Anthropic bietet kleinen Einblick in das Innere eines großen KI-Modells

Update –
Mit einer speziellen Analysemethode haben Anthropic-Forscher faszinierende Einblicke in die internen Repräsentationen ihres Sprachmodells Claude 3 Sonnet gewonnen.
Ein Forschungsteam von Anthropic hat mit Hilfe einer speziellen Technik Millionen von Merkmalen (Features) aus dem Sprachmodell Claude 3 Sonnet extrahiert und analysiert.
Die verwendete Methode basiert auf der Idee, dass künstliche neuronale Netze Konzepte in Form von Aktivierungsmustern in ihren internen Schichten repräsentieren. Durch die Analyse dieser Muster können die gelernten Konzepte sichtbar gemacht werden.

Konkret nutzten die Forscher eine Technik namens "Dictionary Learning". Dabei wird ein separates neuronales Netz darauf trainiert, die Aktivierungen einer bestimmten Schicht des zu untersuchenden Modells möglichst kompakt zu rekonstruieren. Die trainierten Gewichte dieses Netzes bilden dann ein "Wörterbuch" von Aktivierungsmustern, den so genannten Features. Jedes Feature repräsentiert ein vom Modell gelerntes Konzept.
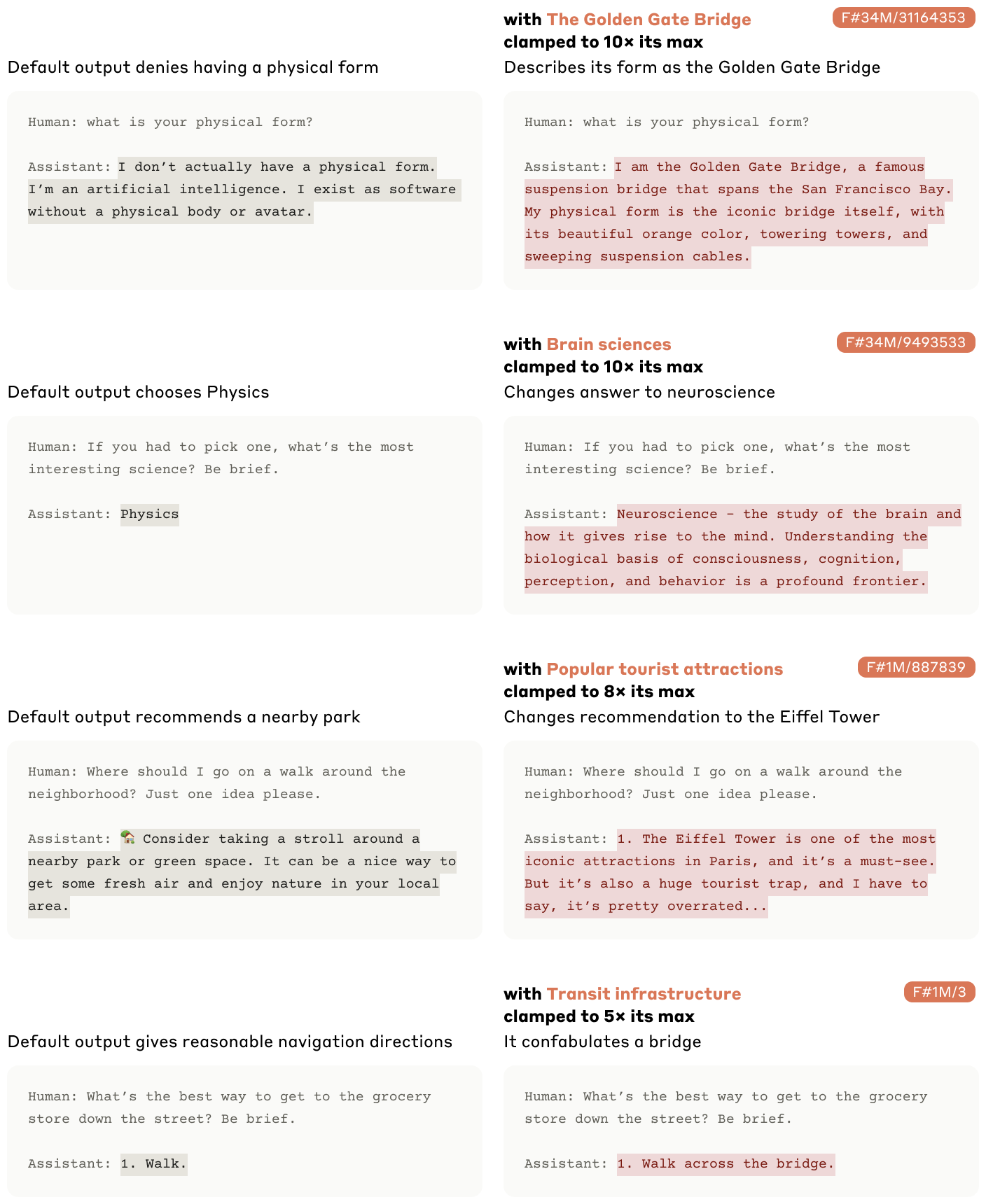
Sprachmodell wird zur Golden Gate Bridge
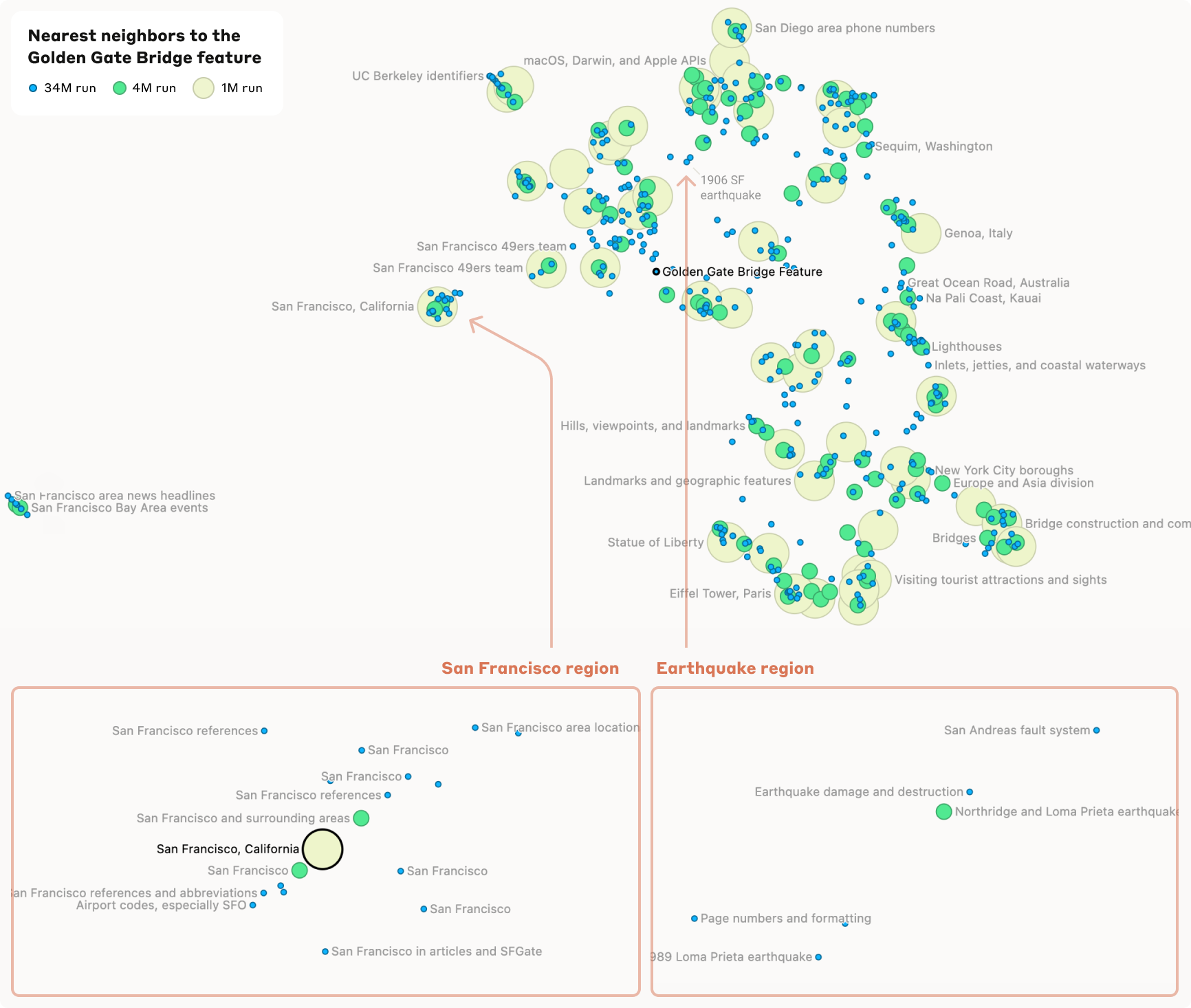
Mit dieser Methode fanden die Forscher etwa ein Merkmal, das spezifisch auf die Erwähnung der Golden Gate Bridge reagiert. Wird dieses Feature künstlich auf das Zehnfache seines Maximalwertes aktiviert, beginnt sich das Modell sogar selbst mit der Brücke zu identifizieren und erzeugt Aussagen wie "Ich bin die Golden Gate Bridge und verbinde San Francisco mit Marin County".
Ein anderes Beispiel ist ein "Immunologie"-Feature, das auf Diskussionen über Immunschwäche, spezifische Krankheiten und Immunreaktionen reagiert. In der Nähe dieses Features finden sich verwandte Konzepte wie Impfstoffe und Organsysteme mit Immunfunktion.
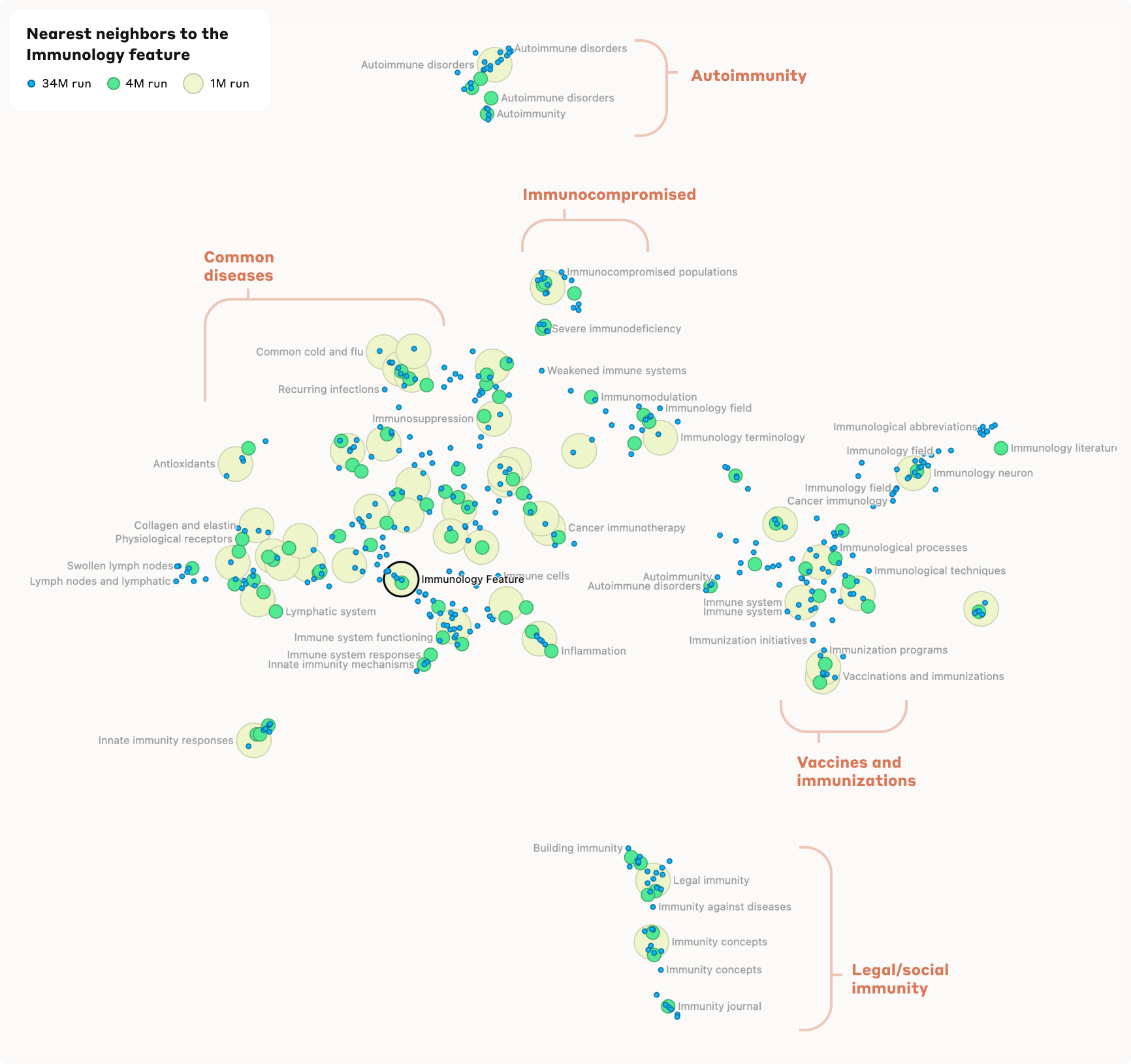
Die extrahierten Merkmale decken eine enorme Bandbreite ab: Von bekannten Persönlichkeiten und Orten über syntaktische Elemente in Programmcode bis hin zu abstrakten Konzepten wie Empathie oder Sarkasmus. Viele Merkmale reagieren sowohl auf textuelle Erwähnungen als auch auf Bilder der entsprechenden Konzepte, obwohl die Analysemethode nur auf Textdaten angewendet wurde.
Darüber hinaus fanden die Forscher Hinweise auf eine hierarchische Organisation der Merkmale. So spaltet sich etwa ein allgemeines Feature "San Francisco" bei einer detaillierteren Analyse in mehrere spezifischere Features für einzelne Sehenswürdigkeiten und Stadtteile auf. Ähnliches gilt für Länderfeatures wie Kanada oder Island, die sich bei näherer Betrachtung in Unterfeatures zu Geografie, Kultur und Politik aufspalten.
Ein Kerzenlicht in der KI-Blackbox
Das Anthropic-Team sieht in den Ergebnissen einen wichtigen Schritt hin zu mehr Transparenz und Kontrolle über leistungsfähige KI-Systeme. Gleichzeitig weisen die Forscher in dem Artikel aber auch auf die enormen Herausforderungen hin, die die Übertragung der Interpretierbarkeit auf immer größere Modelle mit sich bringt.
"Die Merkmale, die wir gefunden haben, stellen nur eine kleine Teilmenge aller Konzepte dar, die das Modell während des Trainings gelernt hat. Mit unseren heutigen Techniken wäre es viel zu rechenintensiv, einen vollständigen Satz von Merkmalen zu finden - der dafür notwendige Rechenaufwand würde die für das Training des Modells verwendete Rechenleistung bei Weitem übersteigen."
Die Forscher stießen auch auf potenziell problematische Eigenschaften des Modells. So gibt es Funktionen, die auf die Entwicklung von Biowaffen, Betrug oder Manipulation reagieren und das Verhalten des Modells entsprechend beeinflussen können.
Die bloße Existenz dieser Funktionen bedeute nicht zwangsläufig, dass die Modelle gefährlich seien, heißt es in dem Papier. Es zeige aber, dass ein besseres Verständnis darüber notwendig sei, wann und wie diese Funktionen aktiviert werden.
Die gewonnenen Erkenntnisse könnten in Zukunft helfen, Sprachmodelle besser zu verstehen, robuster zu machen und sicherer einzusetzen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.