
Deepmind zeigt ein Sprachmodell, das aus verschiedenen menschlichen Meinungen lernt und Kompromisse vorschlägt.
Eine zentrale Herausforderung beim Einsatz großer Sprachmodelle ist, sicherzustellen, dass die generierten Texte nützlich und an menschlichen Werten orientiert sind. Unternehmen wie OpenAI setzten daher auf bestärkendes Lernen mit menschlichem Feedback (RLHF).
Dabei wird ein Sprachmodell wie GPT-3 üblicherweise in zwei Schritten verbessert: Zuerst werden die Ausgaben des Modells wie Zusammenfassungen oder Antworten auf Fragen von Menschen bewertet.
Das Modell wird dann mit den am besten bewerteten Texten trainiert. Zusätzlich wird ein Belohnungsmodell mit den Bewertungen trainiert, das wiederum Feintuning des Sprachmodells auf menschliche Bedürfnisse unterstützt. Das Modell lernt so menschliche Präferenzen und kann dann die vom Sprachmodell generierten Ausgaben steuern oder filtern.
Beispiele sind etwa OpenAIs InstructGPT, "text-davinci-003" oder das jüngst veröffentlichte ChatGPT. Nun zeigt Deepmind einen anderen Ansatz, der die (mögliche zukünftige) Rolle von Sprachmodellen in demokratischen Systemen berücksichtigt.
Deepmind kritisiert Werte-Homogenität im RLHF
Bisherige Methoden des RLHF seien zwar leistungsstark, behandelten die menschlichen Präferenzen jedoch, als seien sie homogen und statisch, so das Team von Deepmind. Bei Zusammenfassungen oder dem Befolgen von Anweisungen sei das vernünftig - schließlich gäbe es hier objektive Kriterien, ob die Aufgabe erfüllt worden sei oder nicht.
In vielen sozialen Problemen, in denen Menschen Sprachen nutzen - etwa der sozialen Koordination oder Entscheidungsfindung in der Gruppe - könne man jedoch nicht davon ausgehen, dass alle Menschen dieselben Werte teilen.
Das Team widmet sich in seiner Arbeit daher der Konsensbildung durch Sprache. In einem Konsens stimmt ein großer Teil einer sozialen Gruppe trotz unterschiedlicher Ansichten einem bestimmten Thema oder einer bestimmten Vorgehensweise zu. Konsens sei daher eine Voraussetzung für menschliche Zusammenarbeit und eine tragende Säule des demokratischen Prozesses, schreibt das Team.
Konsens zu finden sei nicht einfach und Technologie verschärfe die politische Spaltung häufig noch, statt eine Versöhnung zwischen unterschiedlichen Meinungen zu fördern. Große Sprachmodelle reagierten zwar empfindlich auf homogene Präferenzen, doch ihre Fähigkeit, Menschen bei der Suche nach Konsens zu helfen, sei bisher nicht getestet worden.

Deepmind setzt auf diverse Meinungen für KI-Training
Deepmind geht mit einer Variante eines 70 Milliarden Parameter Chinchilla-Sprachmodells dieses Problem an. Dafür erstellte das Team einen Korpus von tausenden Fragen zu politischen Themen, die in UK relevant sind. Die Firma rekrutierte zudem mehr als 1.500 Personen, die ihre unterschiedlichen Meinungen dazu aufschreiben.
Die Fragen umfassen zahlreiche Themen, etwa "Sollten wir ungesunde Lebensmittel und zuckerhaltige Getränke besteuern?", "Sollten wir die Eisenbahn wieder verstaatlichen?" oder "Sollten wir wohlhabende Menschen stärker besteuern?".
Für diese Fragen und unterschiedlichen Meinungen generierte dann ein einfaches Chinchilla-Sprachmodell einige Konsens-Vorschläge, die von den menschlichen Teilnehmer:innen bewertet wurden.
Hoch bewertete Konsens-Vorschläge wurden dann für ein Nachtraining des Chinchilla-Modells (SFT-base) genutzt. Zusätzlich trainierte das Team ein Belohnungsmodell, um individuelle Präferenzen vorherzusagen.
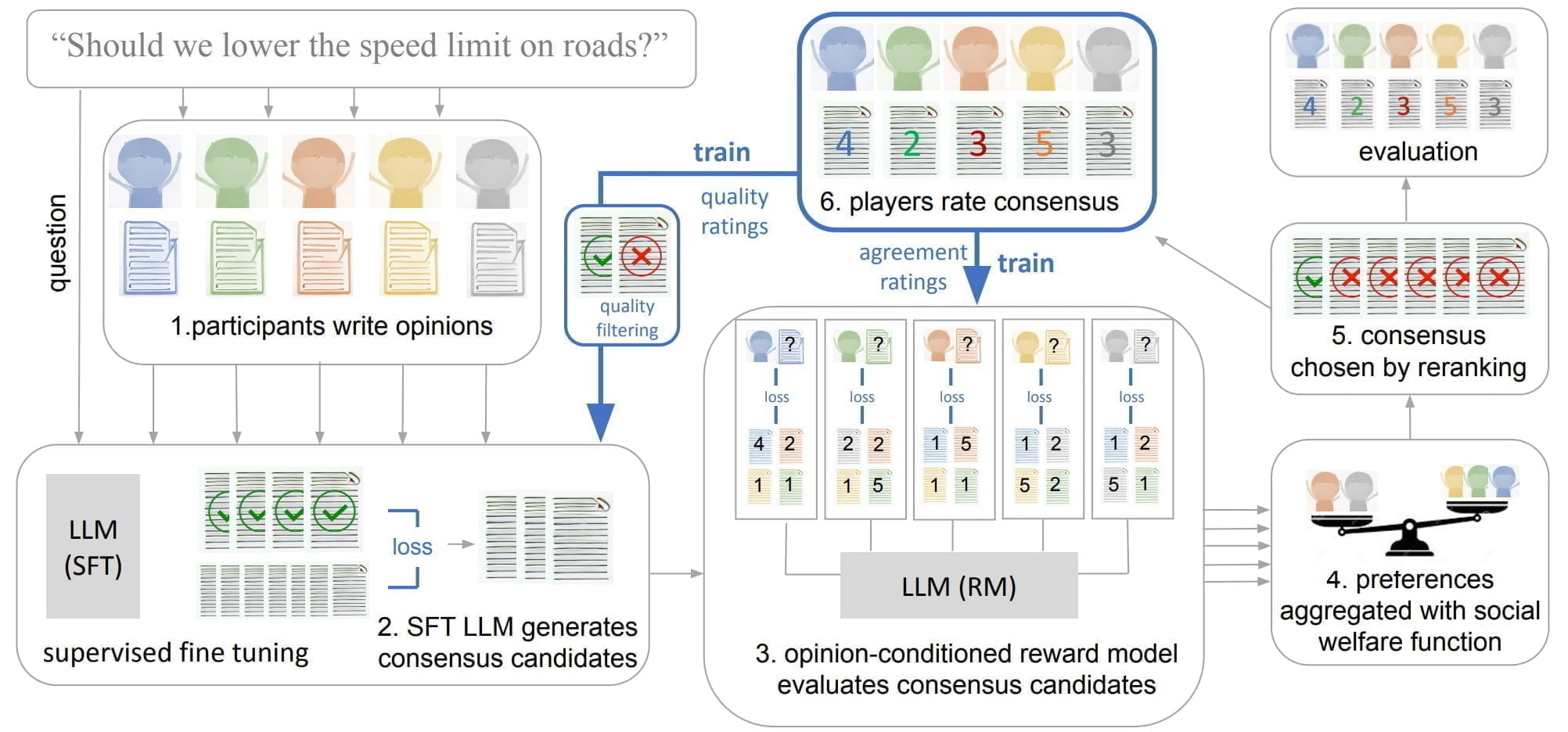
Das mit dem Belohnungsmodell erweiterte Chinchilla (SFT-Utilitarian) generiert 16 Konsensvorschläge und wählt den Vorschlag, der "die prognostizierte Wohlfahrt unter einer utilitaristischen (max-mean) Aggregationsfunktion maximiert." Andere Wohlfahrtsfunktionen (Rawlssche und Bernoulli-Nash) testete das Team ebenfalls, stellte aber keinen bedeutenden Unterschied fest.
Deepminds SFT-Utilitarian schafft mehr Konsens
Deepminds Trainingsmethode zielt nicht darauf ab, ein Sprachmodell zu trainieren, das bestimmte Meinungen übernimmt oder andere von einer bestimmten Ansicht überzeugt. Das Modell sei stattdessen darauf trainiert, "Konsenskandidaten auf der Grundlage der von der menschlichen Gruppe beigetragenen Meinungen zu produzieren."
Um den Erfolg der Methode einzuschätzen, untersuchte das Team rund 50 Prozent der Interaktionen, in denen Teilnehmende auf verschiedenen Seiten einer Position standen. In solchen spaltenden Runden seien die vom SFT-Utilitarian-Modell produzierten Konsensvorschläge in knapp 65 Prozent der Fälle von den Teilnehmenden als weniger divisiv als die ursprünglichen menschlichen Positionen bewertet worden.
In knapp 40 Prozent der untersuchten Runden habe zudem ein Konsensvorschlag des SFT-Utilitarismus-Modells einstimmige Unterstützung gefunden: Jeder Mensch stimmte der Aussage auf einer Likert-Skala in einer schwächeren oder stärkeren Form zu.
Zusammengenommen deuten diese Ergebnisse laut Deepmind darauf hin, dass Menschen die vom SFT-Utilitarian-Modell generierten Konsensvorschläge denen anderer Modelle vorziehen. Zudem könne das Modell selbst in schwierigen Fällen eine gemeinsame Basis finden.
Das Team warnt vor möglichem Missbrauch des Sprachmodells, sieht jedoch zugleich zahlreiche Applikationen in der Zukunft.
Das ultimative Ziel unserer Arbeit ist es, ein Instrument bereitzustellen, das sicher eingesetzt werden kann, um Menschen bei der Suche nach einer Einigung zu helfen. Wir konzentrieren uns auf Meinungen zu Debattenfragen, aber wir können uns eine breitere Palette von Anwendungsfällen vorstellen, z. B. die Zusammenfassung von Online-Rezensionen zu hilfreicheren Metareviews, Systeme für kollektives Schreiben, die automatisch die Präferenzen verschiedener Autoren berücksichtigen, und Systeme für die kollektive Entscheidungsfindung für organisierte Gruppen.
Wir weisen jedoch darauf hin, dass es noch erheblicher Anstrengungen bedarf, um die potenziellen Risiken im Zusammenhang mit der KI-Konsensfindung zu verstehen und Wege zu finden, sicherzustellen, dass die Modellergebnisse auf transparente und erklärbare Weise erzeugt werden, bevor ein solches System zum Einsatz kommen kann.
Deepmind




