Jonathan Kemper
Jonathan ist Technikjournalist und beschäftigt sich stark mit Consumer Electronics. Er erklärt seinen Mitmenschen, wie KI bereits heute nutzbar ist und wie sie im Alltag unterstützen kann.

Mathe braucht Bedenkzeit, Alltagswissen ein gutes Gedächtnis: Forscher optimieren KI-Architektur
Ein Forschungsteam aus Bonn lässt Transformer-Modelle selbst entscheiden, wie oft sie über ein Problem nachdenken, und übertrifft damit deutlich größere Modelle bei Mathematik-Aufgaben.
95 Prozent der britischen Studierenden nutzen KI und die Erfahrungen könnten unterschiedlicher kaum sein
95 Prozent der britischen Studierenden nutzen generative KI. Doch während die einen darin eine Bereicherung sehen, warnen andere vor dem Verlust eigener Denkfähigkeiten. Eine aktuelle Umfrage zeigt ein gespaltenes Bild zwischen Begeisterung, Überforderung und mangelnder Unterstützung durch die Hochschulen.

Read full article about: Google baut Browser-Agenten-Team um und setzt auf Coding-Agenten
Browser-Agenten verlieren den Kampf gegen Coding-Agenten – und Google zieht daraus Konsequenzen. Das Unternehmen strukturiert laut Wired das Team hinter Project Mariner um, seinem KI-Agenten für den Chrome-Browser. Einige Mitarbeiter wurden auf Projekte mit höherer Priorität versetzt. Google bestätigte die Änderungen, betonte aber, dass die entwickelten Fähigkeiten in andere Produkte wie den letztes Jahr angekündigten Gemini Agent einfließen.
Die gesamte Branche setzt zunehmend auf Agentensysteme wie OpenClaw und Kommandozeilen-Tools wie Claude Code. Die Nutzerzahlen von Browser-Agenten bleiben schwach: Auch OpenAI gibt seinen Browser-basierten "ChatGPT Agent" praktisch auf. Das Produkt startete mit vier Millionen wöchentlich aktiven zahlenden Nutzern, fiel aber innerhalb weniger Monate auf unter eine Million. Stattdessen setzt OpenAI nun auf spezialisierte Lösungen wie einen Shopping-Agenten. Auch Anthropic baut seine Coding-Agenten bereits zu künftigen Allzweck-Assistenten aus.
Kommentieren
Quelle: Wired
Read full article about: Google gibt KI-Agenten neue Werkzeuge zum Einkaufen
Google hat das Universal Commerce Protocol (UCP) um Warenkorb-, Katalog- und Identitätsfunktionen erweitert, die KI-Agenten das Einkaufen im Netz erleichtern sollen. Neu ist eine Warenkorb-Option, mit der KI-Agenten mehrere Artikel auf einmal in den Warenkorb eines Shops legen können. Eine Katalog-Funktion erlaubt es Agenten, ausgewählte Echtzeit-Produktdaten wie Preise, Varianten und Verfügbarkeit direkt beim Händler abzurufen. Über eine Identitätsverknüpfung können eingeloggte Käufer auf UCP-Plattformen dieselben Treue- und Mitgliedsvorteile nutzen wie direkt im Shop des Händlers.
Google will UCP in den AI Mode der Suche und die Gemini-App einbauen. Über das Merchant Center sollen künftig auch kleinere Händler leichter angebunden werden. Partner wie Commerce Inc, Salesforce und Stripe planen, UCP auf ihren Plattformen zu unterstützen. Google hatte UCP Anfang des Jahres gemeinsam mit Shopify, Etsy, Wayfair, Target, Walmart und über 20 weiteren Unternehmen wie Visa und Zalando als offenen Standard für KI-gestütztes Shopping vorgestellt.
Kommentieren
Quelle: Google

Qualcomm will Reasoning-KI auf Smartphones bringen
Qualcomm AI Research hat ein modulares System entwickelt, das Reasoning-fähige Sprachmodelle auf Smartphones bringen soll. Dafür werden die wortreichen Denkprozesse der Modelle um den Faktor 2,4 komprimiert.
Read full article about: OpenAI räumt die Modellauswahl in ChatGPT auf
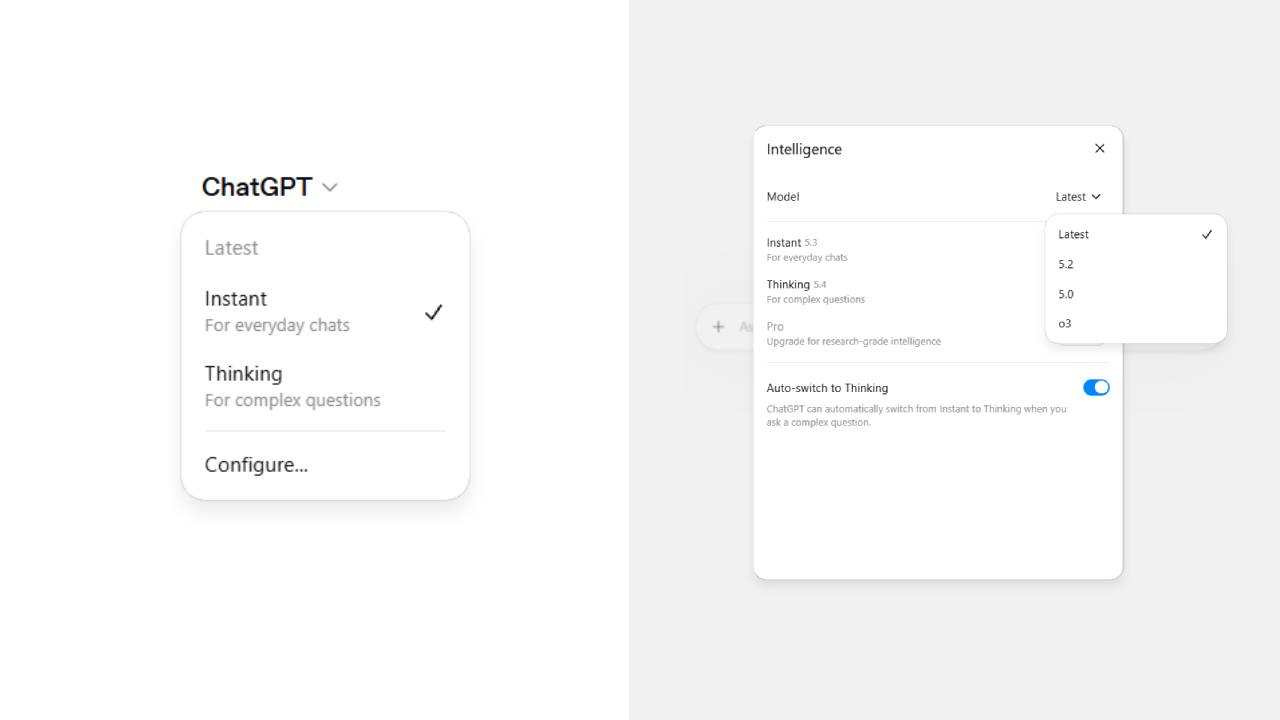
OpenAI hat die Modellauswahl in ChatGPT neu gestaltet. Statt einzelner Modellnamen sehen Nutzer auf den ersten Blick je nach Abonnement bis zu drei Stufen: "Instant" für schnelle, alltägliche Antworten, "Thinking" für komplexere Aufgaben und "Pro" für die leistungsstärksten Modelle. Im neuen Menü lässt sich über ein Dropdown die Modellversion wählen, etwa "Neueste" (momentan 5.4), 5.2, 5.0 oder o3.
Über "Konfigurieren" erreicht man erweiterte Einstellungen. Dort kann man etwa die ehemalige Auto-Funktion aktivieren, damit ChatGPT bei komplexen Fragen von Instant zu Thinking wechselt. Zusätzlich hat OpenAI kürzlich das Wiederholungsmenü unter Antworten vereinfacht und den Persönlichkeitsstil "Nerdy" eingestellt. Außerdem rollt OpenAI GPT-5.4 mini aus und verbessert GPT-5.3 Instant, das laut Changelog nun weniger reißerische Formulierungen verwendet.
Das sogenannte Routing-System, bei dem ChatGPT entscheidet, welches Modell antwortet, ist schon lange ein Sorgenkind von OpenAI. Viele Nutzer empfanden das System bei Einführung als intransparent, da der Router nicht immer das leistungsfähigste Modell wählte und der Verdacht entstand, OpenAI wolle teure Anfragen auf günstigere Modelle umleiten.
Kommentieren
Quelle: OpenAI
Read full article about: OpenAI will das beste Sprachmodell, das in 16 MB passt
OpenAI fordert Forscher und Entwickler heraus, das beste Sprachmodell zu bauen, das in nur 16 MB passt – und nutzt den Wettbewerb gezielt zur Talentsuche. Beim offenen Forschungswettbewerb "Parameter Golf" müssen Gewichte und Trainingscode zusammen unter 16 MB bleiben, trainiert wird in maximal zehn Minuten auf acht H100-GPUs. Bewertet wird anhand der Kompression auf einem festen FineWeb-Datensatz.
OpenAI stellt dafür eine Million Dollar an Rechenzeit-Gutschriften über den Partner Runpod bereit. Herausragende Teilnehmer können zu Bewerbungsgesprächen eingeladen werden. Im Juni plant OpenAI, eine kleine Gruppe von Nachwuchsforschern einzustellen, darunter Studierende und Olympiade-Gewinner. Das GitHub-Repository enthält Baseline-Modelle, Evaluierungsskripte und eine öffentliche Rangliste. Die Teilnahme steht allen ab 18 Jahren in unterstützten Ländern offen und ist bis 30. April möglich.
Der Kampf um KI-Talente zwischen den großen Techkonzernen ist so hart wie nie. Meta hat in der Vergangenheit wiederholt Top-Forscher von OpenAI abgeworben, teilweise mit Vergütungspaketen von angeblich bis zu 300 Millionen Dollar.
Kommentieren
Quelle: OpenAI