DeepSeek-R1: Chinesisches Modell erreicht in Benchmarks Reasoning-Leistung von OpenAIs o1

Das KI-Startup DeepSeek stellt mit DeepSeek-R1 und DeepSeek-R1-Zero neue Reasoning-Modelle vor, die dem o1-Modell von OpenAI ebenbürtig sind. Zusätzlich werden sechs destillierte Open-Source-Modelle veröffentlicht, die teilweise mit OpenAI-o1-mini mithalten können.
Das chinesische KI-Startup DeepSeek hat nach einer ersten Preview im November 2024 seine neuesten Modelle DeepSeek-R1 und DeepSeek-R1-Zero vorgestellt. Das Besondere: Sie erreichen laut dem Unternehmen nicht nur die Leistung von OpenAIs o1, sondern sind auch offen verfügbar und das Team teilt in einem Paper seine Erfahrungen im Training der Modelle.
DeepSeek-R1-Zero erreicht Reasoning-Fähigkeiten ohne Extra-Daten
DeepSeek-R1-Zero wurde ausschließlich mit Reinforcement Learning trainiert, ohne das bei Sprachmodellen übliche vorherige Supervised Fine-Tuning (SFT) mit menschlichen Beispielen. Dabei entwickelte das Modell nach Angaben des Teams allein durch das RL-Feedback Reasoning-Verhalten wie Selbstüberprüfung, Reflexion und die Generierung langer Gedankenketten. So lernte das Modell nach Angaben des Teams während des Trainings, bestimmten Problemen mehr "Denkzeit" zu widmen, indem es seinen ursprünglichen Ansatz überprüfte. Das erinnert an Deepminds AlphaZero - der Name ist offensichtlich davon inspiriert.
"Dieser Moment ist nicht nur ein „Aha-Erlebnis“ für das Modell, sondern auch für die Forscher, die sein Verhalten beobachten. Er unterstreicht die Macht und Schönheit des Reinforcement Learnings: Anstatt dem Modell explizit beizubringen, wie es ein Problem zu lösen hat, geben wir ihm einfach die richtigen Anreize, und es entwickelt selbstständig fortgeschrittene Problemlösungsstrategien. Dieser „Aha-Moment“ erinnert uns eindringlich an das Potenzial von RL, neue Ebenen der Intelligenz in künstlichen Systemen zu erschließen und den Weg für autonomere und anpassungsfähigere Modelle in der Zukunft zu ebnen."
Aus dem Paper
Konkret setzt das Team für das RL auf ein regelbasiertes Belohnungssystem - bewusst ohne den Einsatz von neuronalen Reward-Modellen, da diese nach Ansicht des Teams zu "Reward Hacking" neigen - also Wege finden, hohe Belohnungen zu erhalten, ohne tatsächlich besser zu werden - und zusätzliche Rechenressourcen benötigt hätten.
Stattdessen verwendeten die Forscher ein regelbasiertes System für die Genauigkeit (z. B. direkter Vergleich der Lösung bei Matheaufgaben oder automatisierte Tests für Programmiercode) und ein System für das Format (Überprüfung, ob die Antworten in den richtigen Tags wie "think" und "/think" stehen).
Entscheidend für die Effizienz des Verfahrens ist der spezielle RL-Algorithmus "Group Relative Policy Optimization" (GRPO): Anstatt die Qualität jeder Antwort einzeln durch ein aufwändiges Belohnungsmodell zu bewerten, vergleicht GRPO die Antwortgruppen anhand des regelbasierten Belohnungssystems miteinander und leitet daraus ab, in welche Richtung die Modelle optimiert werden sollten.
Es gab jedoch auch Probleme: Die Antworten von DeepSeek-R1-Zero seien oft schwer lesbar und das Modell mische verschiedene Sprachen durcheinander. Um die Denk- und Textfähigkeiten weiter zu verbessern, entwickelte das Team DeepSeek-R1. DeepSeek-R1 verwendet eine kleine Menge von "Cold Start"-Daten für das anfängliche Training, gefolgt von mehreren RL-Durchgängen.
DeepSeek-R1 erreicht Reasoning-Leistung von OpenAI o1
Das endgültige DeepSeek-R1-Modell erreicht bei einer Vielzahl von Reasoning-Benchmarks eine mit OpenAI-o1-1217 vergleichbare Leistung. Auf AIME 2024 erreicht es eine Genauigkeit von 79,8 Prozent, auf MATH-500 sogar 97,3 Prozent. Auch bei Coding-Aufgaben zeigt DeepSeek-R1 Expertenleistung. So übertrifft es bei Codeforces 96,3 Prozent der menschlichen Teilnehmer.
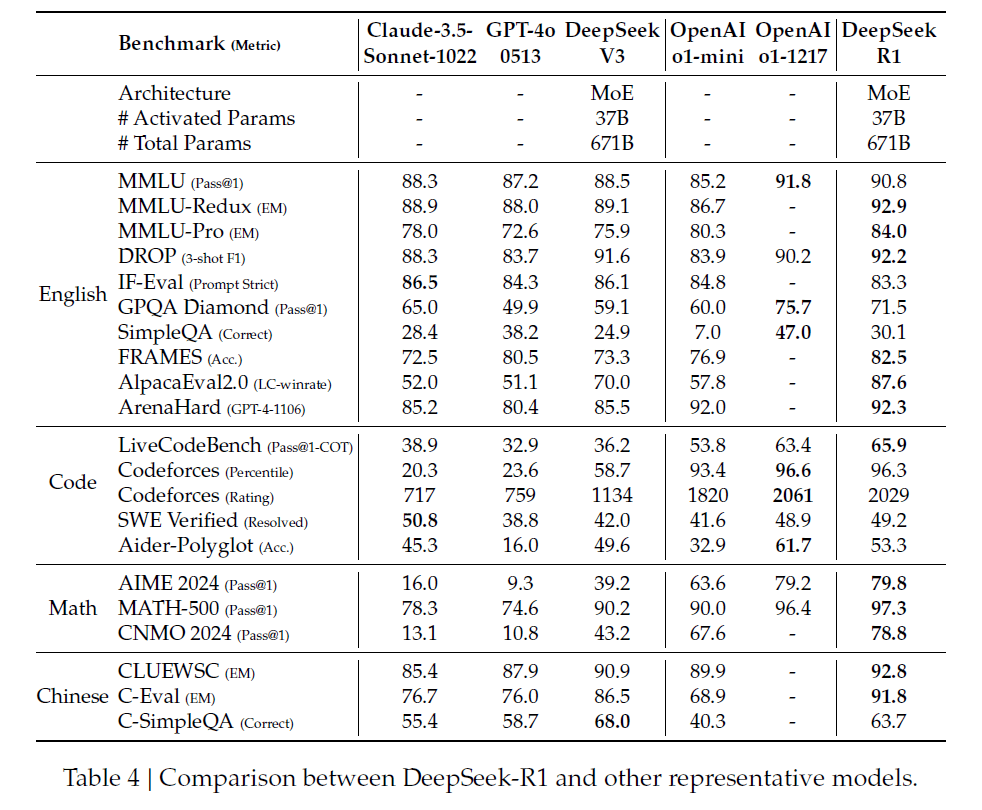
Neben den Reasoning-Fähigkeiten erreicht DeepSeek-R1 auch hohe Werte bei Wissens-Benchmarks wie MMLU, MMLU-Pro und GPQA Diamond, wo es DeepSeek-V3 deutlich übertrifft. Nur OpenAI-o1-1217 schneidet hier noch etwas besser ab. Auch bei kreativen Schreibaufgaben, Frage-Antwort-Aufgaben und Zusammenfassungen zeigt DeepSeek-R1 nach Angaben des Teams starke Leistungen.
Destillation ermöglicht Reasoning auch für kleinere Modelle
Neben dem 671 Milliarden Parameter großem MoE DeepSeek-R1 stellt DeepSeek auch sechs Modelle mit 1,5 bis 70 Milliarden Parametern vor. Um die Reasoning-Fähigkeiten von DeepSeek-R1 auf kleinere, effizientere Modelle zu übertragen, setzt DeepSeek auf Destillation. Dazu wurden 800.000 Trainingsdaten mit DeepSeek-R1 generiert und verschiedene kleinere Modelle wie Qwen und Llama damit verfeinert.
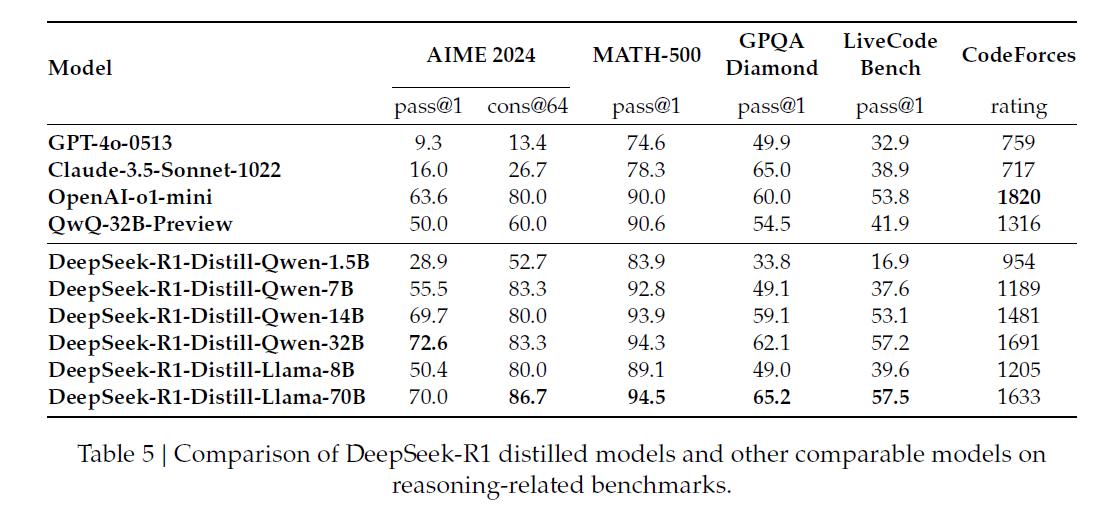
Die Ergebnisse sind vielversprechend: Die destillierten 32B- und 70B-Modelle erreichen in den meisten Benchmarks die gleiche oder eine bessere Performance als OpenAI-o1-mini. Besonders kurios: DeepSeek-R1-Distill-Qwen-1.5B übertrifft durch die Trainingsdaten GPT-4o und Claude-3.5-Sonnet bei Mathematik-Benchmarks. Das sagt jedoch wahrscheinlich mehr über die Grenzen von Benchmarks angesichts spezialisierter Trainingsdaten aus als über allgemeine Fähigkeiten des kleinen Modells.
Dass die destillierten Modelle jedoch generell so gut abschneiden, liegt laut DeepSeek daran, dass die Reasoning-Muster der großen Modelle entscheidend für die Leistungsfähigkeit sind. Ein direktes RL-Training auf kleineren Modellen führt nicht zu vergleichbaren Ergebnissen. Die destillierten Modelle sind als Open Source verfügbar.
DeepSeek will R1 weiter verbessern
Für die Zukunft plant DeepSeek, die allgemeinen Fähigkeiten von DeepSeek-R1 zu verbessern, insbesondere in Bezug auf Function Calling, Multi-Turn-Dialoge, komplexe Rollenspiele und JSON-Ausgabe. Hier hinkt das Modell nach Angaben des Start-ups anderen Modellen wie DeepSeek-V3 hinterher. Auch die auftretenden Sprachwechsel (Englisch und Chinesisch) und die Empfindlichkeit gegenüber Prompts sollen reduziert werden. So fiel die Leistung der Modelle bei der Verwendung von Few-Shot-Prompts deutlich ab. Viele dieser Einschränkungen entsprechen denen, die auch OpenAI bei der Ankündigung von o1 kommuniziert hat. Auch im Bereich des Software-Engineerings soll eine Leistungssteigerung durch mehr RL erreicht werden - laut Paper entwickelt das Team derzeit Methoden, um dies effizient umzusetzen.
Mit der nächsten Version könnte sich das Start-up dann dem kürzlich vorgestellten o3-Modell von OpenAI annähern - vorausgesetzt, das Team kann das bisherige Tempo halten und die vorgestellten Trainingsmethoden ermöglichen ähnliche Sprünge, wie sie OpenAI mit o3 innerhalb von drei Monaten gemacht hat. Denn wie genau die Firma hinter ChatGPT ihre Modelle o1 und o3 trainiert, bleibt ein Geschäftsgeheimnis. Auch ob DeepSeek-R1 in der Praxis tatsächlich mit OpenAIs o1 mithalten kann, muss sich in den kommenden Tagen zeigen.
Ab sofort ist DeepSeek-R1 über eine API öffentlich zugänglich. Nutzer können das Modell über den Parameter "model=deepseek-reasoner" ansprechen. Die Preise betragen $0.14 pro Million Input-Token für Cache-Treffer und $0.55 pro Million für Cache-Misses. Für die generierten Output-Token werden $2.19 pro Million berechnet.
DeepSeek-R1 steht unter der MIT-Lizenz, die die freie Verwendung der Modellgewichte und -outputs erlaubt. Auch die Verwendung der API-Outputs für Feintuning und Destillation ist erlaubt. Die destillierten Modelle auf Qwen- und Llama-Basis sind Open-Source.
Alle Informationen und Modelle sind auf GitHub bzw. HuggingFace zu finden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.