



Apples eigene Benchmarks zeigen, dass Apples LLMs auf dem Gerät und in der Cloud im Vergleich zu anderen KI-Modellen nur durchschnittliche Leistungen erzielen. Um die Leistung für bestimmte Aufgaben zu optimieren, hat das Unternehmen eine Adapter-Strategie - und ChatGPT.
Auf der Worldwide Developers Conference 2024 hat Apple sein neues generatives KI-System "Apple Intelligence" vorgestellt, das in iOS 18, iPadOS 18 und macOS Sequoia integriert ist. Es besteht aus mehreren generativen KI-Modellen, die den Kontext des Nutzers berücksichtigen sollen.
Als Trainingsdaten verwendet Apple lizenzierte Daten, öffentlich zugängliche Daten des Web-Crawlers AppleBot sowie menschlich annotierte und synthetische Daten. Private Nutzerdaten fließen laut Apple nicht in das Training ein.
Apples Server-Modell ist auf Augenhöhe mit GPT-3.5 Turbo
Interne Benchmarks, bei denen die Modelle mit Open-Source- und kommerziellen Modellen vergleichbarer Größe wie GPT-3.5 verglichen wurden, zeigen eine durchschnittliche Leistungsfähigkeit von Apples eigenen KI-Modellen.
Das On-Device-Modell übertrifft mit etwa drei Milliarden Parametern größere Modelle wie Phi-3-mini, Mistral-7B und Gemma-7B. Das Server-Modell liegt gleichauf mit Modellen wie DBRX-Instruct, Mixtral-8x22B und GPT-3.5-Turbo, und ist dabei laut Apple sehr effizient.
Mit GPT-4 kann das Server-Modell nicht mithalten. Neue Wow-Momente sind von Apple Intelligence daher eher nicht zu erwarten. Der Vorteil von Apple Intelligence ist derzeit primär die tiefe Integration in die Betriebssysteme.
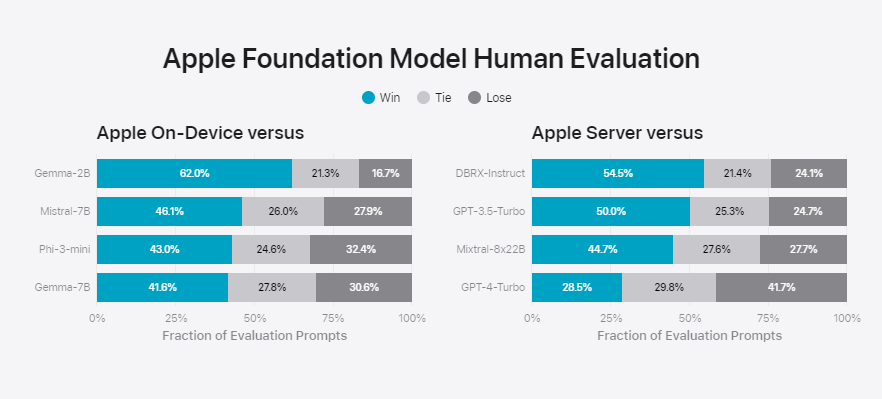
Laut Apple wurden für die oben genannte Evaluation Prompts mit unterschiedlichen Schwierigkeitsgraden in Kategorien wie Brainstorming, Klassifizieren, Beantworten geschlossener Fragen, Kodieren, Extrahieren, mathematisches Denken, Beantworten offener Fragen, Umschreiben, Sicherheit, Zusammenfassung und Schreiben getestet. Die Ergebnisse wurden von Menschen beurteilt.
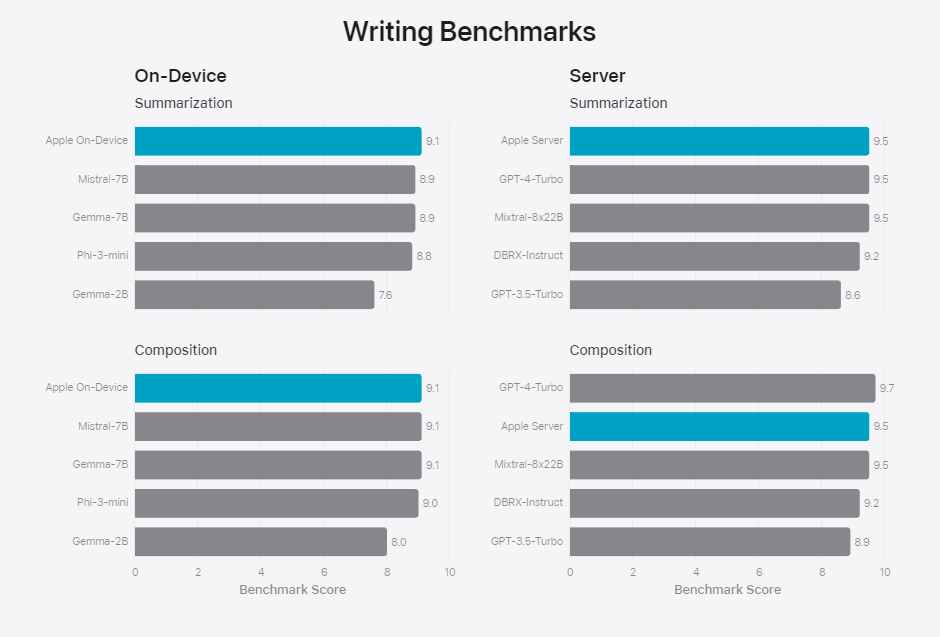
Bei der Bewertung der Schreibleistung auf internen Benchmarks speziell für Zusammenfassung und Zusammenstellung schneiden die On-Device-Modelle von Apple besser ab als größere Modelle. Das Server-Modell liegt gleichauf mit GPT-4 Turbo. Diese Ergebnisse beziehen sich nur auf die Leistung der Modelle ohne funktionsspezifische Adapter (siehe unten).
Für mehr KI-Leistung: Apple setzt auf Adapter und ChatGPT
Um die Leistung der Basismodelle zu steigern, setzt Apple auf eine Adapter-Strategie. Adapter sind kleine neuronale Netzwerkmodule, die für bestimmte Aufgaben wie Zusammenfassungen oder Rechtschreibprüfung optimiert sind und vom Basismodell nach einem Finetuning für diese Aufgabe angesteuert werden können.
Video: Apple
Laut Apple können Adapter die Basismodelle dynamisch und speichereffizient für spezifische Aufgaben optimieren, ohne dass das allgemeine Modellwissen verloren geht.
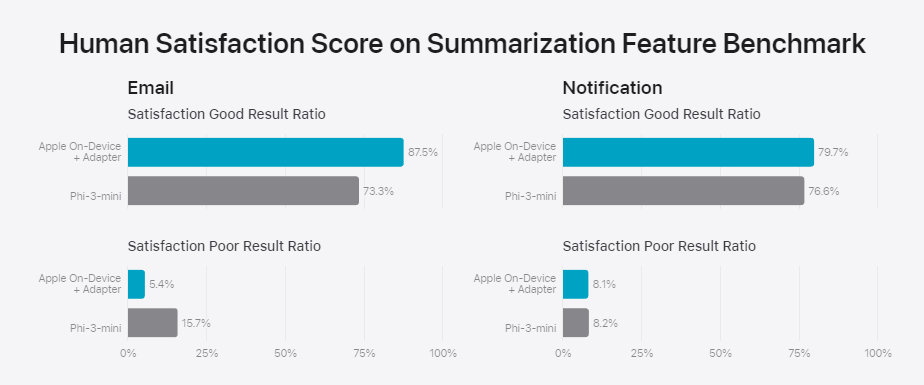
Bei Zusammenfassungen von E-Mails und Benachrichtigungen schlagen Apples On-Device-Modell mit Adapter Microsofts Phi-3-mini teils deutlich. Insbesondere die Anzahl schlechter E-Mail-Zusammenfassungen ist geringer.
Ansonsten setzt Apple auf die Partnerschaft mit OpenAI und die Integration von ChatGPT, um die Fähigkeiten von Apple Intelligence zu erweitern. Durch die Integration von ChatGPT in iOS und Siri hat Apple Zugriff auf die leistungsstarken multimodalen Modelle von OpenAI, wenn diese benötigt werden, beispielsweise bei schwierigen Schreibaufgaben im Texteditor oder bei komplexen Anfragen an Siri. Wann genau und in welchem Umfang Anfragen an OpenAI ausgelagert werden, ist noch unklar.