Common Pile: Größter Datensatz für KI-Training mit lizenzierten Inhalten veröffentlicht

Mit dem Common Pile steht erstmals ein umfangreicher Textdatensatz aus offen lizenzierten Quellen zur Verfügung, der das Training großer Sprachmodelle ermöglichen soll – als Alternative zu urheberrechtlich fragwürdigen Webdaten.
Der 8 TB große und von einem Forschungsteam unter anderem von der University of Toronto, Hugging Face, EleutherAI und dem Allen Institute for AI (Ai2) zusammengesammelte Common Pile v.01 enthält Inhalte aus 30 verschiedenen Quellen.
Dazu gehören wissenschaftliche Artikel und Abstracts des Pre-Print-Servers Arxiv, medizinische Texte aus PubMed Central sowie mehrere Millionen wissenschaftliche Publikationen. Ebenfalls enthalten sind juristische Texte wie US-Patente, Gesetzestexte vom US Government Publishing Office, Gerichtsurteile aus dem Caselaw Access Project sowie Debattenprotokolle des britischen Parlaments. Weitere Bestandteile sind Bücher aus dem Project Gutenberg oder der Library of Congress sowie freie Lern- und Lehrmaterialien.
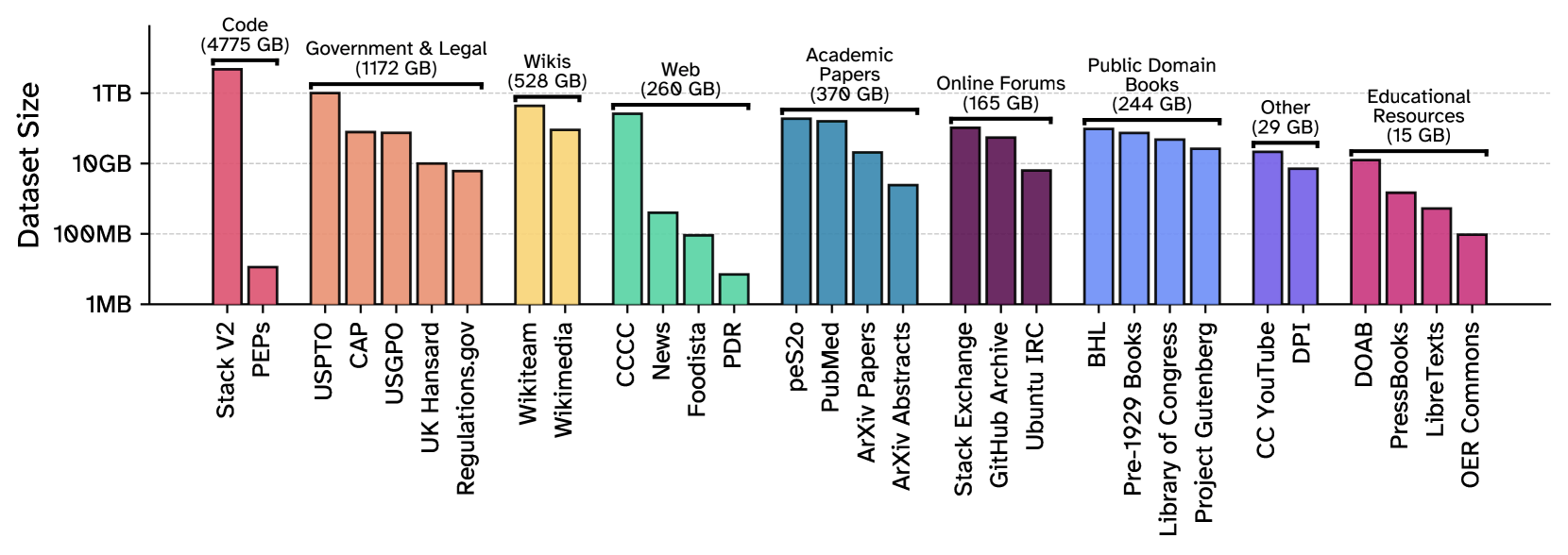
Zudem enthält der Common Pile Inhalte aus Online-Foren wie StackExchange, Chatprotokolle aus dem Ubuntu-IRC, Diskussionsverläufe von GitHub sowie transkribierte YouTube-Videos von über 2.000 Kanälen. Ein kleiner Teil des Datensatzes besteht aus kuratierten Aufgabenformaten wie Frage-Antwort-Paaren oder Klassifikationsaufgaben.
Sorgfältige Lizenzprüfung, aber keine hundertprozentige Garantie
Die Auswahlkriterien für die Inhalte orientieren sich an der Open Definition 2.1 der Open Knowledge Foundation. Eingeschlossen wurden nur Texte mit offenen Lizenzen wie CC BY, CC BY-SA, CC0 oder Softwarelizenzen wie MIT oder BSD. Inhalte mit Einschränkungen wie "nicht kommerziell" (CC NC) oder "keine Bearbeitungen" (CC ND) wurden ausgeschlossen.
Das Team verzichtete auch auf Quellen mit unklarer Lizenzlage wie YouTube Commons oder OpenAlex. Auch synthetisch erzeugte Texte – etwa von KI-Modellen, die ihrerseits mit unlizenzierten Daten trainiert wurden – sind nicht enthalten. Damit will das Forschungsteam verhindern, dass über Umwege doch wieder rechtlich bedenkliche Inhalte in den Trainingsdaten landen.
Trotz umfangreicher Prüfungen räumen die Forschenden ein, dass sich einzelne problematische Inhalte nicht mit absoluter Sicherheit ausschließen lassen. Fehlerhafte Lizenzkennzeichnungen ("License Laundering") oder spätere Änderungen an Lizenzen könnten zu Abweichungen führen.
Filter gegen Duplikate, Werbung und Müll
Vor dem Training wurden die Daten umfassend bereinigt. Mithilfe automatischer Spracherkennung haben die Forschenden nur englischsprachige Texte behalten. Für Webinhalte kam ein Textqualitätsklassifikator zum Einsatz, der Inhalte mit geringer sprachlicher Qualität entfernte.
Zudem haben sie Dokumente aussortiert, deren statistische Eigenschaften unter einem Referenzmodell auffällig niedrig bewertet wurden. Das Verfahren soll insbesondere Fehler durch optische Zeichenerkennung (OCR) erkennen.
Private Informationen wie E-Mail-Adressen, Telefonnummern oder IP-Adressen haben die Forschenden durch Platzhalter ersetzt. Toxische Inhalte wurden ebenfalls mithilfe eines Klassifikators entfernt.
Um doppelte oder sehr ähnliche Dokumente zu erkennen, kam ein sogenannter Bloom-Filter zum Einsatz. Zwei Texte gelten dabei als Duplikat, wenn mehr als 90 Prozent ihrer Wortkombinationen übereinstimmen.
Quellcode wurde gesondert behandelt. Aus dem Stack-V2-Datensatz wurden nur Dateien in 15 Programmiersprachen wie Python, C++, Java und Rust übernommen. Zusätzlich mussten die Codebeispiele gut dokumentiert und für Lernzwecke geeignet sein.
Comma: Kleine Sprachmodelle mit offener Datengrundlage
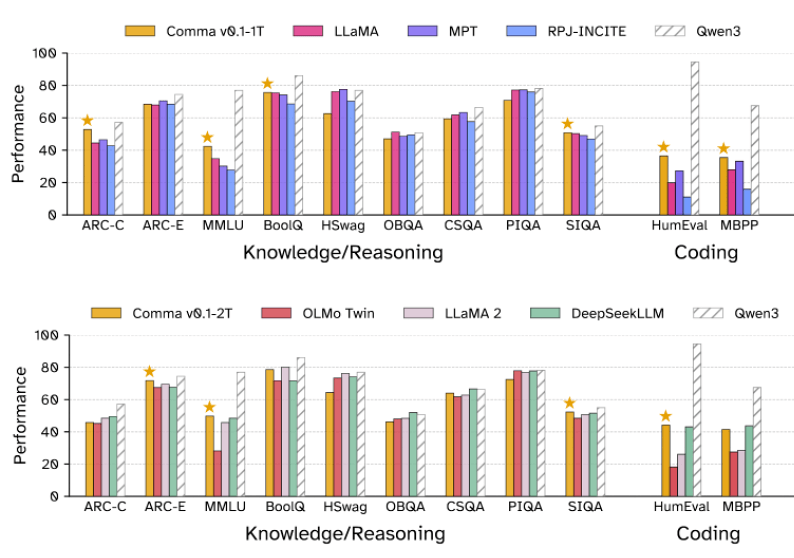
Um die Eignung des Datensatzes zu erproben, trainierte das Team zwei Sprachmodelle mit je sieben Milliarden Parametern. Comma v0.1-1T wurde mit einer Billion Token trainiert, Comma v0.1-2T mit der doppelten Menge. Beide Modelle basieren auf der Architektur von Metas Llama-Modellen und verwenden einen eigens auf dem Common Pile trainierten Tokenizer.
Getestet wurden die Modelle auf Benchmarks wie dem allgemein angelegten MMLU, den Schlussfolgerungs-Tests ARC oder CommonsenseQA sowie auf Programmieraufgaben wie HumanEval und MBPP.
Comma v0.1-1T schnitt in vielen dieser Tests besser ab als Modelle mit ähnlicher Parameterzahl und ähnlichem Trainingsbudget wie Llama-1-7B, StableLM-7B oder OpenLLaMA-7B, die auf unlizenzierten Daten trainiert wurden. Besonders großen Vorsprung hatte das Modell bei wissenschaftlichen Aufgaben und Programmiertests.
Weniger überzeugend war die Leistung bei Aufgaben wie HellaSwag oder PIQA, die auf Alltagssprache und informelle Kontexte setzen. Solche Textsorten, etwa persönliche Erfahrungsberichte, Blogs oder Inhalte in anderen Sprachen, sind im Common Pile bislang unterrepräsentiert oder gar nicht vorhanden.
Die Variante mit zwei Billionen Trainingstoken haben die Forschenden gegen Llama-2-7B, OLMo-7B-Twin und DeepSeekLLM antreten lassen. Alle Vergleichsmodelle sind schon etwas älter und erschienen spätestens 2024 – bis auf Qwen3-8B, das als aktuelle State-of-the-Art-Referenz dient. "Wir betonen, dass wir keinen zuverlässigen Vergleich mit einem Modell mit einem 36-fach oder 18-fach größeren Trainingsbudget anstellen können", heißt es im Paper.
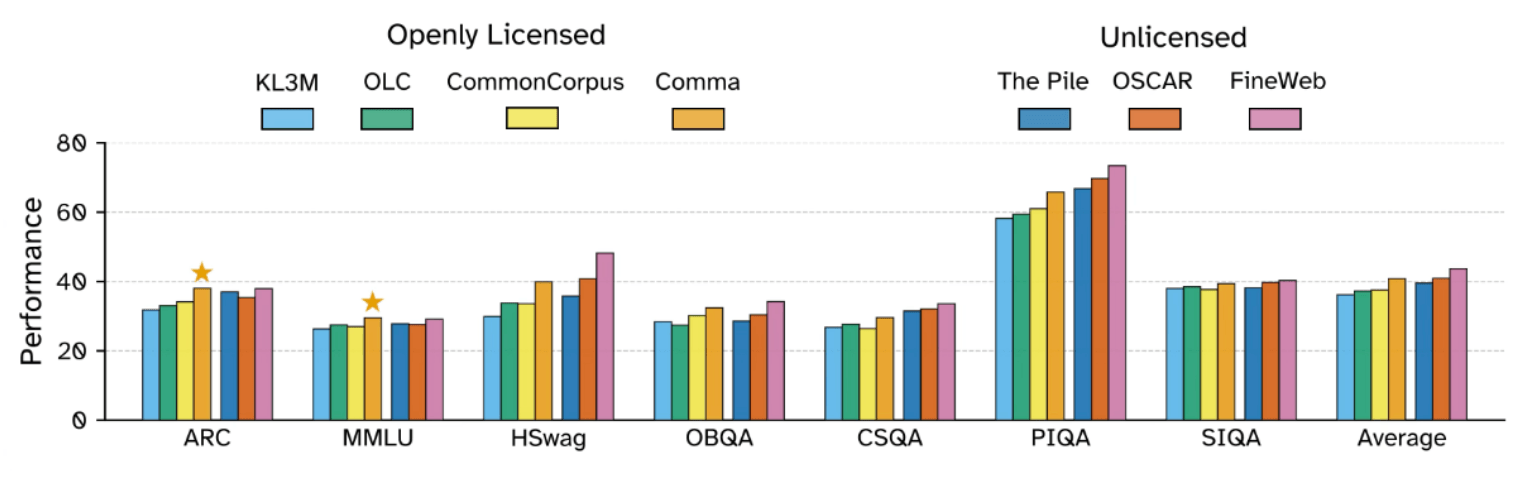
Gegenüber bisherigen offen lizenzierten Datensätzen wie KL3M, OLC oder Common Corpus zeigte der Common Pile durchgehend bessere Ergebnisse. Auch gegenüber dem 800 GB großen Meta-Datensatz The Pile schnitt Comma in den meisten Benchmarks besser ab. Der von EleutherAI 2020 zusammengestellte The Pile ist ein weit verbreiteter Datensatz im KI-Training, gilt aber als problematisch, weil er größtenteils urheberrechtlich geschützte Inhalte enthält, die ohne ausdrückliche Zustimmung der Urheber verwendet wurden, was rechtliche und ethische Bedenken aufwirft.
Das FineWeb-Dataset, das stark gefilterte Webinhalte enthält, erreichte bei den meisten Tests die besten Werte. Allerdings basiert FineWeb ebenfalls nicht ausschließlich auf offen lizenzierten Quellen.
Ein erster Schritt in Richtung rechtssicherer Sprachmodelle
Mit dem Common Pile v0.1 zeigen die Forschenden, dass leistungsfähige Sprachmodelle auch auf der Basis offen lizenzierter Daten trainiert werden können. Der Datensatz markiert damit einen wichtigen Schritt in Richtung eines transparenten und rechtlich nachvollziehbaren KI-Ökosystems.
Allerdings betonen die Autoren, dass der Common Pile nur der Anfang sein kann. Um langfristig mit großen, kommerziellen Modellen konkurrieren zu können, sei eine gezielte Erweiterung der offenen Datenbasis erforderlich. Derzeit läuft unter anderem ein Rechtsstreit zwischen der New York Times und OpenAI wegen der Nutzung von urheberrechtlich geschütztem Material zum KI-Training.
Die Forschenden stellen neben dem Datensatz auch den Code zur Datenerstellung, die Comma-Trainingsdaten sowie den Tokenizer öffentlich zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.