AnythingLLM ist ChatGPT für deine Daten
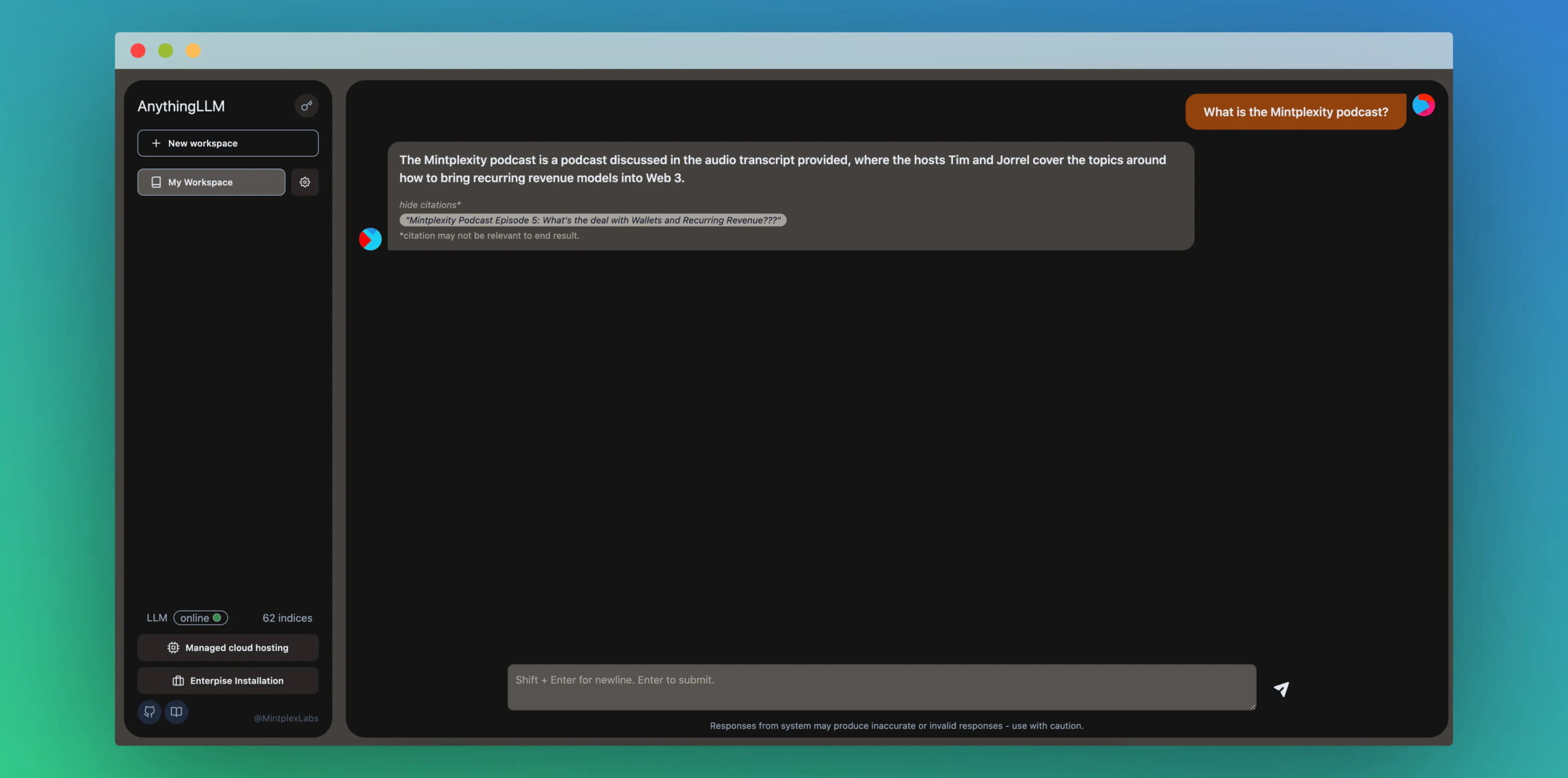
AnythingLLM vereinfacht den Zugang zu einem neuen Trend: Mit eigenen Daten per GPT-Modell zu chatten.
"Das Chatten mit eigenen Dokumenten ist die 'Hello World' der Sprachmodell-Use-Cases - warum sollte man sie nicht zugänglicher machen?", fragt Tim Carambat, Entwickler hinter AnythingLLM. Den gleichen Gedanken verfolgen auch Projekte wie PrivateGPT oder GPT4All, doch anders als diese verzichtet Carambat auf lokal gehostete Sprachmodelle und Vektordatenbanken und konzentriert sich stattdessen auf ein einfach zu bedienendes Chat-Interface, einfache Datensammlung und die Integration von Diensten wie OpenAIs GPT-3.5-turbo, GPT-4 oder Pinecone. Wer möchte, kann diese aber auch weiterhin durch lokale Instanzen ersetzen.
Mit AnythingLLM stellt er eine umfassende Anwendung und Tool-Suite zur Verfügung, die es ermöglicht, jedes Dokument, jede Ressource oder jedes Stück Inhalt in Daten umzuwandeln, die von Sprachmodellen als Referenz während des Chats verwendet werden können. So können Transkripte ganzer YouTube-Kanäle, Fachbücher oder Geschäftsdokumente abgefragt werden. Durch die Verwendung externer Modelle und Datenbanken bleibt AnythingLLM eine Anwendung, die im Hintergrund laufen kann und keine massive Rechenleistung benötigt.
AnythingLLM kommt mit Datenerfassungs-Tools und Chat-Interface
AnythingLLM ermöglicht das Sammeln von Daten aus vordefinierten Quellen oder das Einfügen eigener Daten, bietet einen Cache für einmal bearbeitete Dokumente, um Kosten zu sparen, und die Möglichkeit, mehrere Workspaces einzurichten, die vordefinierte Dokumente gemeinsam nutzen können. Damit können Teams kooperieren und dennoch bestimmte Inhalte exklusiv nur für bestimmte Mitglieder:innen sichtbar sein.
Derzeit bietet AnythingLLM Datenerfassungswerkzeuge für YouTube, Substack, Medium und Gitbooks. Auch URLs und lokale Dokumente können verarbeitet werden. Das System gibt bei Antworten auch die jeweilige Quelle an, wie eine URL.
AnythingLLM ist Open-Source
Neben Pinecone plant Carambat die Unterstützung weiterer Vektordatenbanken und Sprachmodelle zusätzlich zu den OpenAI-Produkten. Die Unterstützung von Chroma wurde kürzlich hinzugefügt. Weitere Integrationen mit Google Drive oder Github Repos sind geplant.
Um AnythingLLM nutzen zu können benötigt man:
- Python 3.8+ (für die Datenerfassung)
- Node16+ (für den lokalen Server)
- yarn/npm
- OpenAI-API-Schlüssel (für Embedding + Chatten)
- Pinecone DB API-Schlüssel oder lokal laufende ChromaDB-Instanz (für die Vektorspeicherung)
AnythingLLM ist Open-Source und auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.