Anthropic-Studie: Nutzer hinterfragen polierte KI-Ergebnisse seltener

Kurz & Knapp
- Anthropic hat mit dem "AI Fluency Index" knapp 10.000 anonymisierte Claude-Gespräche analysiert und dabei ein Muster identifiziert: Je polierter die KI-Ergebnisse wirken, desto seltener prüfen Nutzer deren Richtigkeit.
- In Chats mit Ergebnissen wie kleinen Apps oder Dokumenten sank die kritische Prüfung messbar, etwa beim Faktencheck (-3,7 Prozentpunkte) oder beim Hinterfragen der Argumentation (-3,1pp).
- Der stärkste Befund betrifft das Iterieren: 85,7 Prozent der Gespräche zeigten Anzeichen schrittweiser Verfeinerung auf. Nutzer, die iterierten, hinterfragten Claudes Argumentation 5,6-mal häufiger und identifizierten fehlenden Kontext 4-mal häufiger.
Anthropic hat einen neuen "AI Fluency Index" veröffentlicht, der misst, wie kompetent Menschen mit KI-Werkzeugen umgehen. Ein zentraler Befund: Wenn Claude polierte Ergebnisse liefert, sinkt die kritische Aufmerksamkeit der Nutzer.
Dass immer mehr Menschen KI-Tools im Alltag einsetzen, sagt wenig darüber aus, ob sie das auch sinnvoll tun. Genau diese Frage versucht Anthropic mit seinem neuen AI Fluency Index zu beantworten und analysierte dafür im Januar knapp 10.000 anonymisierte Gespräche mit Claude.
Das Unternehmen identifiziert dabei verschiedene Muster. Eines davon: Je ausgefeilter die Ergebnisse der KI wirken, desto seltener prüfen Nutzer deren Richtigkeit. 12,3 Prozent der generierten Gespräche beinhalteten sogenannte Artefakte, also von Claude erzeugte Produkte wie Code, Dokumente oder interaktive Tools.
In diesen Dialogen machten die Nutzer zwar am Anfang genauere Vorgaben. Doch diese anfängliche Sorgfalt schlug sich nicht in größerer kritischer Prüfung nieder.
Im Gegenteil: In Artefakt-Gesprächen identifizierten Nutzer seltener fehlenden Kontext (-5,2 Prozentpunkte), prüften seltener Fakten (-3,7pp) und hinterfragten seltener Claudes Argumentation (-3,1pp). Dabei hat Claude laut Anthropics eigenem Economic Index gerade bei den komplexesten Aufgaben die größten Schwierigkeiten.
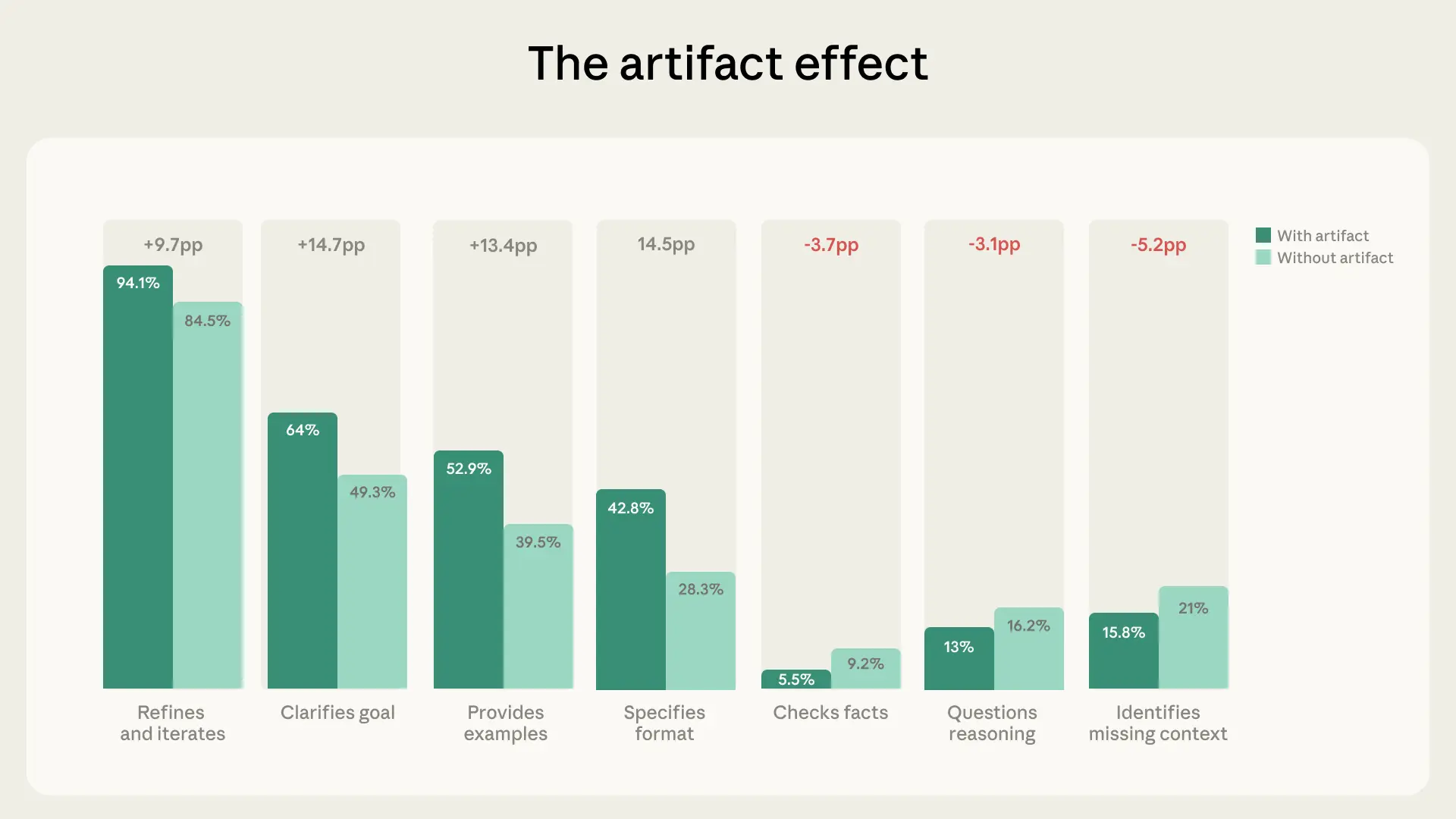
Anthropic nennt mehrere mögliche Erklärungen: Wenn ein Ergebnis fertig aussieht, behandeln Nutzer es möglicherweise auch als fertig. Es könne auch sein, dass bei Artefakt-Aufgaben wie dem Design einer Benutzeroberfläche Faktenpräzision weniger relevant sei als Ästhetik oder Funktionalität. Oder die Evaluation finde außerhalb des Chats statt, etwa durch das Testen von Code in einer anderen Umgebung.
Wer länger im Gespräch bleibt, nutzt KI kompetenter
Der stärkste Befund des Berichts betrifft das Verhältnis zwischen Iteration und allen anderen Kompetenz-Indikatoren. 85,7 Prozent der untersuchten Gespräche zeigten Anzeichen von Iteration und Verfeinerung, also ein schrittweises Weiterentwickeln der Ergebnisse statt ein bloßes Akzeptieren der ersten Antwort.
Diese iterativen Gespräche wiesen im Schnitt 2,67 zusätzliche Kompetenz-Verhaltensweisen auf, etwa doppelt so viele wie nicht-iterative Gespräche mit 1,33. Besonders deutlich war der Unterschied bei der kritischen Prüfung: Nutzer, die iterierten, hinterfragten Claudes Argumentation 5,6-mal häufiger und identifizierten fehlenden Kontext 4-mal häufiger.
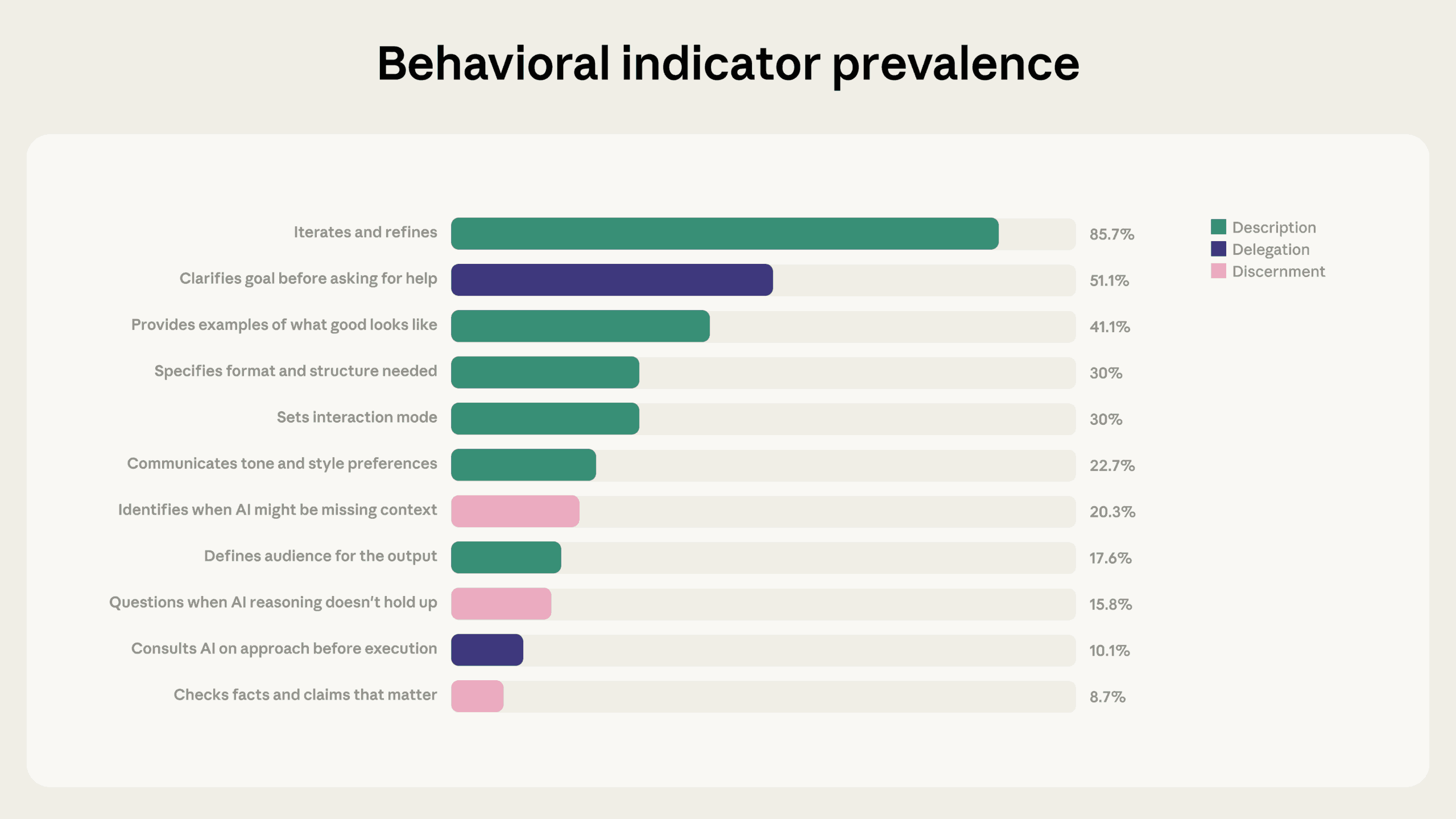
Zumindest das umfassende Iterieren im fortlaufenden Chat stößt jedoch auf ein technisches Dilemma: Zahlreiche Studien zeigen, dass KI-Ausgaben schlechter werden, wenn sich zu viel irrelevanter Kontext im Chatfenster ansammelt. Je länger ein Gespräch dauert, desto mehr läuft das Kontextfenster voll. KI-Kompetenz heißt also gezieltes Fragen und Verfeinern innerhalb eines Themas, ausgehend von einem starken ersten Ergebnis, aber auch zu wissen, wann ein Chatwechsel nötig ist; sogenanntes Context Engineering (heise KI Pro).
Der Bericht deckt auch eine Prompting-Lücke auf: In nur 30 Prozent der Gespräche teilten Nutzer Claude mit, wie die Interaktion ablaufen solle, etwa durch Anweisungen wie "Widersprich mir, wenn meine Annahmen falsch sind" oder "Erkläre mir deine Argumentation, bevor du mir die Antwort gibst". Solche Vorgaben könnten laut Anthropic die Dynamik des gesamten Gesprächs verändern.
Anthropic formuliert auf Basis der Daten drei Empfehlungen: Nutzer sollten die erste Antwort als Ausgangspunkt statt als Endergebnis behandeln, polierte Ergebnisse gezielt hinterfragen und die Bedingungen der Zusammenarbeit explizit festlegen.
Viele Kompetenz-Dimensionen bleiben unsichtbar
Für die Kategorisierung nutzte Anthropic das sogenannte 4D-AI-Fluency-Framework, das die Professoren Rick Dakan und Joseph Feller in Zusammenarbeit mit dem Unternehmen entwickelt haben. Es definiert 24 Verhaltensweisen, die einen kompetenten Umgang mit KI abbilden sollen. Davon sind allerdings nur 11 direkt in Chat-Gesprächen beobachtbar.
Die übrigen 13, darunter laut Anthropic "einige der folgenreichsten Dimensionen von KI-Kompetenz" wie der ehrliche Umgang mit KI-generierten Inhalten gegenüber Dritten, finden außerhalb der Chat-Oberfläche statt und lassen sich entsprechend schwer erfassen. Für sie plant das Unternehmen künftig qualitative Methoden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren