DeepFloyd IF: Das bisher beste Text-zu-Bild-Modell ist Open Source

DeepFloyd IF ist ein Text-zu-Bild-Modell, das besonders gut mit Text umgehen kann. Das Team ist an Stability AI angegliedert und nennt als Vorbild Googles Imagen.
Im Mai 2022 zeigte Google Imagen, ein Text-zu-Bild-Modell, das das damals gerade veröffentlichte DALL-E 2 von OpenAI übertraf. Laut dem Team und den gezeigten Beispielen schlug das Modell DALL-E in der Genauigkeit und Qualität der Text-zu-Bild-Synthese. Es war auch in der Lage, Text in Bildern zu generieren, eine Fähigkeit, die bisher von keinem Open-Source-Modell zuverlässig beherrscht wird.
Wie bei anderen generativen KI-Modellen wie Stable Diffusion oder DALL-E 2 setzte das Google-Team auf einen eingefrorenen Text-Encoder, der Textprompts in Embeddings umwandelt, die dann von einem Diffusionsmodell in ein Bild transformiert werden. Im Gegensatz zu anderen Modellen verwendet Imagen jedoch nicht das multimodal trainierte CLIP, sondern das große Sprachmodell T5-XXL. Das Team konnte sogar zeigen, dass die Qualität der erzeugten Bilder mit zunehmender Größe des Sprachmodells stärker zunimmt als mit zunehmendem Training des eigentlich für die Bildsynthese zuständigen Diffusionsmodells.
DeepFloyd IF ist ein Open-Source-Imagen
Jetzt hat das DeepFloyd-Team, das mit StabilityAI verbunden ist, diese Architektur nachgebildet und eine Art Open-Source-Imagen namens IF veröffentlicht. IF zeigt nach Angaben des Teams die hohe Bildqualität von Imagen und das von T5-XXL gelieferte Sprachverständnis. Das Modell wurde mit rund 1,2 Milliarden Bildern aus dem LAION-5B-Datensatz trainiert.
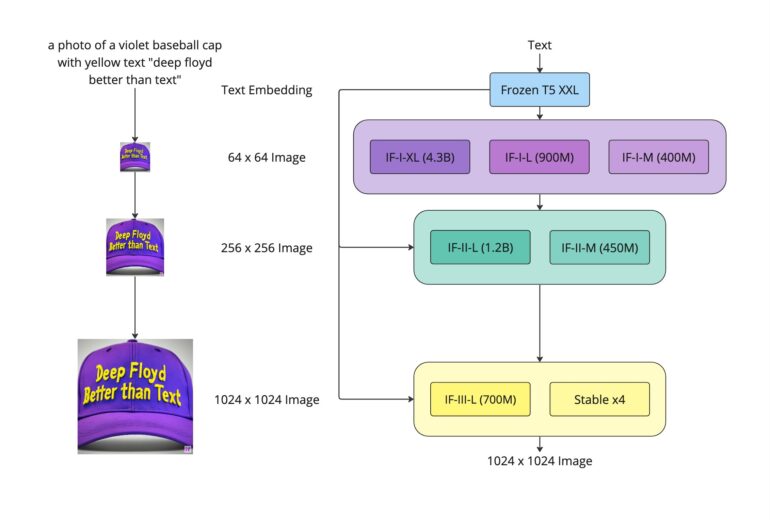
In Tests übertrifft es sogar Google Imagen und erreicht einen Zero-Shot-FID-Wert von 6,66 im COCO-Datensatz und liegt damit auch vor anderen verfügbaren Modellen wie Stable Diffusion.




Nach Angaben des Teams unterstützt IF auch Image-to-Image-Translation und Impainting.
Video: DeepFloyd
DeepFloyd IF setzt ebenfalls wie Imagen auf zwei Superresolution-Modelle, die die Auflösung der Bilder auf 1.024 x 1.024 Pixel bringen, und bietet verschiedene Modellgrößen mit bis zu 4,3 Milliarden Parametern an. Für das größte Modell mit Upscaler auf 1.024 Pixel empfiehlt das Team 24 Gigabyte VRAM, das größte Modell mit 256 Pixel Upscaler benötigt noch 16 Gigabyte VRAM.
DeepFloyd zeigt die nächste Stufe der Text-zu-Bild-Synthese
Laut DeepFloyd zeigt die Arbeit das Potenzial größerer UNet-Architekturen in der ersten Stufe von kaskadierten Diffusionsmodellen und damit eine vielversprechende Zukunft für die Text-zu-Bild-Synthese. Mit anderen Worten: DeepFloyds IF zeigt deutlich, dass generative KI noch besser werden kann und dass die Open-Source-Gemeinschaft in Zukunft Modelle wie Googles Parti erreichen könnte, das Imagen in einigen Aspekten noch übertrifft.
Die erste Version des IF-Modells unterliegt einer eingeschränkten Lizenz, die nur für Forschungszwecke - also nicht-kommerzielle Zwecke - gedacht ist, um vorübergehend Feedback zu sammeln. Nachdem dieses Feedback eingeholt wurde, wir das Team von DeepFloyd und StabilityAI eine völlig kostenlose und auch für kommerzielle Zwecke kompatible Version veröffentlichen.
DeepFloyds IF hat ein Github, eine Demo ist auf HuggingFace verfügbar. Mehr Informationen und Zugang gibt es auf DeepFloyd-Webseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.