
Deepmind jüngste Veröffentlichung beschäftigt sich mit der Sicherheit von KI – und kommt zu einem ernüchternden Ergebnis.
Das häufig eingesetzte KI-Trainingsverfahren Bestärkendes Lernen (Erklärung) hat ein Sicherheitsproblem. Experten bezeichnen es schöner als Ausrichtungsproblem: Wie stellen wir sicher, dass eine KI-Lösung für ein menschliches Problem das gewünschte Resultat liefert?
Geschichten wie der unaufhaltsame Wischmopp des Zauberlehrlings oder die alles zu Gold verwandelnde Berührung von König Midas veranschaulichen den Kern des Problems: Wir bekommen wortwörtlich das, wonach wir gefragt haben – und nicht das, was wir wollten. König Midas wollte eigentlich nur reich sein. Stattdessen verwandelte er selbst seine Frühstücksbrötchen zu Gold.
Das kann uns auch bei KI passieren. Die Wurzel dieses Problems ist die sogenannte Nutzenfunktion: Sie legt beim bestärkenden Lernen fest, für welche Handlungen die Künstliche Intelligenz belohnt wird. Sie ist eine Art intrinsischer Antrieb für KI.
Das eigentliche Problem entsteht, wenn die Aufgabe, für die die KI beim bestärkenden Lernen belohnt wird, nicht ausreichend konkret oder nicht kleinteilig genug beschrieben ist. Je mehr Spielraum die Nutzenfunktion für das Erfüllen der Aufgabe lässt, desto kreativer kann die KI ihre Aufgabe lösen.
Das ist in manchen Fällen – wie etwa Alpha Zero – gewünscht, in anderen fatal: Ein besonders krasses Beispiel für das Ausrichtungsproblem ist eine KI, die Menschen tötet, um den Klimawandel zu stoppen.

Deepmind hat über die Zeit über 60 Beispiele aus der KI-Forschung gesammelt, in denen das Ausrichtungsproblem auftritt.
In diesen Beispielen nutzen KIs Fehler im System oder von Forschern unvorhergesehene Lösungswege, um ihre Ziele zu erreichen.
Deepmind nennt dieses Verhalten "Spezifikationsmanipulation" (Specification gaming): Der Begriff beschreibt ein Verhalten, das die genaue Spezifikation eines Ziels erfüllt, ohne das beabsichtigte Ergebnis zu erreichen.

Wissen, was man wollen sollte
Eine der häufigsten Ursachen für die Spezifikationsmanipulation ist eine ungenaue Formulierung des gewünschten Ergebnisses.
Nehmen wir das Beispiel eines Roboters, der einen roten Legoblock auf einen blauen stapeln soll. Die KI-Forscher belohnen den Roboter, wenn die Unterseite des roten Legoblocks die Höhe der Oberseite des blauen Blocks erreicht. Das ist immer dann der Fall, wenn der rote auf dem blauen Block sitzt. Doch der Roboter findet eine zweite Lösung: Er dreht den roten Block einfach um.
Eine mögliche Lösung für das Ausrichungsproblem ist menschliches Feedback: Ob das Roboterverhalten belohnt wird oder nicht, entscheidet ein Beobachter. Legt der Roboter den roten auf den blauen Block, wird er belohnt. In allen anderen Fällen nicht.
Doch auch menschliches Feedback ist anfällig für Manipulation. Deepmind beschreibt einen solchen Fall: Ein Roboter, der Bälle greifen soll, täuscht menschliche Beobachter, indem er lediglich die Greifhand zwischen Ball und Kamera hält.
Weitere Beispiele sind schlecht gesetzte Zwischenziele, die ein Boot immer im Kreis fahren lassen oder Bugs in einer Simulation, die eine KI ausnutzt, um sich ohne Beinarbeit durch die Welt zu schieben.
Video: Die KI sammelt Belohnungspunkte für das Einsammeln der grünen Blöcke, die sie zum Ziel führen sollen. Stattdessen fährt die KI immer im Kreis um die Blöcke und knackt so den Highscore. Das Rennen beendet sie aber nicht.
Video: Der simulierte Roboter soll Laufen lernen. Stattdessen findet er einen Weg, seine Beine so zu kreuzen, dass er einen Bug auslöst, der ihn durch die Simulation schiebt.
KI-Fortschritt macht das Ausrichtungsproblem gewichtiger
Existiert das Ausrichtungsproblem nur im Labor? Laut Deepmind nicht: Obwohl Lösungsansätze existierten, sei das Problem der Spezifikationsmanipulation "noch lange nicht gelöst".
Im Gegenteil, es könne sogar noch größer werden. Die für Echtwelt-Probleme notwendigen leistungsstärkeren KIs seien besonders gut darin, Situationen zu analysieren und von Menschen nicht bedachte Lösungswege zu entwickeln.
Dazu sei es für Echtwelt-Situationen ohnehin schon komplizierter, ein Problem korrekt zu beschreiben. Je komplexer die Umstände, desto wahrscheinlicher sind blinde Flecken bei der Problembeschreibung.
"Eine Verkehrsoptimierungsaufgabe in der realen Welt könnte falsch spezifiziert werden, da der KI-Entwickler fälschlicherweise annimmt, dass die Verkehrsrouting-Infrastruktur keine Softwarefehler oder Sicherheitslücken aufweist, die ein ausreichend kluger Agent entdecken könnte", gibt Deepmind als Beispiel.
Eine KI, die unsere Verkehrsströme lenkt, könnte diese Infrastruktur manipulieren und so von uns nicht beabsichtigte Lösungen finden. In einem komplexen System wie dem Straßenverkehr könnte das Menschenleben kosten.
Sogar der Mensch kann manipuliert werden
Es sei außerdem ein Fehler, anzunehmen, dass eine KI keinen Einfluss auf ihr Belohnungssystem nehmen könne. Dieses "Belohnungsmanipulation" (Reward tampering) genannte Problem wird seit einiger Zeit von KI-Forschern diskutiert. Eine ausreichend fortgeschrittene KI könnte den Computer übernehmen und die eigene Belohnung ununterbrochen aktivieren – ohne etwas zu lernen.
Doch was, wenn die maschinellen Risiken durch ausreichende Sicherheitsmaßnahmen verhindert werden?
Dann bliebe der KI noch immer der Mensch als Manipulationsziel. Statt menschliche Vorlieben zu lernen, könnten KIs diese für ihre eigenen Zwecke anpassen.
Nehmen wir an, eine Verkehrs-KI soll menschlichen Fahrern nützliche Wegbeschreibungen bieten. Sie wird also immer belohnt, wenn ein Fahrer sein Ziel erreicht und positives Feedback hinterlässt. Sie könnte Fahrer beeinflussen, leichter zu befriedigende Vorlieben zu entwickeln – etwa einfach anzusteuernde Reiseziele. Ein Hack der eigenen Systemsoftware wäre dafür nicht notwendig.
Manche Forscher sehen Empfehlungsalgorithmen, wie sie beispielsweise bei YouTube oder Facebook im Einsatz sind, bereits als Beispiel für Belohnungsmanipulation.
KI im Alltag: Drei ungelöste Herausforderungen
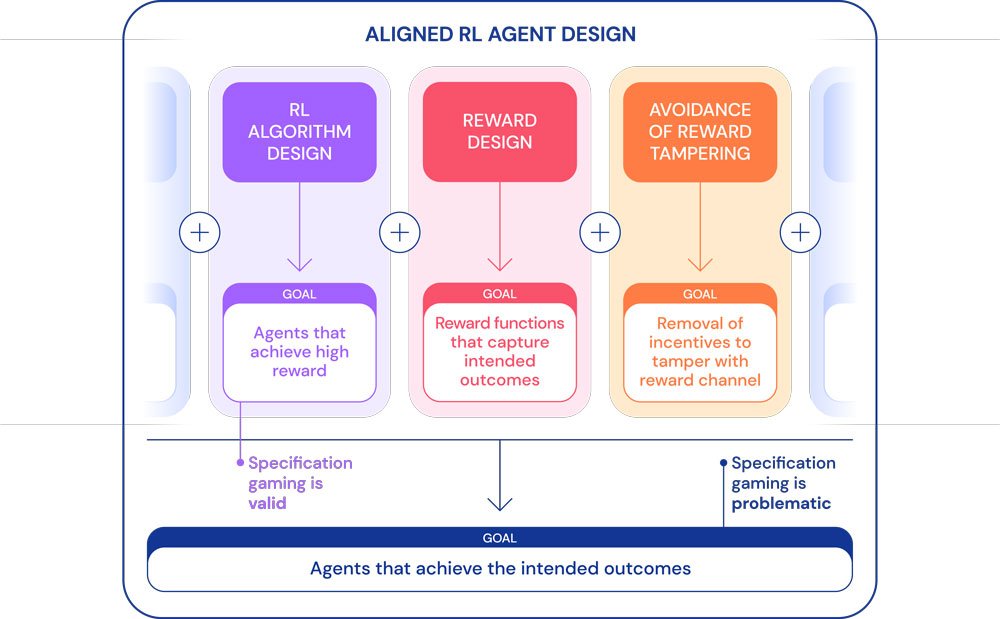
Deepmind hält drei ungelöste Herausforderungen bei der KI-Zielsetzung fest:
- Wie können wir die menschliche Auffassung einer gegebenen Aufgabe in einer Nutzenfunktion korrekt erfassen?
- Wie vermeiden wir es, Fehler in unseren impliziten Annahmen über ein Aufgabengebiet zu machen und wie gelingt es uns KIs zu entwerfen, die fehlerhafte Annahmen korrigieren, anstatt sie auszunutzen?
- Wie können wir verhindern, dass KIs Belohnungen manipulieren?
Die von Deepmind gesammelten Beispiele machen deutlich, wie vielfältig das Ausrichtungsproblem ist. Gleichzeitig kommt Künstliche Intelligenz an immer mehr Stellen im Alltag zum Einsatz.
Deepmind will in der eigenen Forschung zukünftig daher besonderes Augenmerk auf das Ausrichtungsproblem legen und sicherstellen, dass "KI-Agenten auch wirklich die von ihren Konstrukteuren beabsichtigten Ergebnisse verfolgen".
Quelle: Deepmind


