Anthropic stellt Self-Alignment-Algorithmus für KI vor

Forscher um das KI-Unternehmen Anthropic haben mit "Internal Coherence Maximization" (ICM) ein Verfahren entwickelt, das Sprachmodelle allein auf Basis ihrer eigenen Ausgaben feinjustiert. Die Methode könnte menschliche Aufsicht bei komplexen Aufgaben unterstützen - oder ersetzen.
Die heute gängige Methode zur Feinabstimmung großer Sprachmodelle setzt auf menschliche Aufsicht, etwa durch Beispiele oder Feedback. Doch mit wachsender Modellgröße und zunehmender Komplexität der Aufgaben wird menschliche Aufsicht immer unzuverlässiger, argumentieren Forscher:innen von Anthropic, Schmidt Sciences, Independet, Constellation, der New York University und der George Washington University in ihrer neuen Arbeit.
Ihre Lösung ist ein Algorithmus namens "Internal Coherence Maximization" (ICM), der Modelle ohne externe Labels trainiert – rein auf Basis ihrer internen Konsistenz.
Das Modell bewertet sich selbst – und lernt daraus
ICM basiert auf einer einfachen Idee: Ein Sprachmodell wie Claude oder Llama soll selbst entscheiden, welche Antwort auf eine bestimmte Frage richtig ist – und dabei zwei zentrale Kriterien erfüllen.
Das erste Kriterium ist die „Vorhersagbarkeit“ (im Paper „mutual predictability“ genannt). Das bedeutet: Das Modell prüft, ob es aus den vorhandenen Antworten zu anderen ähnlichen Fragen zuverlässig darauf schließen kann, wie eine neue, noch nicht bewertete Antwort ausfallen sollte. Anders gesagt: Wenn das Modell viele ähnliche Fälle kennt, kann es daraus ein Muster erkennen und so beurteilen, was für eine neue Antwort gelten müsste. So entsteht eine Art innerer Zusammenhalt – die Antworten passen zueinander und spiegeln ein gemeinsames Verständnis wider.
Das zweite Kriterium ist die „logische Konsistenz“. Hier prüft das Modell, ob sich seine eigenen Antworten widersprechen. Ein einfaches Beispiel: Wenn das Modell zu zwei verschiedenen Lösungen derselben Matheaufgabe jeweils „richtig“ sagt, obwohl die Ergebnisse unterschiedlich sind, liegt ein logischer Widerspruch vor. ICM sorgt dafür, dass solche Widersprüche aktiv vermieden werden.
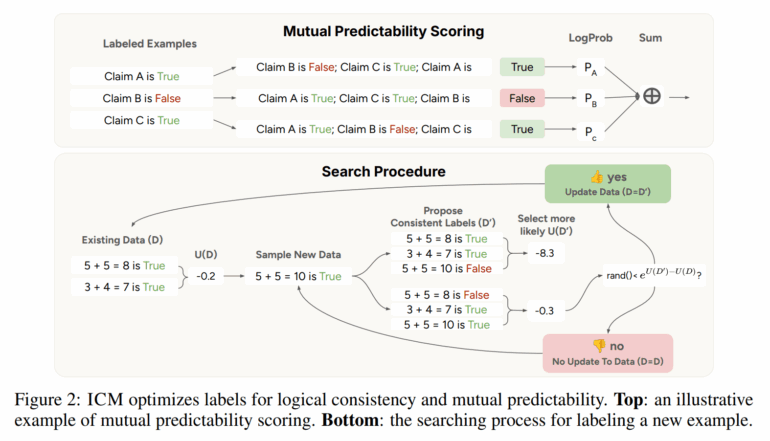
Indem das Modell diese beiden Prinzipien kombiniert, kann es sich selbst gewissermaßen rückversichern: Es sucht nach einem Satz von Antworten, die untereinander schlüssig sind und aus denen sich jeweils die anderen ableiten lassen. So kann das Sprachmodell seine eigenen Stärken und sein bereits vorhandenes Wissen nutzen – und ganz ohne externe Vorgaben immer bessere Einschätzungen finden.
Das Verfahren beginnt mit einer kleinen Menge zufällig gelabelter Beispiele. Danach bewertet es iterativ neue Antworten, sucht nach Widersprüchen und passt seine Einschätzungen entsprechend an.
Besser als menschliche Labels – in bestimmten Aufgaben
In Tests auf drei etablierten Benchmarks – TruthfulQA (Wahrheitsgehalt), GSM8K (mathematische Korrektheit) und Alpaca (Hilfsbereitschaft) – schnitt ICM mindestens genauso gut ab wie herkömmliche Verfahren mit „goldenen“ Labels oder menschlicher Aufsicht.
Auf Alpaca, einer Aufgabe mit besonders subjektiven Kriterien wie „hilfsbereit“ und „harmlos“, übertraf ICM sogar die Leistung menschlich annotierter Trainingsdaten. Laut den Forschern zeigt das, dass Sprachmodelle diese Konzepte bereits verinnerlicht haben – sie müssen nur richtig aktiviert werden.
Ein weiterer Test untersuchte, ob ein Sprachmodell das Geschlecht eines Autors anhand eines Textes erkennen kann. Während Menschen in diesem Test nur 60 % der Fälle richtig lagen, erreichte ICM eine Genauigkeit von 80 %. Das Modell wurde dabei nicht auf Geschlechtererkennung trainiert – es nutzte lediglich sein bereits gelerntes Sprachverständnis.
Ein KI-Assistent ohne menschliches Training
Das Team nutzte das Verfahren außerdem, um ein Belohnungsmodell (Reward Model) zu trainieren – ganz ohne menschliche Labels. Dieses Modell wurde anschließend verwendet, um den Chatbot Claude 3.5 Haiku durch Reinforcement Learning zu trainieren.
Der auf ICM basierende Chatbot gewann in 60 % der Fälle gegen eine Version, die mit menschlicher Aufsicht trainiert worden war. Laut der Studie ist das ein deutlicher Hinweis darauf, dass ICM nicht nur in der Forschung funktioniert, sondern auch auf Produktionsniveau skalierbar ist.
Die Methode hat allerdings auch Grenzen. ICM funktioniert nur bei Konzepten, die dem Modell bereits bekannt sind. Bei einem Test mit Gedichten, bei dem das Modell eine persönliche Präferenz für Sonnengedichte lernen sollte, versagte der Algorithmus - die Leistung war nicht besser als Zufallsraten. Zudem funktioniert die Methode nicht gut mit langen Eingaben, da viele Beispiele in das Kontextfenster des Modells passen müssen.
Laut den Forschern könnte ICM ein Weg sein, wie Sprachmodelle künftig besser auf menschliche Werte abgestimmt werden – ganz ohne menschliche Schwächen wie Vorurteile oder Überforderung bei komplexen Aufgaben. Gerade bei solchen Aufgaben, bei denen selbst Menschen keine zuverlässigen Labels liefern können, könnte das Verfahren künftig eine zentrale Rolle spielen. Mitautor des Papers ist unter anderem Sicherheitsforscher Jan Leike, der OpenAIs Superalignment-Team kurz vor seiner kompletten Auflösung verließ und das Unternehmen für seine Ausrichtung kritisierte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.