CriticGPT: OpenAI sieht KI-Kritik als Schlüssel zur sicheren Ausrichtung intelligenterer KI-Systeme

OpenAI hat "Kritiker" KI-Modelle entwickelt, die Menschen helfen, Fehler im Code großer Sprachmodelle zu finden. Diese Modelle sollen die grundlegenden Grenzen des Reinforcement Learning mit menschlichem Feedback (RLHF) überwinden.
OpenAI hat ein neues KI-Modell namens CriticGPT vorgestellt, das auf GPT-4 basiert und darauf trainiert wurde, Fehler in ChatGPT-Ausgaben zu erkennen. Ziel ist es, menschliche Trainer bei der Bewertung von KI-Antworten im Rahmen des Reinforcement Learning from Human Feedback (RLHF) zu unterstützen.
Laut OpenAI können Menschen mithilfe von CriticGPT in 60 Prozent der Fälle bessere Bewertungen von ChatGPT-Code abgeben als ohne KI-Unterstützung. Das Unternehmen plant, CriticGPT-ähnliche Modelle in seinen RLHF-Bewertungsprozess zu integrieren.
"Mit zunehmender Genauigkeit von ChatGPT werden die Fehler subtiler und für menschliche Bewerter schwieriger zu erkennen", erklärt OpenAI. Dies stellt eine grundlegende Einschränkung der RLHF dar und kann die Ausrichtung von Modellen erschweren, die nach und nach mehr Wissen erwerben als einzelne Menschen.
Nicht mehr ganz so menschliches Feedback beschleunigt KI-Training
CriticGPT wurde ähnlich wie ChatGPT mit RLHF trainiert. Das Modell wurde jedoch mit einer großen Anzahl von Eingaben trainiert, die absichtlich eingefügte Fehler enthielten. KI-Trainer fügten manuell Fehler in den von ChatGPT geschriebenen Code ein und gaben dann Feedbackbeispiele, als ob sie den Fehler entdeckt hätten.
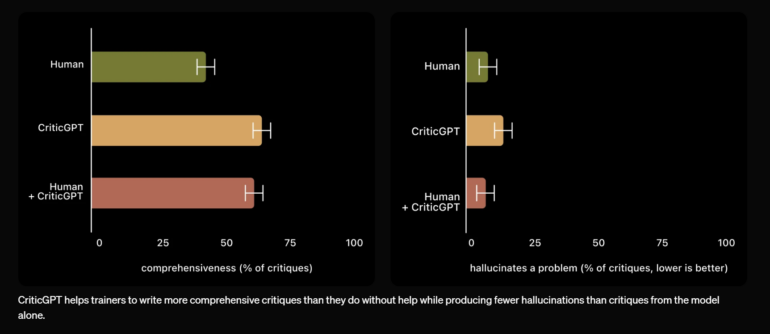
In den Tests bevorzugten die Trainer in 63 % der Fälle bei natürlich auftretenden Fehlern die Kritik von CriticGPT gegenüber der Kritik von ChatGPT. CriticGPT produzierte weniger "Nörgeleien" und halluzinierte seltener Probleme.
OpenAI betont, dass die Vorschläge von CriticGPT nicht immer korrekt sind. Die Kombination von Mensch und CriticGPT führte jedoch zu einer umfassenderen Kritik als der Mensch allein und zu weniger halluzinierten Fehlern als das Modell allein - die Kombination von Mensch und Maschine schlug den Menschen in 60 Prozent der Fälle.
Die Forscher räumen aber auch ein, dass ihre Methode Grenzen hat. So wurden nur relativ kurze Codebeispiele untersucht. Für die Bewertung komplexerer Aufgaben seien andere Methoden nötig. Zudem könnten Halluzinationen der Modelle zu Fehleinschätzungen der Trainer führen und die Technik auch von Angreifern genutzt werden, um Schwachstellen in Software zu finden.
Das Unternehmen sieht in CriticGPT dennoch einen vielversprechenden Ansatz, um Menschen bei der Erstellung besserer RLHF-Daten für Sprachmodelle zu unterstützen. Den Forschern zufolge ist die Arbeit aber auch ein Schritt in Richtung "scalable Oversight" - Methoden, mit denen Menschen den Output immer leistungsfähigerer KI-Systeme besser einschätzen können. "Von diesem Punkt an wird die Intelligenz von LLMs und LLM-Kritikern nur noch weiter wachsen. Die menschliche Intelligenz wird dies nicht tun", schreiben sie. "Es ist daher von entscheidender Bedeutung, skalierbare Methoden zu finden, die sicherstellen, dass wir das richtige Verhalten unserer KI-Systeme belohnen, selbst wenn sie viel klüger werden als wir. Wir glauben, dass die LLM-Kritiker ein vielversprechender Anfang sind."
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.