Apple zeigt Alternative zu Diffusionsmodellen für Video-KI

Mit STARFlow-V präsentiert Apple ein Video-Generierungsmodell, das einen anderen technischen Ansatz als Sora, Veo oder Runway verfolgt. Das Modell soll besonders bei längeren Videos stabiler arbeiten. Während fast alle führenden Video-KIs auf Diffusionsmodellen aufbauen, nutzt STARFlow-V einen Ansatz namens "Normalizing Flows."
An diesem Ansatz arbeitet Apple schon seit mindestens letztem Jahr und hatte in diesem Sommer zur Bildgenerierung mittels Normalizing Flows bereits ein Paper veröffentlicht. Jetzt hat Apple das Konzept auf Videos übertragen. Demzufolge ist STARFlow-V das erste Modell dieser Art, das mit Diffusionsmodellen mithalten kann. Das Modell erreiche vergleichbare visuelle Qualität bei ähnlicher Geschwindigkeit, zumindest bei einer recht niedrigen Auflösung von 640 × 480 Pixeln bei 16 Bildern pro Sekunde.
Diffusionsmodelle lernen, aus verrauschten Bildern schrittweise saubere Videos zu erzeugen. Dafür fügen sie während des Trainings künstliches Rauschen zu echten Videos hinzu und bringen dem Modell bei, dieses Rauschen wieder zu entfernen.
Normalizing Flows hingegen lernen eine direkte mathematische Umwandlung zwischen zwei Zuständen, von einfachem Zufallsrauschen zu komplexen Videodaten und zurück. Das Training erfolgt in einem Durchgang statt in vielen kleinen Schritten.
Einmal trainiert, kann das Modell direkt aus Zufallswerten ein Video erzeugen, ohne mehrfach hin- und herrechnen zu müssen. Apple argumentiert, dass dieser Ansatz effizienter trainiert werden kann und weniger anfällig für bestimmte Fehler ist, die bei der schrittweisen Generierung auftreten.
Das Modell kann ohne Änderungen für verschiedene Aufgaben genutzt werden. Text-zu-Video ist die Standardanwendung, für Bild-zu-Video behandelt das System das erste Bild als Vorgabe und generiert die Fortsetzung, mit Video-zu-Video lassen sich etwa Objekte hinzufügen oder entfernen.
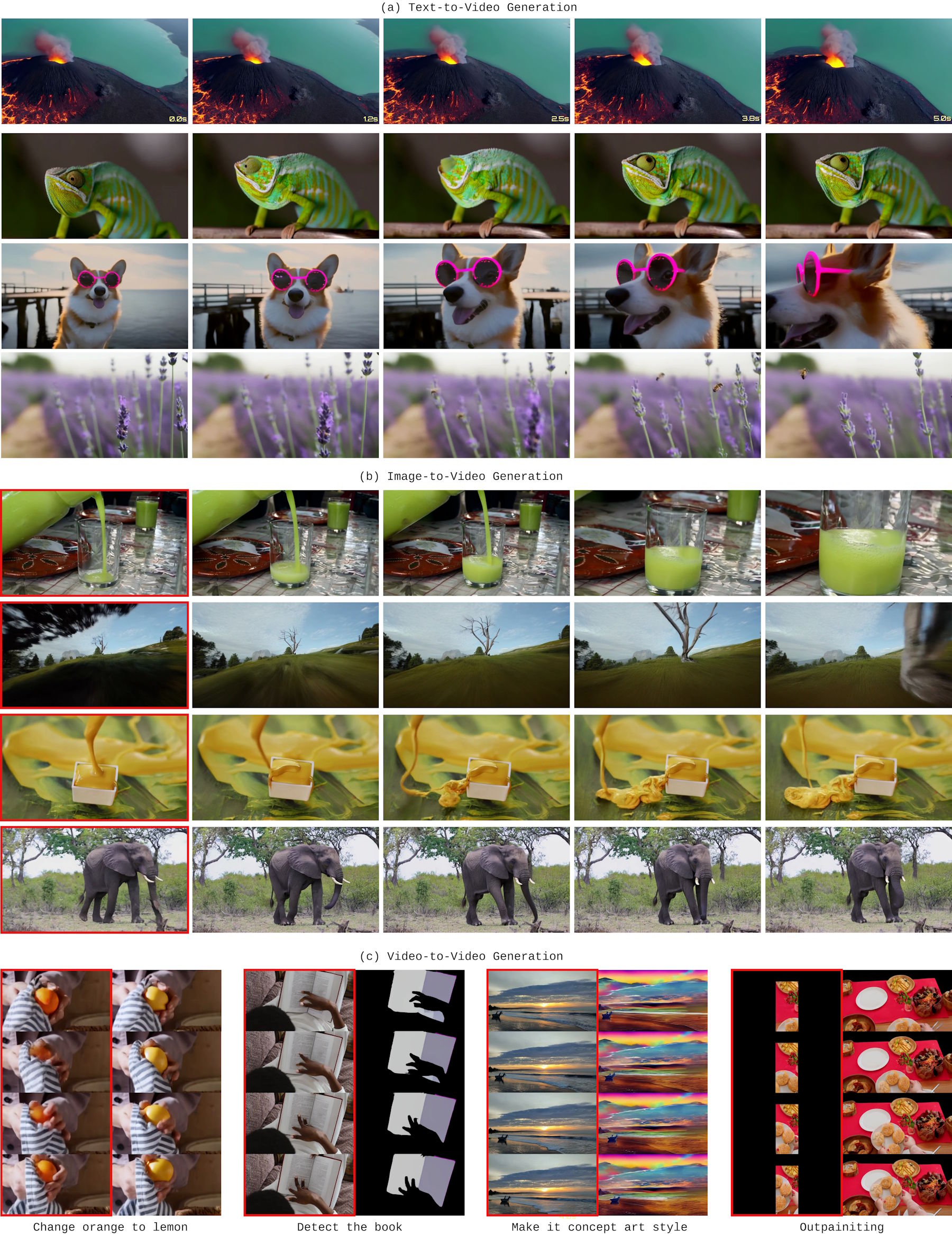
Für längere Videos als beim Training nutzt das Modell ein Sliding-Window-Verfahren: Es generiert einen Abschnitt, merkt sich die letzten Frames und setzt dann nahtlos fort. In den veröffentlichten Demo-Clips mit bis zu 30 Sekunden Länge zeigt sich über diesen Zeitraum jedoch nicht sonderlich viel Varianz.
Architektur vermeidet Fehleranhäufung und beschleunigt Generierung
Die Generierung längerer Sequenzen stellt Video-KIs jedoch vor große Herausforderungen. Wenn ein Modell Frame für Frame erzeugt, können sich kleine Fehler aufaddieren. STARFlow-V begegnet diesem Problem mit einer zweigeteilten Architektur. Ein Teil kümmert sich um die zeitliche Abfolge über mehrere Frames hinweg, ein anderer verfeinert die Details innerhalb einzelner Frames.
Beim Training mischt Apple den Daten absichtlich eine kleine Menge Rauschen bei, um die Normalizing‑Flow‑Optimierung zu stabilisieren. Die Nebenwirkung: Die erzeugten Videos können leicht körnig wirken. Um das auszugleichen, wurde parallel ein kleines, kausales Denoiser‑Netz mittrainiert, das das Rest‑Rauschen nach der Generierung entfernt und dabei die zeitliche Konsistenz der Bewegungen bewahrt.
Außerdem hat Apple die Geschwindigkeit optimiert. Ursprünglich benötigte das Modell mehr als 30 Minuten für ein fünf Sekunden langes Video. Durch Parallelisierung und die Nutzung von Informationen aus dem vorherigen Frame ist die Generierung etwa 15 Mal schneller geworden.
STARFlow-V wurde mit 70 Millionen Text-Video-Paaren trainiert, die aus dem Panda-Datensatz sowie einem hauseigenen Stock-Video-Korpus stammen. Ergänzt wurden sie um 400 Millionen Text-Bild-Paare.
Um detailliertere Eingaben zu erhalten, ließ Apple die ursprünglichen Videobeschreibungen von einem Sprachmodell erweitern; auf eine Originalbeschreibung kamen neun erweiterte Varianten.
Das Training lief über mehrere Wochen auf 96 Nvidia-H100-GPUs. Dabei wurde das Modell schrittweise von 3 auf 7 Milliarden Parameter skaliert, während Auflösung und Videolänge kontinuierlich erhöht wurden.
Besser als andere autoregressive Modelle
Auf dem VBench-Benchmark, der Video-KI-Modelle in 16 Kategorien bewertet, erreicht STARFlow-V einen Wert von bis zu 79,7 Punkten. Das liegt unter führenden Diffusionsmodellen wie Veo 3 mit 85,06 oder HunyuanVideo mit 83,24 Punkten, ist aber deutlich besser als andere autoregressive Modelle.
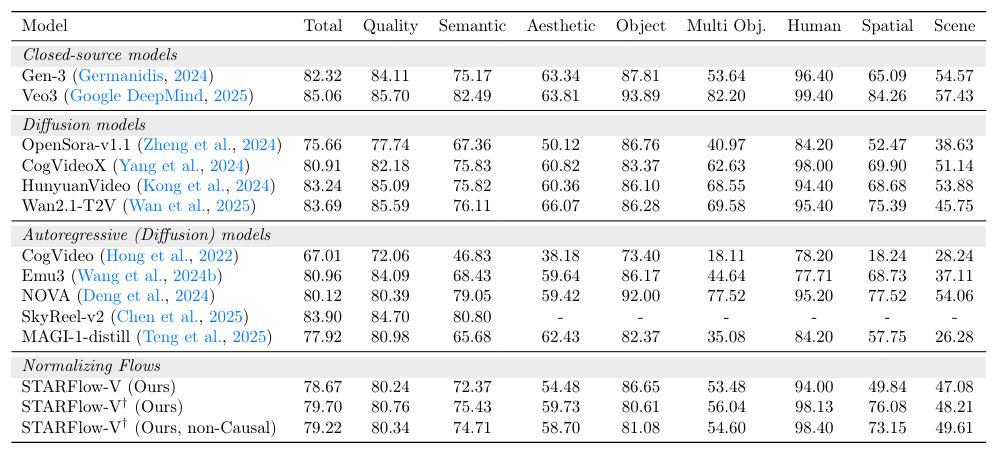
Besonders interessant ist der Vergleich mit anderen Modellen, die ebenfalls Frame für Frame generieren. Das Modell NOVA erreicht nur 75,31 Punkte, Wan 2.1 kommt auf 74,96 Punkte. Diese Modelle zeigen laut Apple deutliche Qualitätsverluste über die Zeit. Nova werde zunehmend unscharf, Alibabas Wan zeige Flackern und Inkonsistenzen.

STARFlow-V soll auch bei 30 Sekunden langen Videos stabil bleiben, obwohl es nur auf 5-Sekunden-Clips trainiert wurde. Apple zeigt Beispielvideos, bei denen konkurrierende Modelle nach wenigen Sekunden verschwimmen oder Farben verfälschen.

Physikalisch unmögliche Szenen
Apple nennt explizit mehrere Probleme. Die Geschwindigkeit reiche bisher nicht für Echtzeit-Anwendungen auf normalen Grafikkarten, außerdem skaliere die Qualität nicht vorhersagbar mit mehr Daten.
Nicht zuletzt erzeugt das Modell physikalisch unmögliche Szenen. In den Beispielen zeigen die Forscher etwa einen Oktopus, der durch Glas gleitet, oder einen Stein, der plötzlich unter einer Ziege auftaucht. Auch kommerzielle Videomodelle wie das kürzlich vorgestellte Runway Gen-4.5 haben weiterhin mit solchen Problemen zu kämpfen, scheinen diese Hürde jedoch etwas besser zu überwinden.

Als nächste Schritte plant Apple schnellere Berechnungsmethoden, kleinere Modellversionen und bessere Trainingsdaten mit Fokus auf physikalisch korrekte Bewegungen. Den Code veröffentlicht Apple auf GitHub, die Modellgewichte sollen bald auf Hugging Face folgen.
Ähnlich zu der Stagnation von Transformer-basierten Sprachmodellen scheinen Diffusions-Videomodelle zwar bereits sehr gute, aber noch ausbaufähige Ergebnisse zu liefern. Apples Normalizing Flows könnten langfristig eine Alternative darstellen, bleiben qualitativ zum jetzigen Zeitpunkt jedoch noch um einiges zurück.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.