
Update vom 24. April:
Microsoft hat die Phi-3-Familie offiziell vorgestellt. Phi-3-mini mit 3,8 Milliarden Parametern ist ab sofort auf Microsoft Azure AI Studio, Hugging Face und Ollama verfügbar, auch in einer Variante mit bis zu 128.000 Token Kontextlänge.
Die Modelle sind für Instruktionen optimiert und verwenden die ONNX Runtime mit Unterstützung für Windows DirectML und NVIDIA GPUs. In den nächsten Wochen folgen Phi-3-small (7 Milliarden Parameter) und Phi-3-medium (14 Milliarden).
Die ressourcenschonenden Phi-3-Modelle eignen sich laut Microsoft für Szenarien mit begrenzter Rechenleistung, niedriger Latenz oder wenn niedrige Kosten entscheidend sind und ermöglichen ein einfacheres Feintuning.
Ursprünglicher Artikel vom 23. April:
Gerade erst hat Metas Llama 3 neue Maßstäbe für Open-Source-Modelle gesetzt. Microsofts Phi 3 soll sie schon wieder übertreffen - zumindest auf dem Papier. Microsoft setzt dabei auf das Phi-Merkmal: Datenqualität.
Microsoft Research hat ein neues, kompaktes Sprachmodell namens Phi 3 entwickelt, das internen Tests zufolge die Leistung wesentlich größerer Modelle wie Mixtral 8x7B und GPT-3.5 erreicht. Die Kontextlänge liegt bei 128K.
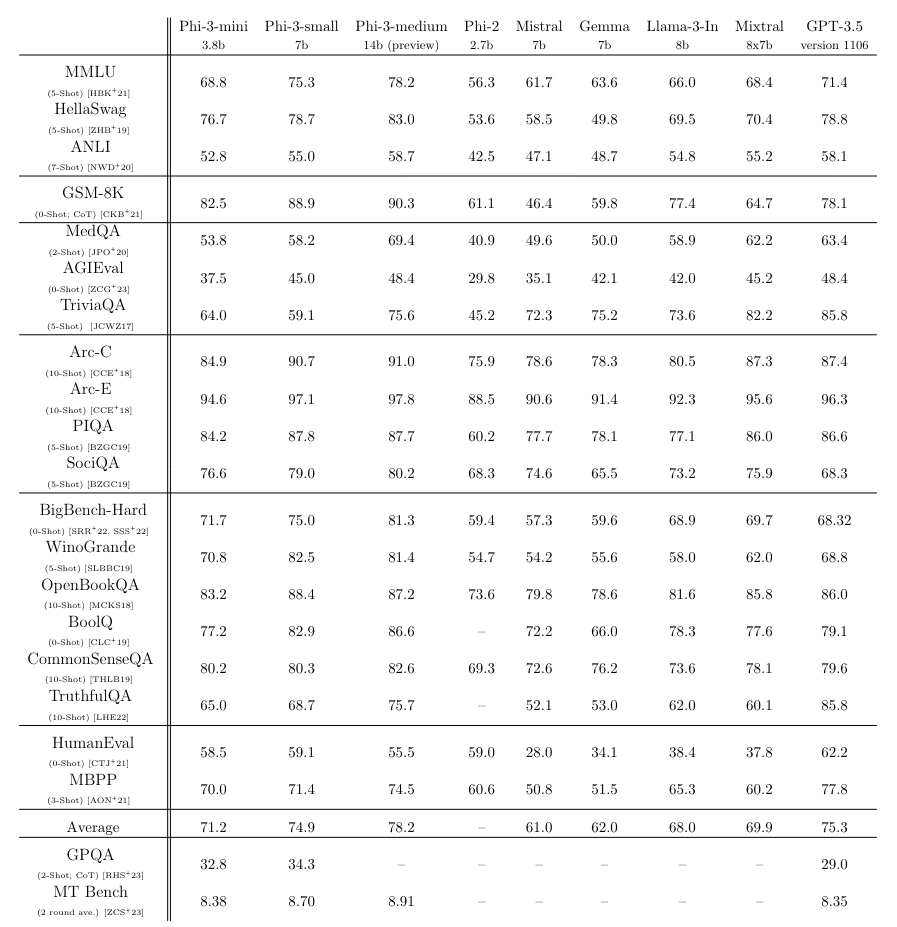
Das Modell Phi-3-mini, das nur 3,8 Milliarden Parameter umfasst, soll beispielsweise im Sprachverständnis-Benchmark MMLU 69 Prozent und im MT-Benchmark 8,38 Punkte erreichen.
Dank seiner geringen Größe kann Phi 3 auf einem handelsüblichen Smartphone mit nur 1,8 GB Speicher lokal ausgeführt und auf 4 Bit quantisiert werden. Auf einem iPhone 14 mit A16-Chip erreicht das Modell laut Microsoft mehr als 12 Token pro Sekunde.

"Es ist, als würde man einen Supercomputer in ein Klapphandy quetschen - nur dass er nicht das Handy, sondern mit seiner winzigen, aber mächtigen Sprachkompetenz das Internet zerstört", lassen die Entwickler das Modell scherzhaft auf die Frage antworten, wie ein KI-Modell auf ChatGPT-Niveau auf einem Smartphone laufen kann.
Maximale Datenqualität im Training
Das Geheimnis der Leistungsfähigkeit von Phi 3 liegt laut Microsoft ausschließlich im Trainingsdatensatz. Dieser besteht aus stark gefilterten Web- und synthetischen Daten und ist eine Weiterentwicklung der Trainingsmethode, die bereits bei den Vorgängern Phi 2 und Phi 1 zum Einsatz kam.
Microsoft betont, dass die Leistung allein durch die Optimierung des Trainingsdatensatzes erreicht wurde. Anstatt Webdaten mit Informationen wie Sportergebnissen zu "verschwenden", wurde der Datensatz näher an das "Datenoptimum" für ein kompaktes Modell gebracht, indem der Schwerpunkt auf Wissen und Schlussfolgerungsfähigkeiten gelegt wurde.
In der ersten Phase des Vortrainings werden hauptsächlich Webdaten verwendet, damit das Modell allgemeines Wissen und Sprachverständnis entwickeln kann. In der zweiten Trainingsphase werden stark gefilterte, qualitativ hochwertige Webdaten mit ausgewählten synthetischen Daten kombiniert, um die Leistung des Modells in spezifischen Bereichen wie Logik und Nischenanwendungen zu optimieren.
Mit den Phi-Modellen will Microsoft qualitativ hochwertige, aber wesentlich effizientere und kostengünstigere KI-Modelle ermöglichen. Gerade Microsoft, das KI über die eigenen Windows- und Office-Produkte sowie die Suche skalieren will, benötigt in der Ausführung kostengünstige Modelle, um aus generativer KI ein Geschäftsmodell zu machen.
Microsofts effizientes KI-Modell Phi 3 schlägt Llama 3 und das freie ChatGPT in Benchmarks
Phi-3-small mit 7 Milliarden Parametern und Phi-3-medium mit 14 Milliarden Parametern, die beide mit 4,8 Billionen Token trainiert wurden, schneiden in den Benchmarks noch besser ab als Phi-3-mini.
Sie erreichen 75 bzw. 78 Prozent im MMLU-Benchmark und 8,7 bzw. 8,9 Punkte im MT-Benchmark. Damit sind sie nicht weit entfernt von deutlich größeren Modellen wie das kürzlich veröffentlichte Llama 3 von Meta mit 70 Milliarden Parametern. Modelle derselben Klassen übertreffen die Phi-Modelle deutlich.
Die in der Anwendung wahrgenommene Leistung und die in Benchmarks erzielte Punktzahl müssen jedoch nicht unbedingt übereinstimmen. Es bleibt daher abzuwarten, inwieweit das Modell von der Open-Source-Community tatsächlich angenommen wird.
Um der Open-Source-Community den größtmöglichen Nutzen aus Phi 3 zu ermöglichen, verwendet Phi 3 laut Microsoft eine ähnliche Blockstruktur und denselben Tokenizer wie das Llama-Modell von Meta. Dadurch sollen alle für die Llama-2-Modellfamilie entwickelten Pakete direkt an Phi-3-mini angepasst werden können.
Als Schwäche von Phi-3-mini nennt Microsoft die geringere Kapazität für Faktenwissen im Vergleich zu größeren Modellen, z.B. im TriviaQA Benchmark. Dies könne jedoch durch die Integration einer Suchmaschine kompensiert werden. Außerdem beschränkt sich das Training hauptsächlich auf die englische Sprache.
Hinsichtlich der Sicherheit habe Microsoft einen mehrstufigen Ansatz mit Alignment-Training, Red Teaming, automatisierten Tests und unabhängigen Prüfungen gewählt. Dadurch seien potenziell schädliche Antworten deutlich reduziert worden.


