Biologisches KI-Basismodell "Evo" ermöglicht die Verarbeitung ganzer Genome

Ein Team von TogtherAI und dem Arc Institute stellt Evo vor, ein KI-Modell für die biologische Forschung, das DNA, RNA und Proteine interpretieren kann und generatives Design auf molekularer und genomischer Ebene ermöglicht.
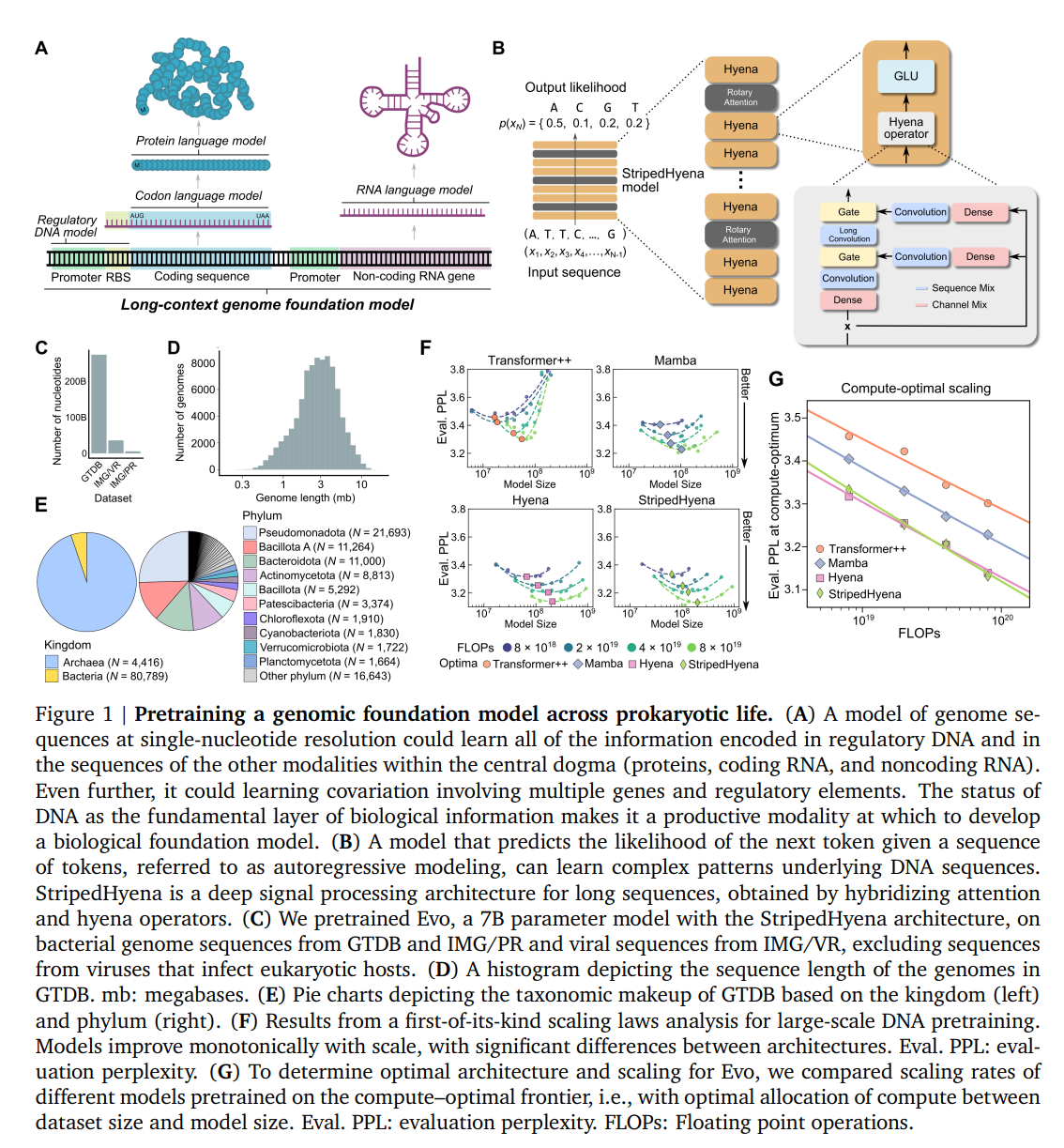
Das von einem Expertenteam bestehend aus Eric Nguyen, Michael Poli, Matthew Durrant, Patrick Hsu und Brian Hie entwickelte Modell stellt einen Meilenstein in der Verarbeitung und Analyse biologischer Daten dar. Evo nutzt eine modifizierte Version der StripedHyena-Architektur und zeichnet sich durch seine Fähigkeit aus, die grundlegenden biologischen "Sprachen" - DNA, RNA und Proteine - zu interpretieren, Vorhersagen zu treffen und generatives Design von der molekularen bis zur genomischen Ebene zu ermöglichen.
Die neue Architektur ermöglicht es Evo, lange Kontexte zu modellieren und mehr als 650.000 Token zu verarbeiten. Dies ist besonders wichtig für biologische KI-Modelle, da DNA-Sequenzen extrem lang sein können (bis zu Milliarden von Nukleotiden) und eine hohe Empfindlichkeit erforderlich ist, um die Auswirkungen der Evolution zu verstehen, die auf Veränderungen einzelner Nukleotide beruht. Evo ist in der Lage, auf Nukleotidebene zu arbeiten und die kleinsten Bausteine der DNA und RNA zu erkennen und zu interpretieren. Evo kann Sequenzen bis zu einer Länge von 131 Kilobasen (131.000 Basen) verarbeiten.
"Evo versucht, den Weg für Foundation-Modelling in der Biologie zu ebnen", sagt Micheal Poli, Mitautor von Evo und StripedHyena. Wie bei Sprachmodellen verwendet Evo ein Next-Token-Predition-Ziel, also die Vorhersage des nächsten Tokens während des Trainings - in diesem Fall auf Nukleotidebene. "Das Problem, warum das bisher nicht versucht wurde, ist, dass die Sequenzen extrem lang sind und die hohe Auflösung eine große Herausforderung für Transformatoren darstellt", sagt Poli. Er spielt damit auf Tokenizer an, die beispielsweise in Sprachmodellen Text in Token umwandeln und oft für Probleme in deren Fähigkeiten verantwortlich sind, da sie nicht auf Buchstaben- oder Zahlenebene arbeiten, sondern stattdessen Teile von Wörtern oder mehrere Zahlen in ein Token umwandeln.
Das konnte das Team auch in eigenen Experimenten reproduzieren, als es Transfomer-Modlele und andere Architekturen wie Mamba trainierte. "Das Erstaunliche ist, dass diese Deep-Signal-Processing-Architekturen wie StripedHyena besser zu skalieren scheinen", so Poli. "Es ist nicht nur so, dass sie diese längeren Sequenzen verarbeiten können und dann ungefähr so gut sind wie Transformer. Es ist so, als ob sie tatsächlich pro Flop besser skalieren. Ich denke, es sind einfach bessere Architekturen als Transformer."
Evo ist ein Foundation-Modell für Biologie
Für das Training von Evo wurde eine umfangreiche Datenbank mit 2,7 Millionen Genomen von Prokaryonten verwendet - ein Bruchteil der öffentlich verfügbaren Genomdaten. Das Modell wurde in zwei Schritten trainiert. In der ersten Phase wurde es mit einer Kontextlänge von 8.000 Basenpaaren trainiert, in der zweiten Phase wurde die Kontextlänge auf 131.000 Basenpaare erhöht. Dadurch kann das Modell Muster erkennen und Vorhersagen über eine wesentlich längere DNA-Sequenz treffen als mit bisherigen Methoden. Der entsprechende Trainingsdatensatz, OpenGenome, soll in Kürze öffentlich zugänglich gemacht werden.
Erste Experimente mit Evo zeigen das Potenzial für verschiedene Anwendungen, einschließlich der Vorhersage lebenswichtiger Gene eines Organismus auf der Grundlage geringfügiger DNA-Mutationen. Diese Fähigkeit könnte herkömmliche Laborexperimente ersetzen, die nach Angaben des Teams oft Monate dauern können.
In Tests konnte es mit führenden protein-spezifischen Sprachmodellen mithalten, um die Auswirkungen von Mutationen auf die Funktion von E. coli-Proteinen vorherzusagen. Evo kann auch die funktionellen Eigenschaften von nicht-kodierenden RNAs (ncRNAs) vorhersagen und die Genexpression von regulatorischer DNA ableiten.
Darüber hinaus ist Evo in der Lage, komplexe molekulare Systeme wie CRISPR-Cas-Komplexe und transponierbare Elemente zu generieren. Evo kann auch DNA-Sequenzen mit einer Länge von mehr als 650 Kilobasen erzeugen - eine Größenordnung mehr als bisherige Methoden. Während sich bisherige generative Modelle zudem meist auf eine einzelne Modalität konzentrieren, ist Evo in der Lage, große funktionelle Komplexe aus Proteinen und ncRNAs zu entwerfen.
Evo ist in der Lage, generative Designs vom molekularen bis zum genomischen Maßstab zu entwickeln. | Video: Together AI
Evo wirft ethische Fragen auf, die beantwortet werden müssen
Das Evo-Team betrachtet ihr Modell als einen potenziellen Meilenstein in der Modellierung biologischer Sequenzen und sieht Anwendungsmöglichkeiten in verschiedenen Feldern wie Chemie, Materialwissenschaft, Arzneimittelforschung, Landwirtschaft und Nachhaltigkeit. Die praktische Anwendung der generierten Sequenzen erfordert jedoch weitere Validierung, so das Team.
Evo ist das erste System seiner Art, das DNA-Sequenzen auf der Ebene des gesamten Genoms mit einer Auflösung von einem einzelnen Nukleotid vorhersagen und erzeugen kann. "Die zukünftigen Möglichkeiten, die sich aus groß angelegten DNA-Modellen wie Evo ergeben, erfordern auch zusätzliche Arbeiten, um sicherzustellen, dass diese Möglichkeiten sicher und zum Nutzen der Menschheit eingesetzt werden", heißt es im Blog-Beitrag.
Es bestehen Bedenken hinsichtlich eines möglichen Missbrauchs, sozialer und gesundheitlicher Ungerechtigkeit und Umweltzerstörung. Das Team schlägt daher vor, umfassende Richtlinien für ethische Praktiken zu entwickeln, Transparenz zu fördern und internationale Kooperationen und Partnerschaften zu unterstützen, die zu einer verantwortungsvollen Nutzung und Entwicklung von Instrumenten wie Evo beitragen könnten.
Investitionen in Bildung und Kapazitätsaufbau sowie die Zusammenarbeit mit Organisationen wie der Global Alliance for Genomics and Health (GA4GH) könnten ebenfalls zu einer Zukunft beitragen, in der Fortschritte in der Gentechnik mit ethischen Grundsätzen und gesellschaftlichen Werten im Einklang stehen.
Das Team stellt Code und Modell über GitHub zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.