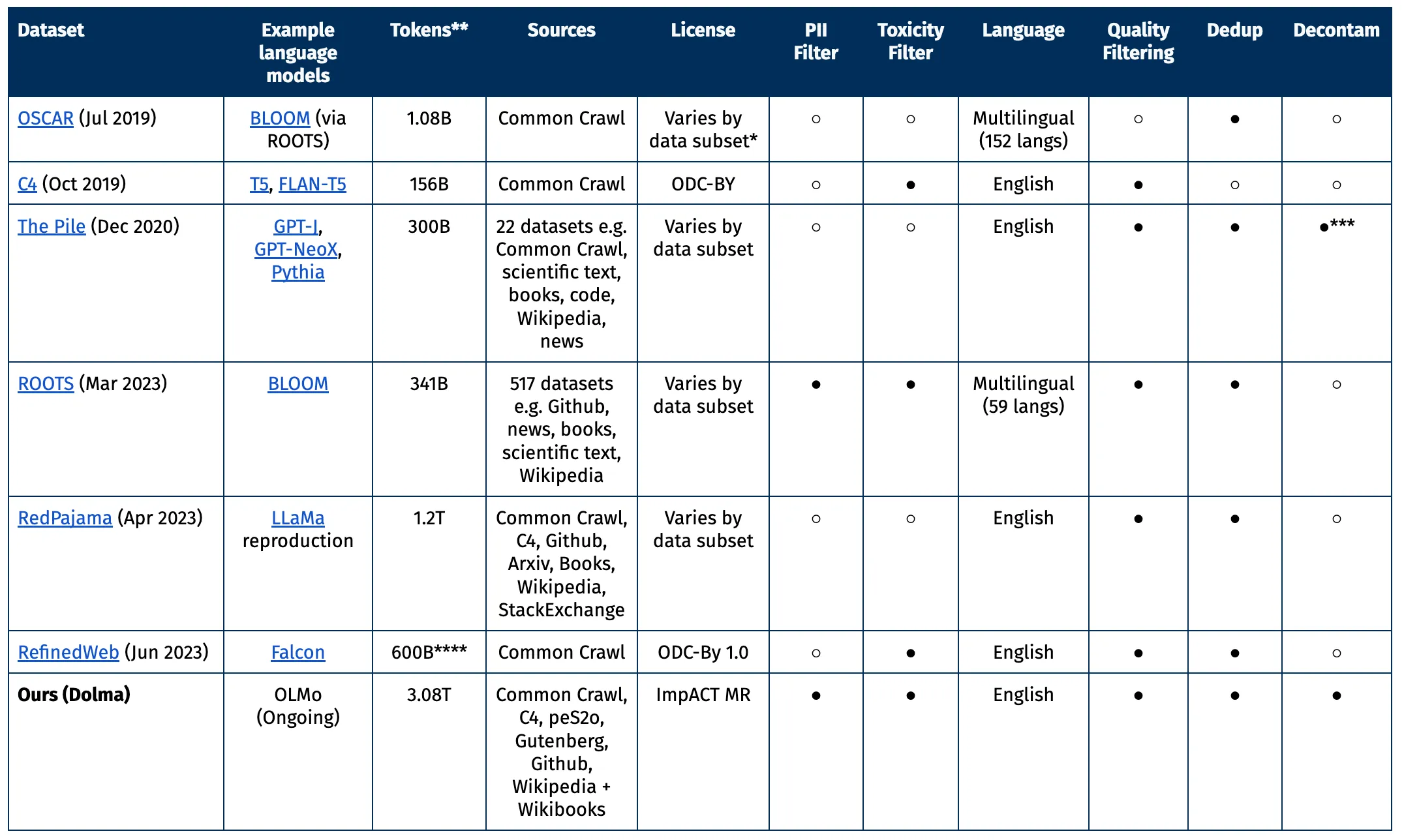
Für die Erstellung von Dolma wurden Daten aus verschiedenen Quellen in bereinigte Textdokumente umgewandelt.
In der ersten Version beschränkt sich Dolma weitgehend auf englische Texte. Zur Filterung der Daten wurde ein Spracherkennungsmodell verwendet. Um einen Bias gegen Dialekte von Minderheiten auszugleichen, hat das Team alle Texte übernommen, die vom Modell mit einer Sicherheit von 50 Prozent als englisch klassifiziert wurden. In zukünftigen Versionen sollen weitere Sprachen einbezogen werden.

In weiteren Schritten haben die Forschenden den Datensatz etwa von Duplikaten, minderwertigen Inhalten oder sensiblen Informationen bereinigt und die Qualität der Code-Beispiele verbessert.
Vergleich mit anderen offenen Datensätzen
Ein Großteil des Datensatzes stammt aus dem gemeinnützigen Common-Crawl-Projekt, wobei der Fokus auf Webdaten liegt. Hinzu kommen weitere Webseiten aus der Sammlung C4, akademische Texte von peS20, Code-Schnipsel aus The Stack, Bücher aus Project Gutenberg und die englische Wikipedia.
Das ideale Dataset sollte in den Augen von AI21 mehrere Kriterien erfüllen: Offenheit, Repräsentativität, Größe und Reproduzierbarkeit. Zudem sollten Risiken minimiert werden, insbesondere solche, die Einzelpersonen betreffen könnten.
Vorherige Studien haben gezeigt, dass nicht nur die Parameterzahl des Modells, sondern auch der Umfang des Trainingsmaterials eines Sprachmodells für die Leistung eine zentrale Rolle spielen.
Veröffentlichung von Dolma
Der Datensatz wird unter der ImpACT-Lizenz von AI2 als Medium-Risk-Artefakt veröffentlicht. Forschende müssen bestimmte Anforderungen erfüllen, wie etwa die Angabe ihrer Kontaktdaten und dem beabsichtigten Verwendungszweck von Dolma zustimmen. Darüber hinaus wurde ein Mechanismus eingerichtet, um die Entfernung persönlicher Daten auf Anfrage zu ermöglichen.
The license has too many weird clauses to be counted as open-source.
— Narendra Patwardhan (@overlordayn) August 20, 2023
Nach der Vorstellung von Dolma als Open-Source-Datensatz wurden Stimmen von Kritiker:innen laut, die zu viele Klauseln in der Lizenz bemängelten. So sei Dolma zwar öffentlich zugänglich, könne aber nicht als Open Source betrachtet werden. Auch die Bezeichnung des LLaMA-2-Modells als Open Source durch Meta wurde kürzlich von der Open Source Initiative kritisiert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.