AtMan soll das größte Problem von ChatGPT und Co. lösen

Transformer-Modelle sind überall - doch warum schreibt ein ChatGPT eigentlich, was es schreibt? Aleph Alphas AtMan soll Erklärbarkeit für große Transformer-Modelle ermöglichen.
Die 2017 von Google vorgestellte Transformer-Architektur hat in der maschinellen Verarbeitung natürlicher Sprache einen wahren Siegeszug angetreten und wird mittlerweile auch in der Computer Vision und der Bilderzeugung erfolgreich eingesetzt. Varianten von Transformern generieren und analysieren Texte, Bilder, Audio oder 3D-Daten.
Mit der wachsenden Rolle, die auf Transformern basierende KI-Modelle auch in der breiten Gesellschaft spielen, z.B. durch ChatGPT oder in kritischen Anwendungsszenarien wie der Medizin, gibt es einen großen Bedarf an Erklärbarkeit - warum hat ein Modell diese und nicht eine andere Klassifizierung vorgenommen, warum hat es dieses und nicht ein anderes Wort generiert?
Aleph Alphas AtMan soll effiziente XAI für Transformer ermöglichen
Der Fachbegriff dafür: "Explainable AI" oder kurz XAI. Solche Methoden sollen Licht in die Black Box KI bringen und existieren bereits für alle relevanten Architekturen und werden z.B. in der KI-Diagnostik eingesetzt - auch wenn eine aktuelle Studie große Schwächen in den dort verbreiteten Salienz-Methoden aufgezeigt hat.
Auch für Transformer gibt es bereits XAI-Methoden, die aber meist vor den so relevanten großen Modellen wegen zu hohem Rechenbedarf kapitulieren oder nur Klassifikationen etwa von Vision Transformern erklären. Die Textsynthese von Sprachmodellen bleibt ihnen ein Rätsel. Forschende des deutschen KI-Start-ups Aleph Alpha, der TU Darmstadt, des Forschungszentrums Hessian.AI und des Deutschen Forschungszentrums für Künstliche Intelligenz (DFKI) zeigen mit AtMan (Attention Manipulation) eine effiziente XAI-Methode, die mit großen, auch multimodalen Transformer-Modellen arbeitet und sowohl Klassifikationen als auch generative Ausgaben erklären kann.
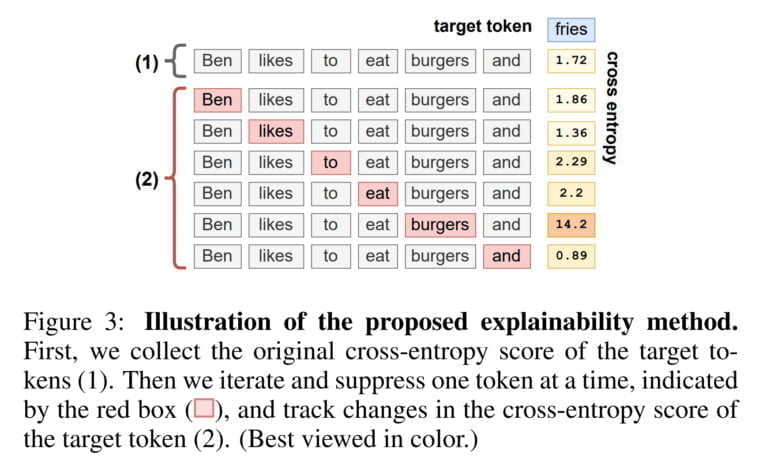
Aleph Alpha verwendet eine Perturbationsmethode, bei der mit Hilfe von Störungen gemessen wird, wie sich ein Token auf die Generierung eines anderen Tokens auswirkt. Ein Beispiel: Der Satz "Ben isst gerne Burger und" wird vom Sprachmodell mit dem Wort "Pommes" fortgesetzt. Mit AtMan berechnet das Team dann einen Wert (Cross-Entropy), der grob angibt, wie stark der Satz insgesamt die Synthese von "Pommes" bestimmt hat. Dann unterdrückt AtMan ein Wort nach dem anderen und vergleicht, wie sich der Wert jeweils ändert. In unserem Beispiel springt der Wert deutlich nach oben, sobald das Wort "Burger" unterdrückt wird, und die XAI-Methode hat somit das Wort identifiziert, das die Synthese von "Pommes" am stärksten beeinflusst hat.
AtMan erreicht im Vergleich Bestwerte
Die Forschenden vergleichen AtMan mit anderen Methoden im QA-Benchmark SQuAD, wo ihre Methode Alternativen wie IxG, IG und Chefer zum Teil deutlich übertrifft. Da AtMan die Perturbationen im Embedding Space auf Token-Ebene durchführt, kann die Methode problemlos in multimodalen Modellen wie Aleph Alphas MAGMA eingesetzt werden, um z.B. Klassifikationen zu erklären. Auch hier zeigt AtMan im VQA-Benchmark von OpenImages eine bessere Performance in der Beantwortung von Fragen zu Bildern.

Das Team untersucht auch, wie AtMan skaliert und kommt zu dem Schluss, dass ihre Methode deutlich besser für den Einsatz in großen Modellen geeignet ist. In einem Test konnte AtMan auf einer einzigen Nvidia A100 80 Gigabyte GPU Tokenlängen von bis zu 1.024 Token in einem Transformer-Modell mit bis zu 17,3 Milliarden Parametern verarbeiten und blieb dabei unter 40 Gigabyte Speicherbedarf. Die Vergleichsmethode Chefer überschreitet die Speichergrenze mit einem mehr als doppelt so hohen Speicherbedarf.
AtMan könne auch parallel ausgeführt werden, so das Team. Gerade bei großen KI-Modellen, die ohnehin auf vielen Grafikprozessoren verteilt laufen, könne so die Laufzeit von AtMan deutlich verkürzt werden.
Wie nützlich sind Erklärungen, wenn sie niemand versteht?
Allerdings hat AtMan noch einige Einschränkungen: "Während AtMan im Vergleich zu gradientenbasierten Methoden das Gesamtrauschen der generierten Erklärung reduziert, bleiben unerwünschte Artefakte bestehen. Es ist unklar, inwieweit dies auf die Methode oder die zugrundeliegende Transformer-Architektur zurückzuführen ist", schreibt das Team. Darüber hinaus erreicht AtMan im VQA-Benchmark mit einem auf 30 Milliarden Parameter skalierten MAGMA-Modell schlechtere Werte als mit der 6-Milliarden-Parameter-Variante.
Dies könnte auf die zunehmende Komplexität des Modells und damit auf die Komplexität der vorliegenden Erklärung zurückzuführen sein, heißt es in dem Papier. "Es ist daher nicht zu erwarten, dass die menschliche Ausrichtung mit den Erklärungen des Modells mit dessen Größe zunimmt" - ein Phänomen, das auch bei großen Sprachmodellen auftreten könne. Folglich sollte auch die gleichzeitige Skalierung der Erklärbarkeit mit der Modellgröße untersucht werden, schließt das Team.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.