Alibabas KI-Forschungsabteilung Qwen stellt neue Coding-KI-Modelle vor

Alibabas Forschungseinheit Qwen setzt mit der neuen Qwen-2.5-Coder-Serie voll auf Skalierung, um die Leistungsfähigkeit ihrer Code-KI-Modelle zu steigern.
Die von dem chinesischen Unternehmen Alibaba betriebene Forschungsgruppe Qwen hat unter dem Namen Qwen-2.5-Coder eine neue Serie von KI-Modellen speziell für die Softwareentwicklung vorgestellt. Die Modelle sollen Programmierer:innen helfen, Code zu schreiben, analysieren und zu verstehen.
Die Qwen-2.5-Coder-Serie umfasst sechs Modellgrößen mit 0,5 bis 32 Milliarden Parametern. Damit soll sie unterschiedlichen Anwendungsszenarien gerecht werden.
Mit Cursor und Artefakten getestet
Um im Arbeitsalltag von Programmierer:innen bestmöglich zu unterstützen, haben die Forschenden die Modelle zwei praxisnahe Einsatzmöglichkeiten getestet.
Die Modelle zeigten sowohl im beliebten KI-Editor Cursor als auch als Web-Chatbot mit Artefakt-Unterstützung überzeugende Leistungen, vergleichbar mit ChatGPT oder Claude. Eine Implementierung der Chatbot-Funktionalität soll bald in Alibabas Cloud-Plattform Tongyi integriert werden.
Video: Qwen
Video: Qwen
Neues Open-Source-Spitzenmodell
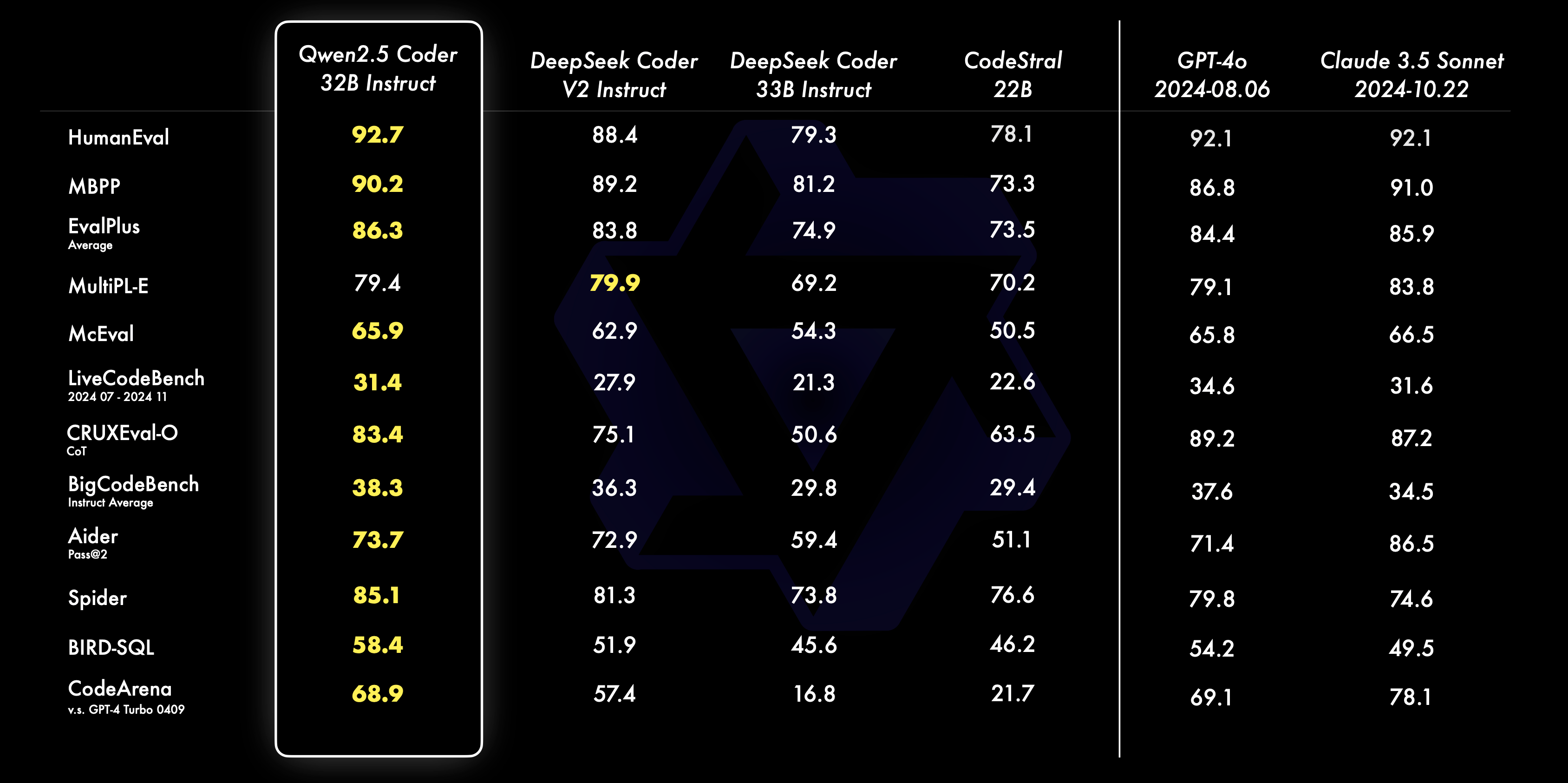
In Benchmarks zur Codegenerierung erreichte das größte Modell Qwen-2.5-Coder-32B-Instruct laut Qwen Bestwerte unter den verfügbaren Open-Source-Systemen wie DeepSeek-Coder oder Codestral.
Zugleich schnitten sie Qwen zufolge auch bei allgemeineren Aufgaben wie logischem Schlussfolgern und Sprachverständnis gut ab. Das viel größere Foundation-Modell GPT-4o zeigte in manchen Benchmarks jedoch noch mehr Leistung.
Mehr als 20 Billionen Tokens Trainingsdaten
Die Trainingsdaten setzten sich aus zwei Quellen zusammen: zum einen der generelle Datenmix der im September eingeführten Qwen-2.5-Basismodelle mit 18,5 Billionen Tokens, zum anderen 5,5 Billionen Tokens aus öffentlich verfügbarem Quellcode und programmierrelevanten Web-Texten.
Damit ist es das erste quelloffene Modell, dass die Grenze von 20 Trillionen Tokens Trainingsmaterial übersteigt. Die Forscher:innen haben die Daten mithilfe spezieller Filtermechanismen bereinigt, um eine hohe Qualität zu gewährleisten.
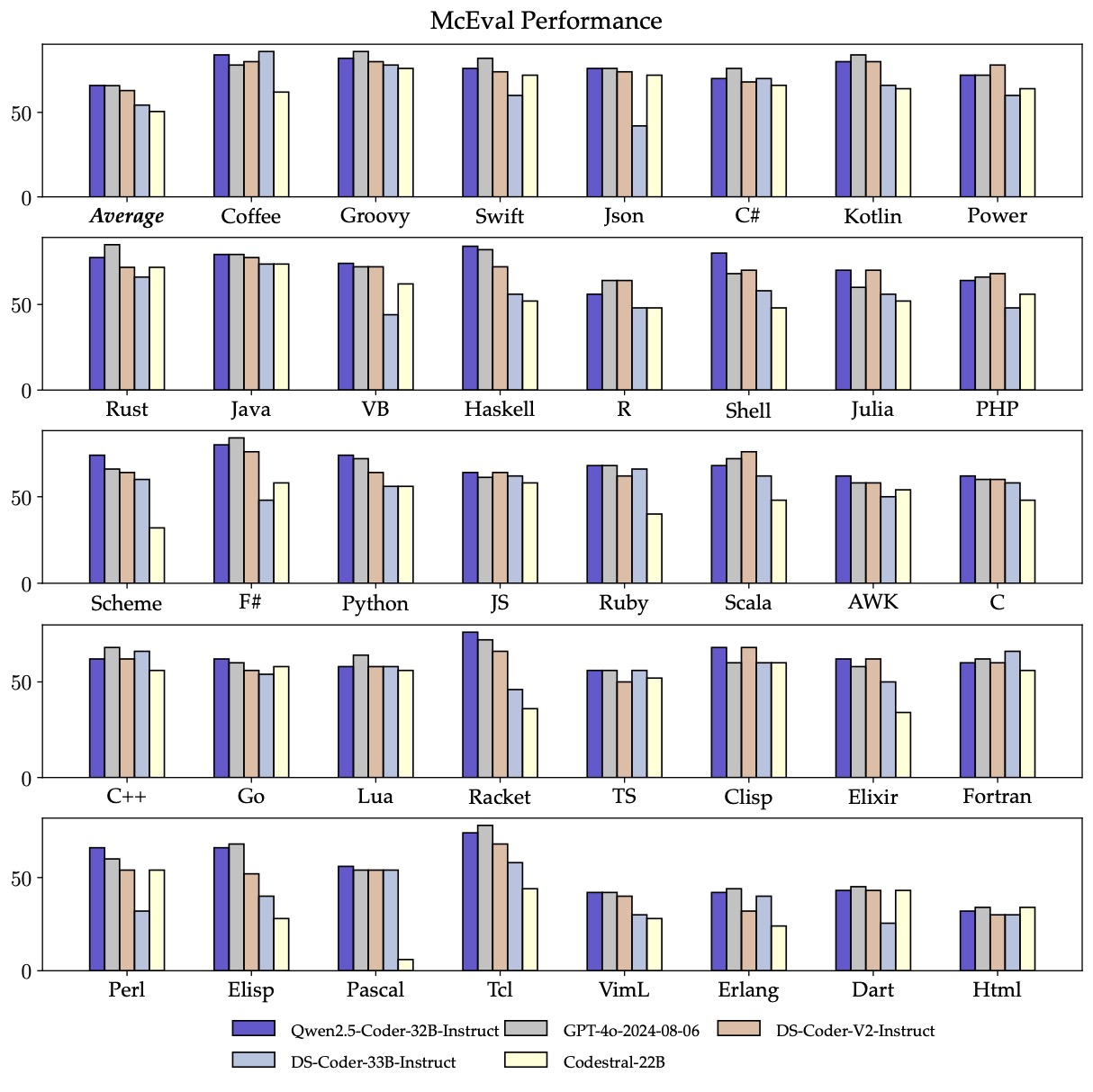
Dem technischen Bericht zufolge verfügen die Qwen-2.5-Coder-Modelle über Kontextfenster von bis zu 128.000 Token. Das Spitzenmodell Qwen-2.5-Coder-32B-Instruct beherrscht über 40 Programmiersprachen – von verbreiteten Sprachen wie Python, Java und JavaScript bis hin zu selteneren wie Haskell oder Racket.
"Scaling is all you need"
Qwen setzt bei der Leistungssteigerung seiner Code-KI-Modelle konsequent auf Skalierung. Der technische Bericht zu den Qwen2.5-Coder-Modellen belegt eine klare Korrelation: Größere Modelle und umfangreichere Datenmengen führen zu besseren Ergebnissen bei Programmieraufgaben. Für die Zukunft plant Qwen sowohl eine weitere Skalierung auf größere Modelle als auch Verbesserungen beim logischen Schlussfolgern.
Alibaba hat alle Modelle außer das mit drei Milliarden Parametern unter einer Apache-2.0-Lizenz auf GitHub veröffentlicht, um die Weiterentwicklung KI-gestützter Programmierwerkzeuge zu fördern. Eine kostenlose Demo findet sich auf Hugging Face.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.