"Artificial Hivemind": Forscher befürchten kulturelle Verarmung durch homogene KI-Outputs

Eine groß angelegte Untersuchung zeigt, dass unterschiedliche KI-Sprachmodelle bei offenen Aufgaben überraschend ähnliche Antworten produzieren. Die Forscher warnen vor langfristigen Folgen für die menschliche Kreativität.
Wer verschiedene Chatbots mit derselben kreativen Aufgabe füttert, könnte erwarten, dass sie unterschiedliche Ideen liefern. Eine neue Studie von Forschern der University of Washington, Carnegie Mellon University und des Allen Institute for AI zeichnet ein anderes Bild: Die Modelle konvergieren auf dieselben Konzepte, manchmal bis zu wörtlichen Übereinstimmungen.
Die Wissenschaftler um Liwei Jiang prägen dafür den Begriff "Artificial Hivemind" – künstlicher Schwarmgeist. Dieser manifestiert sich laut der Studie auf zwei Ebenen: Einzelne Modelle wiederholen sich selbst, und verschiedene Modelle unterschiedlicher Hersteller produzieren untereinander erstaunlich ähnliche Outputs.
Als Beispiel dient die Aufgabe "Schreibe eine Metapher über Zeit". Die Forscher ließen 25 verschiedene Sprachmodelle jeweils 50 Antworten generieren. Trotz der Vielfalt an Modellfamilien und -größen bildeten sich nur zwei dominante Cluster. Der eine kreist um die Metapher "Zeit ist ein Fluss", der andere um Variationen von "Zeit ist ein Weber". Die Wortwahl kann sich unterscheiden, doch die zugrunde liegenden Konzepte blieben die gleichen.
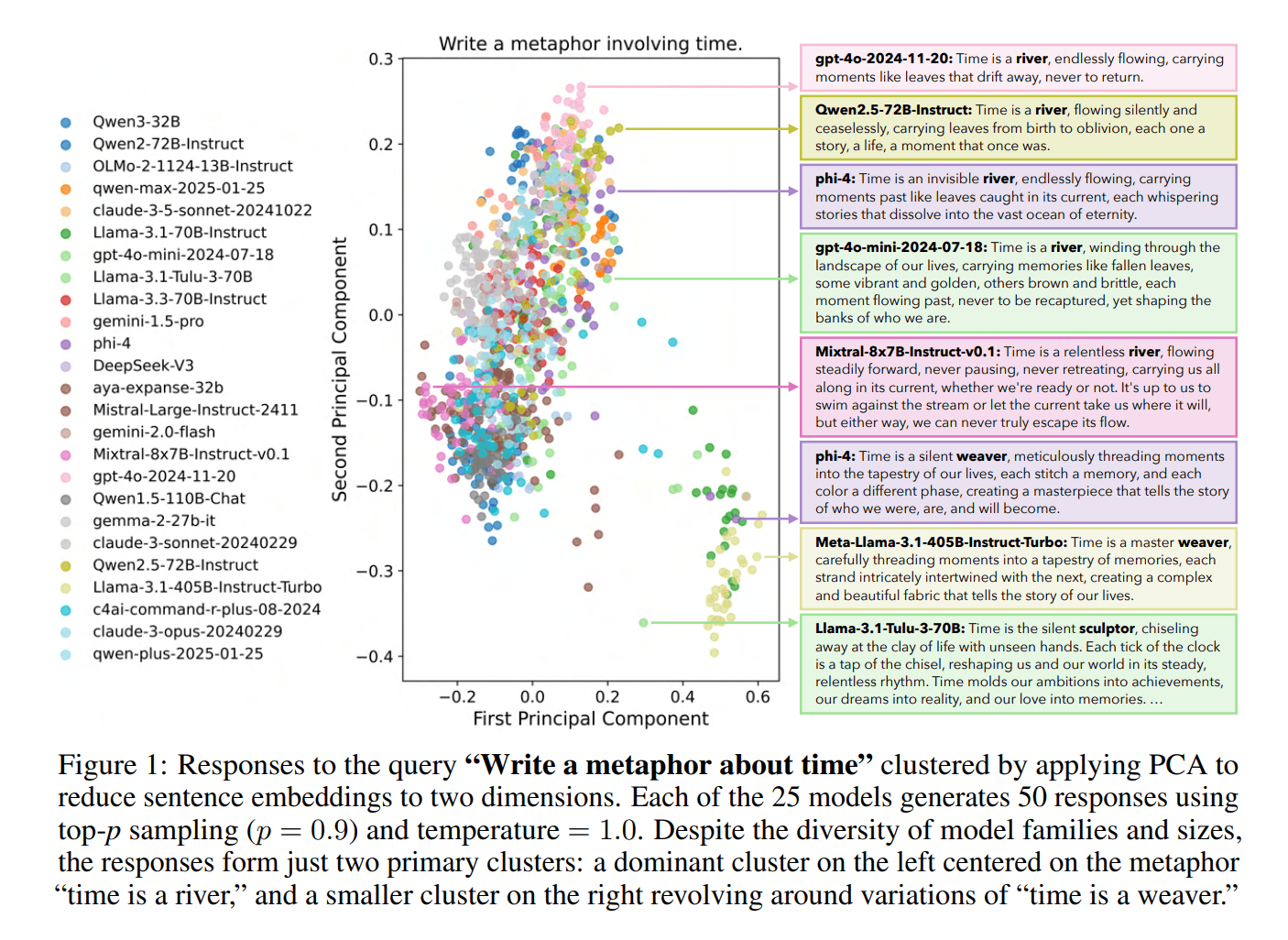
Wörtliche Überlappungen zwischen verschiedenen Modellfamilien
Um diesen Effekt zu messen, führt das Team Infinty-Chat ein, einen Datensatz von echten Nutzeranfragen. Die quantitativen Befunde sind deutlich: Bei fast vier von fünf getesteten Fällen sind die Antworten desselben Modells einander so ähnlich, dass sie sich kaum noch unterscheiden. Die Studie dokumentiert jedoch auch wörtliche Überlappungen zwischen unterschiedlichen Modellfamilien.
Bei der Aufgabe, eine Produktbeschreibung für iPhone-Hüllen zu verfassen, verwendeten DeepSeek-V3 und OpenAIs GPT-4o dieselben Phrasen: "Elevate your iPhone with our", "sleek, without compromising" und "with bold, eye-catching". Die durchschnittliche Ähnlichkeit zwischen diesen beiden Modellen liegt bei 81 Prozent – obwohl sie von verschiedenen Unternehmen auf unterschiedlichen Kontinenten entwickelt wurden. DeepSeek-V3 und Qwens qwen-max-2025-01-25 erreichen 82 Prozent Übereinstimmung.
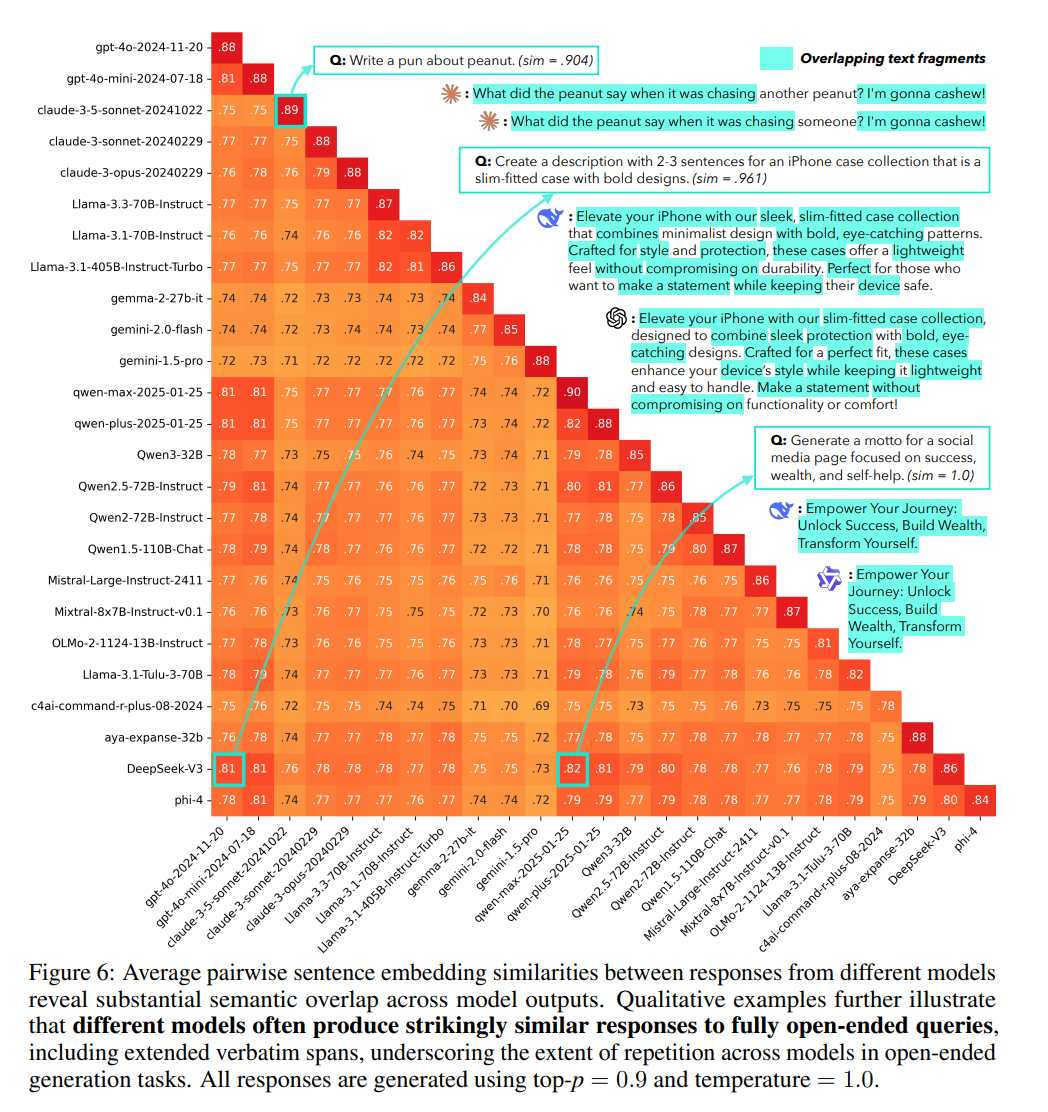
Die genauen Ursachen dieser familienübergreifenden Konvergenz bleiben unklar. Die Forscher spekulieren über geteilte Daten-Pipelines, Kontamination durch synthetische Daten oder überlappende Alignment-Praktiken, betonen aber, dass eine kausale Analyse aussteht.
Warnung vor kultureller Verarmung
Die Autoren fürchten gesellschaftliche Implikationen und warnen vor einer schleichenden Homogenisierung menschlichen Denkens durch wiederholte Exposition gegenüber ähnlichen KI-Outputs. Wenn Milliarden von Nutzern sich zunehmend auf Sprachmodelle für kreative, bildungsbezogene und entscheidungsrelevante Aufgaben verlassen, könnte die Konvergenz auf Modellebene in menschliche Ausdrucksformen übergehen. Die Studie verweist auf bereits existierende Evidenz für messbare Veränderungen in menschlichen Schreibstilen und kreativem Denken seit der breiten Einführung von ChatGPT.
Wenn Sprachmodelle auf dominante kulturelle Ausdrücke konvergieren – etwa westlich-zentrische Metaphern wie "Zeit ist ein Fluss" – könnten außerdem alternative Weltanschauungen und Traditionen unterdrückt werden, so die Befürchtung der Forscher. Eine ähnliche Argumentation lieferte 2024 der KI-Forscher Andrew J. Peterson, der vor einem Wissenskollaps durch den KI-Boom warnte.
Auch für die Praxis synthetischer Datengenerierung hat der Befund Konsequenzen: Multi-Modell-Ansätze und Modell-Ensembles, die eigentlich Diversität fördern sollen, könnten diese Erwartung nicht erfüllen, wenn die zugrundeliegenden Modelle bereits homogen sind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.