BLIVA: KI kann Text in Bildern jetzt viel besser lesen

BLIVA ist ein multimodales Sprachmodell, das Text in Bildern lesen kann. Das könnte es in verschiedenen realen Anwendungen nützlich machen.
Forschende der UC San Diego haben BLIVA entwickelt, ein Bildsprachmodell, das Bilder mit Text besser verarbeiten kann, als bisherige Ansätze. Bildsprachmodelle (VLMs) erweitern große Sprachmodelle (LLMs), indem sie Computer-Vision-Fähigkeiten integrieren, um etwa Fragen zu Bildern zu beantworten.
Solche multimodalen Modelle haben in Benchmarks zur Beantwortung offener visueller Fragen beeindruckende Fortschritte erzielt. Ein Beispiel ist GPT-4 von OpenAI, das in seiner multimodalen Form etwa Bildinhalte beschreiben kann. Diese Fähigkeit ist allerdings derzeit nur in der App "Be my Eyes" verfügbar.
Eine bedeutende Einschränkung aktueller Systeme liegt jedoch in ihrer (Un-)Fähigkeit, zuverlässig Bilder mit Text zu verarbeiten, die in realen Szenarien häufig vorkommen.
BLIVA kombiniert InstructBLIP und LLaVA
Um dieses Problem zu lösen, entwickelte das Team BLIVA, was für "BLIP with Visual Assistant" steht. BLIVA kombiniert Methoden von Salesforce InstructBLIP und Microsofts LLaVA (Large Language and Vision Assistant), um Text besser zu erkennen und gleichzeitig keine Bilddetails zu übersehen.
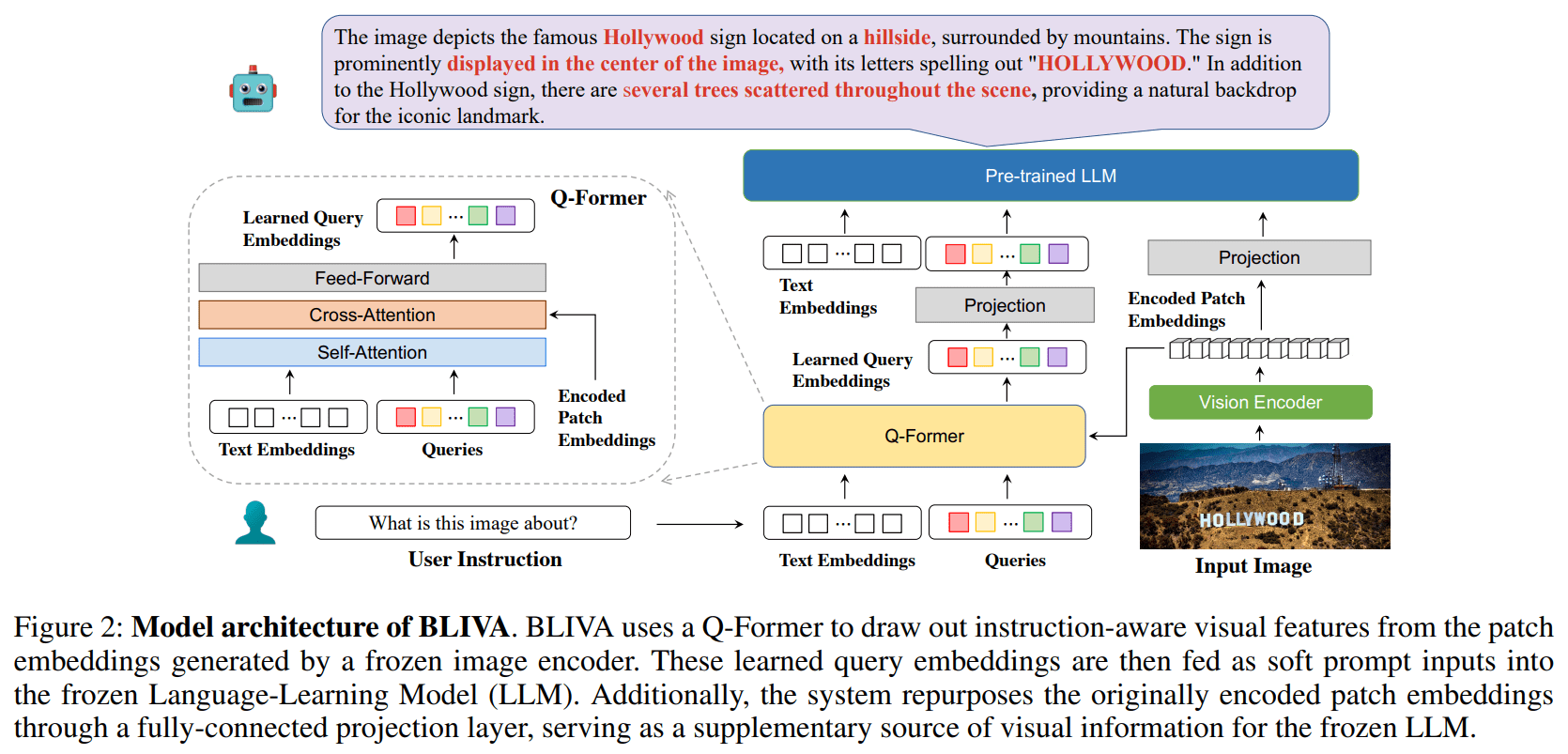
BLIVA wurde mit etwa 550.000 Bild-Text-Paaren trainiert und anschließend mit 150.000 visuellen Frage-Antwort-Beispielen feingetuned, wobei der visuelle Encoder und das Sprachmodell eingefroren blieben.
Das Team zeigt, dass BLIVA die Verarbeitung von textreichen Bildern in Datensätzen wie OCR-VQA, TextVQA und ST-VQA deutlich verbessert. Zum Beispiel erreichte BLIVA eine Genauigkeit von 65,38 % bei OCR-VQA im Vergleich zu 47,62 % bei InstructBLIP.
Das neue System übertraf InstructBLIP auch bei sieben von acht allgemeinen, nicht textbezogenen VQA-Benchmarks. Das Team ist überzeugt, dass dies die Vorteile ihres Ansatzes auch außerhalb des Textverständnisses zeigt.

Die Forschenden testeten BLIVA auch mit einem neuen Datensatz von YouTube-Thumbnails mit zugehörigen Fragen, der auf Hugging Face verfügbar ist. BLIVA erreichte eine Genauigkeit von 92 Prozent, was deutlich besser ist als frühere Methoden.
Die Fähigkeit von BLIVA, Text auf Bildern wie Straßenschildern oder Lebensmittelverpackungen zu lesen, könnte auch praktische Anwendungen in vielen Branchen ermöglichen, so das Team. Vor kurzem haben Microsoft-Forschende einen multimodalen KI-Assistenten für die Biomedizin vorgestellt, der auf LLaVA basiert und LLaVA-med heißt.
Weitere Informationen und der Code sind auf dem BLIVA Github verfügbar, eine Demo ist auf Hugging Face verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.