Apples eigene KI-Modelle werden von OpenAIs GPT-4o abgehängt
Apple veröffentlicht Leistungsdaten seiner beiden KI-Modelle und öffnet das kleinere System für Entwickler. Die Benchmarks werfen kein gutes Licht auf die LLM-Technik des iPhone-Herstellers.
Das Unternehmen entwickelte zwei Modelle: ein kompaktes 3-Milliarden-Parameter-Modell für Geräte und ein größeres Server-basiertes System. In Apples Benchmarks übertrifft das 3-Milliarden-Parameter-Modell das ähnlich große Qwen-2.5-3B und konkurriert mit den größeren Modellen Qwen-3-4B und Gemma-3-4B.
Das zeigt laut Apple, dass Effizienz-Optimierungen die geringere Modellgröße kompensieren können. Der Unterschied in der Parameterzahl fällt jedoch nur klein aus, weshalb die Behauptungen nicht sonderlich aussagekräftig sind.
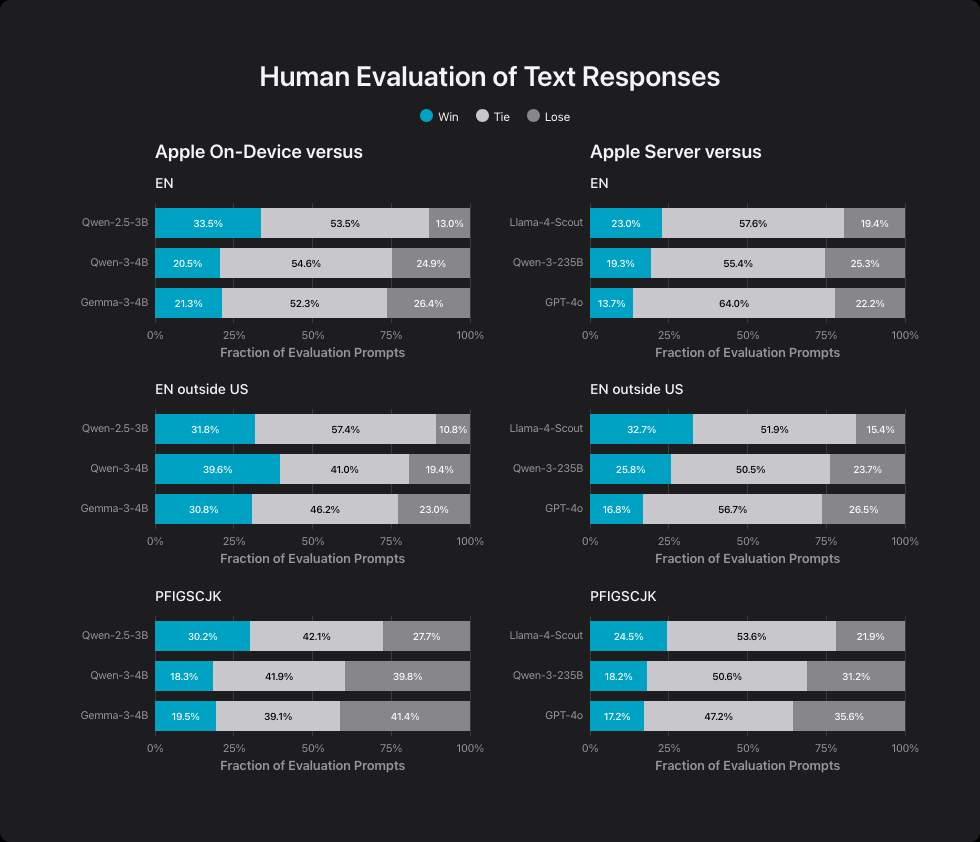
Das Server-basierte Modell erreicht eine ähnliche Leistung wie Llama-4-Scout. Apple hatte bislang keine Parameterzahl offiziell bekannt gegeben, es ähnele in der Größe jedoch Metas Scout-Modell, das insgesamt 109 Milliarden Parameter und 17 Milliarden aktive Parameter vorweist.
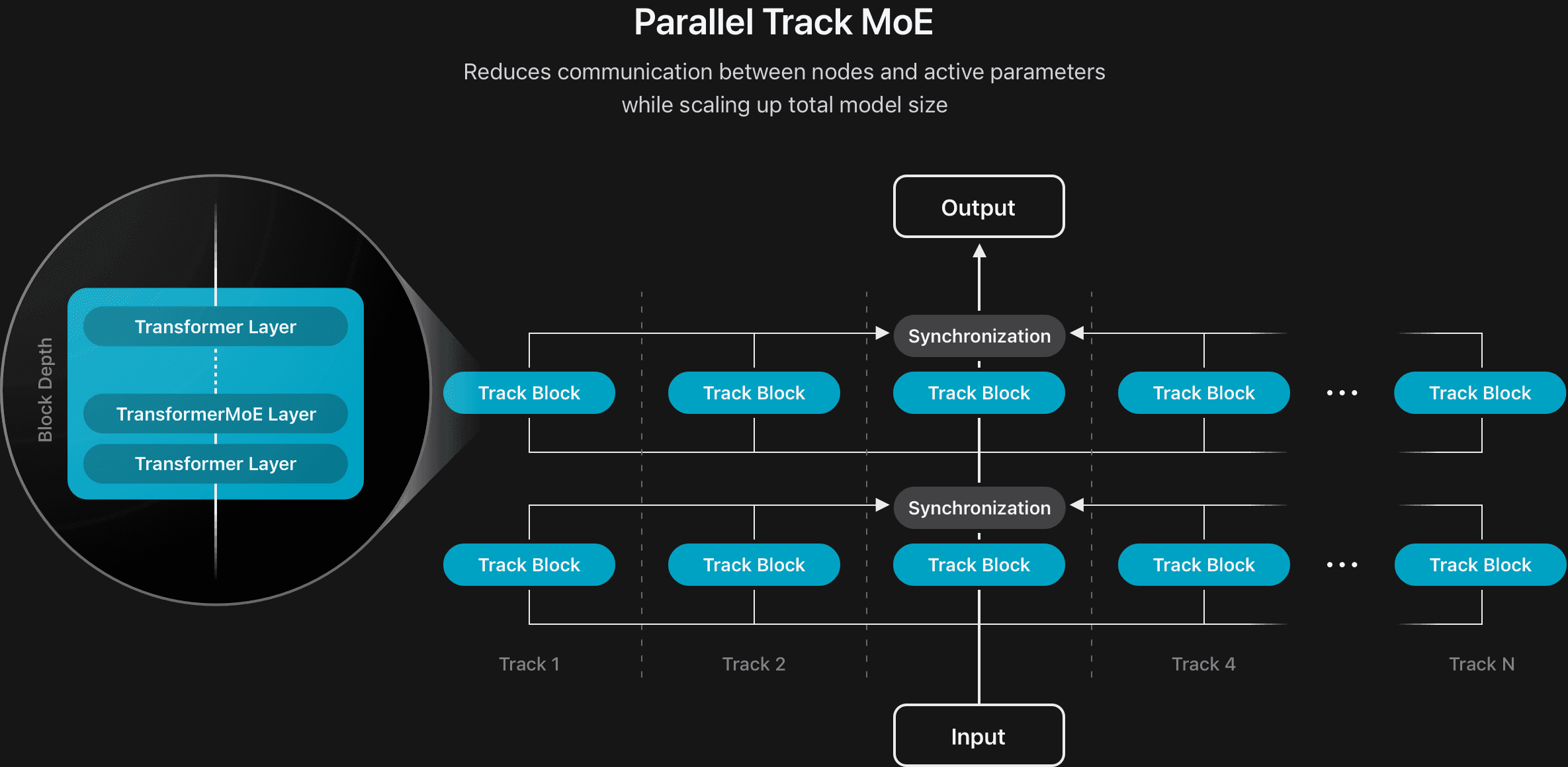
Apple nutzt eine spezielle Architektur namens "parallel track mixture-of-experts", die mehrere kleinere KI-Systeme parallel arbeiten lässt. Gegen deutlich größere Systeme wie Qwen-3-235B und GPT-4o kann es dennoch nicht mithalten.
Bildverständnis mit effizienterem Ansatz
Bei der Bilderkennung konkurriert Apples Gerät-Modell mit InternVL-2.5-4B, Qwen-2.5-VL-3B-Instruct und Gemma-3-4B. Laut Apple schneidet es besser ab als die InternVL- und Qwen-Modelle, kann mit Gemma-3-4B aber nur mithalten. Das Server-Modell übertrifft Qwen-2.5-VL-32B bei weniger als der Hälfte der Rechenoperationen, liegt aber wieder hinter Llama-4-Scout und GPT-4o.
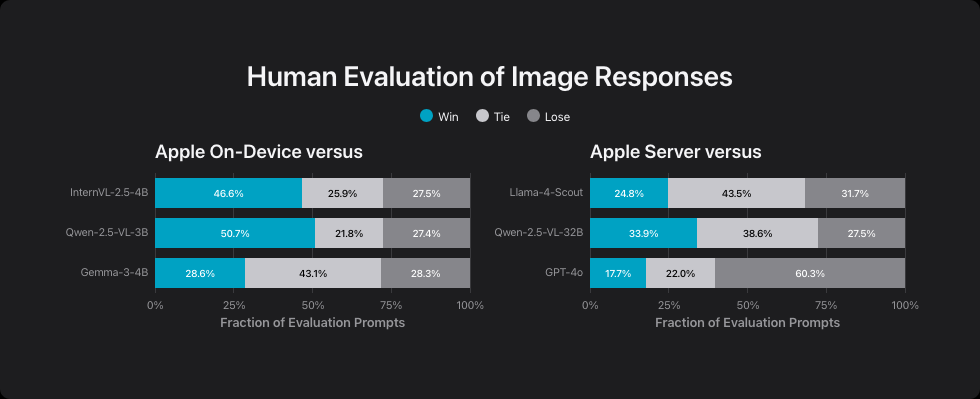
Apple nutzt unterschiedliche Bilderkennungs-Systeme je nach Einsatzbereich. Das Server-Modell verwendet eine KI mit einer Milliarde Parametern, während das Gerät-Modell eine effizientere Version mit 300 Millionen Parametern einsetzt. Beide wurden mit mehr als zehn Milliarden Bild-Text-Kombinationen und 175 Millionen Dokumenten mit eingebetteten Bildern trainiert.
Entwickler erhalten nur Zugang zum kleineren Modell
Apple stellt das 3-Milliarden-Parameter-Modell über ein neues Foundation Models Framework für App-Entwickler:innen zur Verfügung. Das Modell eignet sich laut Apple für Zusammenfassungen, Informationsextraktion und Textverständnis, sei aber nicht als Chatbot für allgemeine Fragen konzipiert.
Das Framework bietet kostenlose KI-Nutzung und ist in Apples Programmiersprache Swift integriert. Entwickler:innen können ihre Datenstrukturen markieren, um automatisch passende Ausgaben zu erhalten. Eine Werkzeug-Funktion ermöglicht die Erweiterung der Modell-Fähigkeiten.
Das leistungsstärkere Server-Modell bleibt hingegen Apple vorbehalten und wird ausschließlich für Apple-Intelligence-Features verwendet. Entwickler haben keinen direkten Zugang zu diesem rechenintensiveren System.
Starke Komprimierung für den Einsatz auf Geräten
Apple komprimierte das Gerät-Modell stark für iPhones und iPads, während das Server-Modell eine spezielle Kompressionstechnik aus der Grafikverarbeitung nutzt. Für die Mehrsprachigkeit erweiterte das Unternehmen das Vokabular von 100.000 auf 150.000 Begriffe.
Das Unternehmen führte kulturspezifische Tests in 15 Sprachen durch, um angemessene Antworten für verschiedene Regionen zu gewährleisten. Trainingsdaten stammen von "Hunderten Milliarden Seiten", die Apple über den Web-Crawler Applebot gesammelt hat, respektiert nach eigenen Angaben aber robots.txt-Dateien zum Ausschluss vom Training und verwende keine Daten von Nutzer:innen.
Wie sich schon im Vorfeld der diesjährigen WWDC abzeichnete, fielen Apples KI-Neuerungen etwa im Vergleich zu Konkurrent Google eher überschaubar aus. Die jetzt veröffentlichten Leistungsvergleiche bestätigen die These, dass Apples Modelle technisch nicht mit denen von Wettbewerbern wie OpenAI mithalten können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.