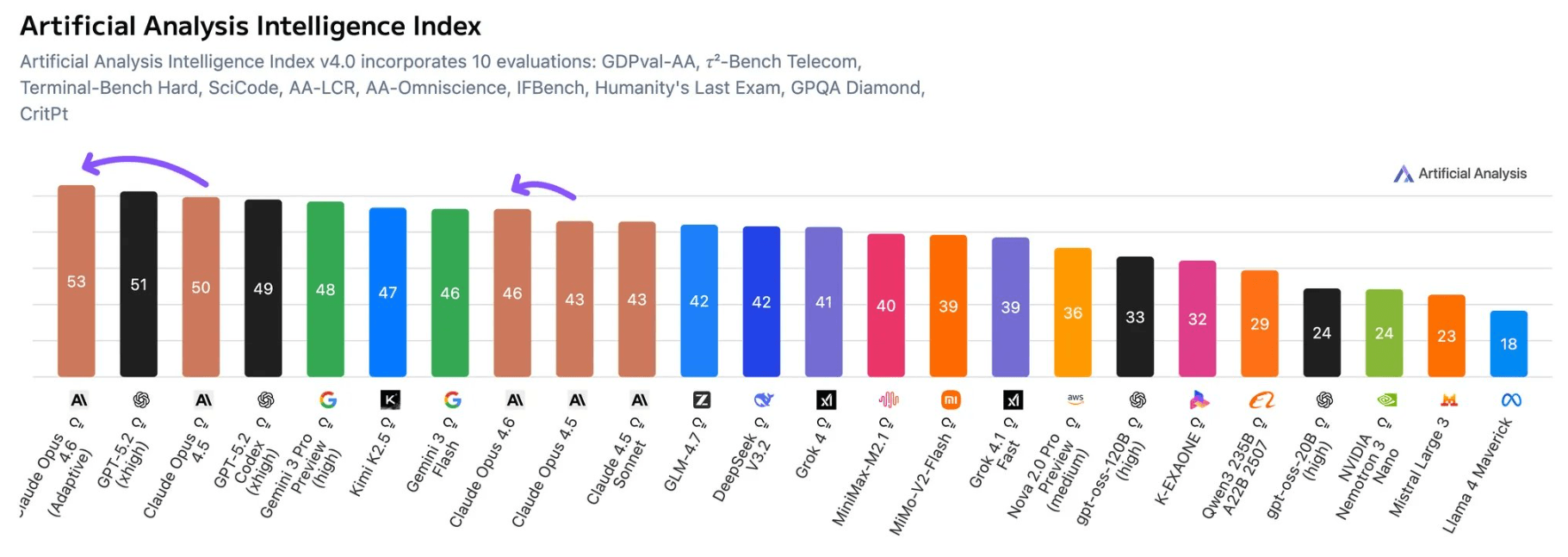
OpenAI-Chef Sam Altman hat Mitarbeitern in einer internen Slack-Nachricht mitgeteilt, dass ChatGPT wieder mehr als zehn Prozent monatlich wächst, berichtet CNBC. Die letzte offizielle Angabe sind 800 Millionen wöchentliche Nutzer aus dem Januar 2026.
Außerdem soll diese Woche ein aktualisiertes Chat-Modell für ChatGPT veröffentlicht werden; womöglich handelt es sich um die Chat-Variante des GPT-5.3-Modells, das letzte Woche als Coding-Version Codex erschien. Das Modell schneidet in agentischen Coding-Benchmarks besonders gut ab und ist laut OpenAI 25 Prozent schneller.
Das Coding-Produkt Codex sei innerhalb einer Woche um rund 50 Prozent gewachsen, so Altman, der das Wachstum als "Wahnsinn" bezeichnet. Es konkurriert direkt mit Anthropics Erfolgsprodukt Claude Code. Speziell die neue Desktop-App von Codex dürfte von OpenAI Schritt für Schritt auch für Anwendungsfälle über Code hinaus ausgebaut werden, ähnlich wie Anthropics Cowork.