Anthropic gibt Einblicke in die "Gedankenwelt" seiner KI
Eine neue Studie von Anthropic gibt Einblicke in die internen Prozesse des Sprachmodells Claude. Die Forschung zeigt, wie die KI plant, argumentiert und zwischen Sprachen wechselt.
Anthropic hat laut zwei neuen Forschungspapieren eine Art "KI-Mikroskop" entwickelt, das die internen Abläufe des Sprachmodells Claude 3.5 Haiku sichtbar macht. Die Methode erlaubt es erstmals, einen kleinen Teil der "Gedankengänge" einer KI während der Textverarbeitung nachzuvollziehen.
Die Forschung zeigt laut Anthropic unter anderem, dass Claude eine Art universelle "Denksprache" verwendet, die zwischen verschiedenen menschlichen Sprachen vermittelt. Wenn das Modell beispielsweise nach dem "Gegenteil von klein" in unterschiedlichen Sprachen gefragt wird, aktiviert es zunächst sprachunabhängige Konzepte, bevor es die Antwort in der jeweiligen Zielsprache ausgibt.
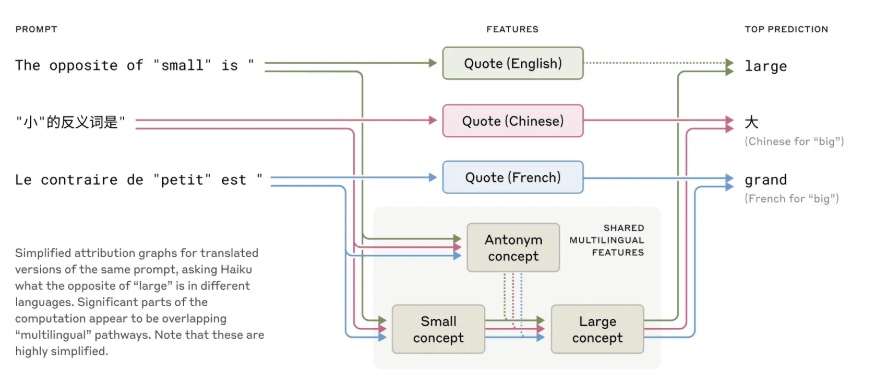
Größere Modelle wie Claude 3.5 zeigen hier deutlich stärkere Überlappungen zwischen Sprachen als kleinere Modelle. Dieses abstrakte Konzeptdenken könnte laut Anthropic ein Schlüssel für echtes Sprachverständnis sein.
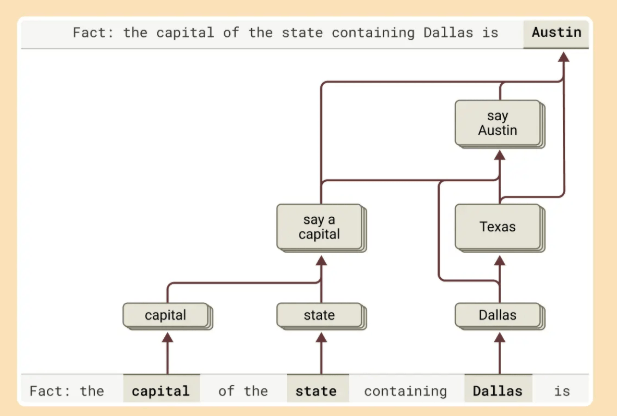
Bei komplexen Fragen wie "Was ist die Hauptstadt des Bundesstaats, in dem Dallas liegt?" soll Claude tatsächlich mehrere Denkschritte durchführen: Erst aktiviert es Konzepte für "Dallas liegt in Texas" und verbindet dies dann mit "die Hauptstadt von Texas ist Austin". Dies deutet laut Anthropic auf echtes Schlussfolgern statt bloßem Auswendiglernen hin.
KI plant voraus und wägt Optionen ab
Überraschend war für die Forscher die Erkenntnis, dass Claude bei der Gedichtgenerierung mehrere Wörter im Voraus plant. Das Modell sucht sich zunächst passende Reimwörter aus und konstruiert dann die Zeilen so, dass sie auf diese Wörter hinführen. Werden diese Zielwörter verändert, schreibt Claude ein gänzlich neues Gedicht – ein Indiz für echte Planung statt reiner Wortvorhersage.
Bei mathematischen Aufgaben nutzt Claude laut der Studie parallel arbeitende Rechenwege: Ein Pfad berechnet eine grobe Näherung, während ein anderer die exakte letzte Stelle bestimmt. Interessanterweise beschreibt Claude auf Nachfrage einen anderen Rechenweg als den tatsächlich genutzten - ein Hinweis, dass das Modell nur menschliche Erklärmuster simuliert, die mit der tatsächlichen Berechnung wenig zu tun haben. Gibt man dem Modell zudem einen falschen Hinweis, konstruiert es auf dieser Basis oft eine stimmige, aber inhaltlich falsche Begründung.
Gemeinsame Ziele, andere Architekturen
Auch Google Research hat kürzlich Forschungsergebnisse vorgestellt, die mögliche Parallelen zwischen der Sprachverarbeitung im menschlichen Gehirn und in KI-Modellen aufzeigen. Laut einer in Nature Human Behaviour veröffentlichten Studie stimmen die internen Repräsentationen des Whisper-Sprachmodells bemerkenswert gut mit den neuronalen Aktivitätsmustern im Gehirn während natürlicher Gespräche überein. Die Forscher konnten nachweisen, dass das Gehirn - ähnlich wie KI-Modelle - versucht, das nächste Wort vorherzusagen, bevor es gesprochen wird.
Video: Google
Dennoch gibt es laut der Google-Studie fundamentale Unterschiede in der Sprachverarbeitung: Während Transformer-Modelle hunderte oder tausende Wörter gleichzeitig verarbeiten können, arbeitet das menschliche Gehirn grundlegend anders - es verarbeitet Sprache Wort für Wort (seriell), in einer festgelegten Reihenfolge (sequenziell), wiederholt die Informationen in Schleifen (rekurrent) und über einen zeitlichen Verlauf hinweg (temporal).
Diese unterschiedliche Implementierung zeigt sich, obwohl die nicht-linearen Transformationen zwischen den Verarbeitungsschichten bei beiden Systemen ähnlich sind. "Während das menschliche Gehirn und Transformer-basierte LLMs bei der Verarbeitung natürlicher Sprache grundlegende Rechenprinzipien teilen, unterscheiden sich ihre zugrunde liegenden neuronalen Schaltkreisarchitekturen deutlich", schreibt Google.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.