
- Mixtral 8x7B Paper ergänzt
Update vom 9. Januar 2024:
Mistral AI hat das Mixtral 8x7B Paper veröffentlicht, das die Architektur des Modells detailliert beschreibt. Es enthält auch umfangreiche Benchmarks im Vergleich zu LLaMA 2 70B und GPT-3.5.
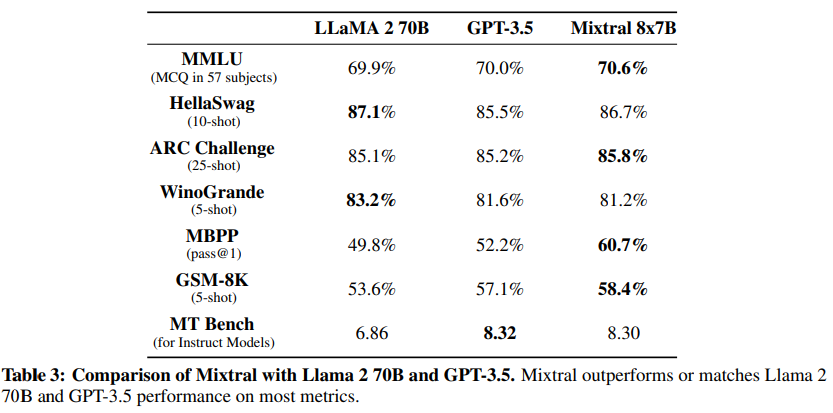
Im viel zitierten Sprachverständlichkeits-Benchmark MMLU liegt Mixtral vor den beiden genannten Modellen. Größere Modelle wie Gemini Ultra oder GPT-4 erreichen hier je nach Prompting-Verfahren zwischen 85 und 90 Prozent.
Im LMSys Leaderboard, in dem Menschen die Antworten der KI bewerten, liegt Mixtral 8x7b knapp vor Claude 2.1 und GPT-3.5 sowie Googles Gemini Pro. Auch hier führt GPT-4 deutlich.
Damit bestätigt sich das Bild der letzten Monate: Ein Modell auf GPT-3.5-Niveau oder sogar leicht darüber zu erreichen, ist für viele Organisationen relativ einfach möglich. GPT-4 bleibt weiter unerreicht.
Ursprünglicher Artikel vom 11. Dezember 2023:
Mistral AI veröffentlicht sein neues Sprachmodell Mixtral 8x7B und gibt in einem neuen Blog-Beitrag Details zur Leistung. Es soll das aktuell beste offene Sprachmodell sein.
Ende letzter Woche veröffentlichte Mistral ein neues Sprachmodell via Torrent-Link. Heute hat das Unternehmen mehr Details zum Mixtral 8x7B-Modell veröffentlicht, sowie einen API-Service und neue Finanzierung angekündigt.
Nach Angaben der Firma ist Mixtral ein sparsames Mixture-of-Experts-Modell (SMoE) mit offenen Gewichten, lizenziert unter Apache 2.0. Eine ähnliche Architektur nutzt Gerüchten zufolge OpenAI auch für GPT-4. Mixtral wählt bei einer Anfrage aus den acht Parametersätzen zwei aus und verwendet nur einen Bruchteil der Gesamtzahl der Parameter pro Inferenz, was Kosten und Latenz reduziert.

Konkret hat Mixtral 45 Milliarden Parameter, verwendet für die Inferenz jedoch nur zwölf Milliarden Parameter pro Token. Es ist das bisher größte Modell des Start-ups, das bereits im Herbst das verhältnismäßig leistungsfähige Mistral 7B veröffentlichte.
Mixtral 8x7B übertrifft Metas LLaMA 2 70B
Laut Mistral übertrifft Mixtral so Llama 2 70B in den meisten Benchmarks und bietet eine sechsmal schnellere Inferenz. Außerdem soll es wahrheitsgetreuer und weniger voreingenommen sein als das Modell von Meta. Damit ist es laut Mistral das leistungsstärkste Modell mit offenen Gewichten und bietet im Vergleich zu anderen Modellen wie GPT-3.5 das beste Preis-Leistungs-Verhältnis bei vergleichbarer Leistung.
Mixtral verarbeitet bis zu 32.000 Token Kontext, unterstützt Englisch, Französisch, Italienisch, Deutsch und Spanisch und kann Code schreiben.
Mistral veröffentlicht Instruct-Variante von Mixtral
Neben dem Basismodell Mixtral 8x7B veröffentlicht Mistral auch Mixtral 8x7B Instruct. Das Modell wurde durch überwachtes Feintuning und Direct Preference Optimization (DPO) für das genaue Befolgen von Anweisungen optimiert. In MT-Bench erreicht es eine Punktzahl von 8,30 und ist damit das beste Open-Source-Modell mit einer Leistung, die mit GPT-3.5 vergleichbar ist.
Mixtral ist als Beta-Version auf der Mistral-Plattform verfügbar. Dort sind auch der kleinere Mistral 7B und ein leistungsfähigeres Prototypenmodell verfügbar, das GPT-3.5 übertreffen soll.



