Alibaba erweitert Qwen-Image um Bildbearbeitungsfunktionen

Das chinesische Unternehmen Alibaba erweitert sein Qwen-Image-Modell um Bildbearbeitungsfunktionen. Die neue Version soll besonders bei der Manipulation von Texten in Bildern überzeugen.
Qwen-Image-Edit basiert auf Alibabas 20-Milliarden-Parameter-Modell Qwen-Image und kombiniert zwei verschiedene Ansätze zur Bildbearbeitung. Das System verarbeitet Eingabebilder parallel über Qwen2.5-VL für semantische Kontrolle und einen Variational Autoencoder (VAE) für die Steuerung des visuellen Erscheinungsbilds. Viel mehr verrät Alibaba zur Architektur von Qwen-Image-Edit mangels technischem Bericht bislang nicht.
Die Architektur ermöglicht laut Alibaba sowohl grundlegende Bildmanipulationen als auch komplexe semantische Änderungen. Während bei der Erscheinungsbearbeitung alle anderen Bildregionen unverändert bleiben müssen, erlaubt die semantische Bearbeitung Pixeländerungen im gesamten Bild bei erhaltener semantischer Konsistenz.
Video: Alibaba
Zwei Bearbeitungsmodi für verschiedene Anwendungen
Für die semantische Bearbeitung demonstriert Alibaba die Erstellung von IP-Inhalten mit dem firmeneigenen Capybara-Maskottchen. Obwohl sich die meisten Pixel zwischen Original und bearbeitetem Bild unterscheiden, bleibt die Charakterkonsistenz erhalten.
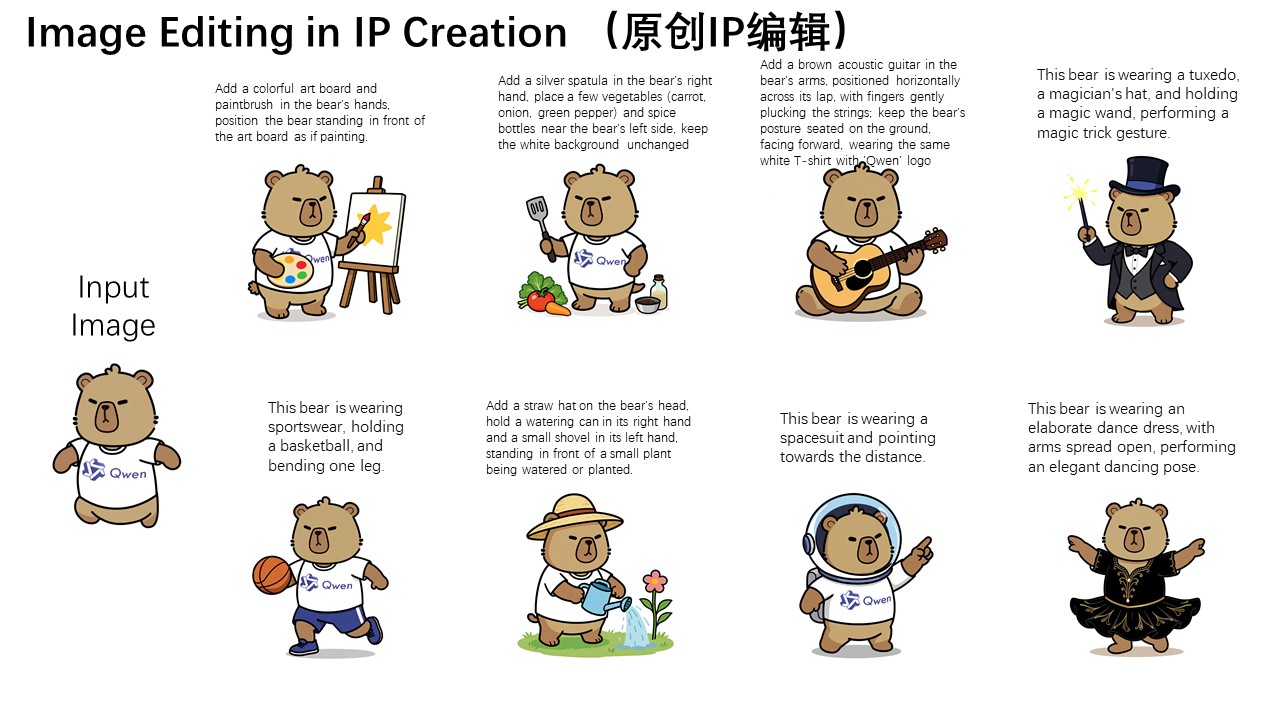
Weitere Einsatzgebiete umfassen die Generierung neuer Perspektiven mit 90- oder 180-Grad-Rotationen von Objekten sowie Stil-Transfer für die Avatar-Erstellung. Als Beispiel führt Alibaba die Umwandlung von Porträts in Studio Ghibli-Stil an.

Qwen-Image-Edit fügt auch Schilder inklusive entsprechender Reflexionen hinzu, entfernt feine Haarsträhnen oder ändert die Farbe einzelner Buchstaben. Auch Hintergrund- und Kleidungsmodifikationen seien möglich.

Bilinguale Textbearbeitung mit schrittweiser Korrektur
Ein Schwerpunkt liegt auf der Textmanipulation in chinesischer und englischer Sprache. Das System soll Texte direkt in Bildern hinzufügen, löschen oder modifizieren können, während Schriftart, Größe und Stil des Originals erhalten bleiben.

Nutzer:innen können Begrenzungsrahmen um fehlerhafte Bereiche ziehen, woraufhin das Modell die markierten Regionen korrigiert. Bei obskuren Zeichen wie "稽" versagt das System jedoch zunächst.

In solchen Fällen ermöglicht eine verkettete Bearbeitung die schrittweise Verbesserung: Nutzer:innen markieren spezifische Teilbereiche problematischer Zeichen und lassen das Modell diese Details nachbearbeiten, bis das gewünschte Ergebnis erreicht ist.
Schneller Fortschritt bei Bildmodellen
Laut Alibaba erreicht Qwen-Image-Edit State-of-the-Art-Performance in mehreren öffentlichen Benchmarks für Bildbearbeitungsaufgaben, nennt jedoch keine konkreten Ergebnisse. Das Modell ist über Qwen Chat mit der "Image Editing" Funktion zugänglich und steht auf Github, Hugging Face und Modelscope zur Verfügung.
Die Entwicklung von Qwen-Image-Edit zeigt, wie schnell Bildmodelle bei gezielten Bearbeitungen und Text-Rendering voranschreiten. Bislang war es für KI-Systeme extrem schwierig, nur spezielle Bereiche in Bildern zu verändern und den Rest unverändert zu lassen.
Vor kurzem hatte Black Forest Labs mit Flux.1 Kontext einen ähnlichen Ansatz vorgestellt, der Text-zu-Bild-Generierung und Bildbearbeitung in einem Modell kombiniert. Allerdings zeigte Flux.1 Kontext in längeren Bearbeitungsketten sichtbare Artefakte und hat Schwächen bei der korrekten Prompt-Umsetzung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.