Deepseek-V3.2: Chinesisches KI-Startup senkt Preise um bis zu 75 Prozent
Deepseek führt mit V3.2-Exp eine effizientere Attention-Architektur für lange Kontexte ein und senkt die API-Preise um mehr als 50 Prozent. Die Leistung soll weitgehend auf dem Niveau des Vorgängers bleiben.
Deepseek hat das experimentelle Sprachmodell Deepseek-V3.2-Exp vorgestellt. Es basiert auf dem kürzlich vorgestellten V3.1-Terminus und führt eine neue Attention-Variante ein, die lange Kontexte effizienter verarbeitet.
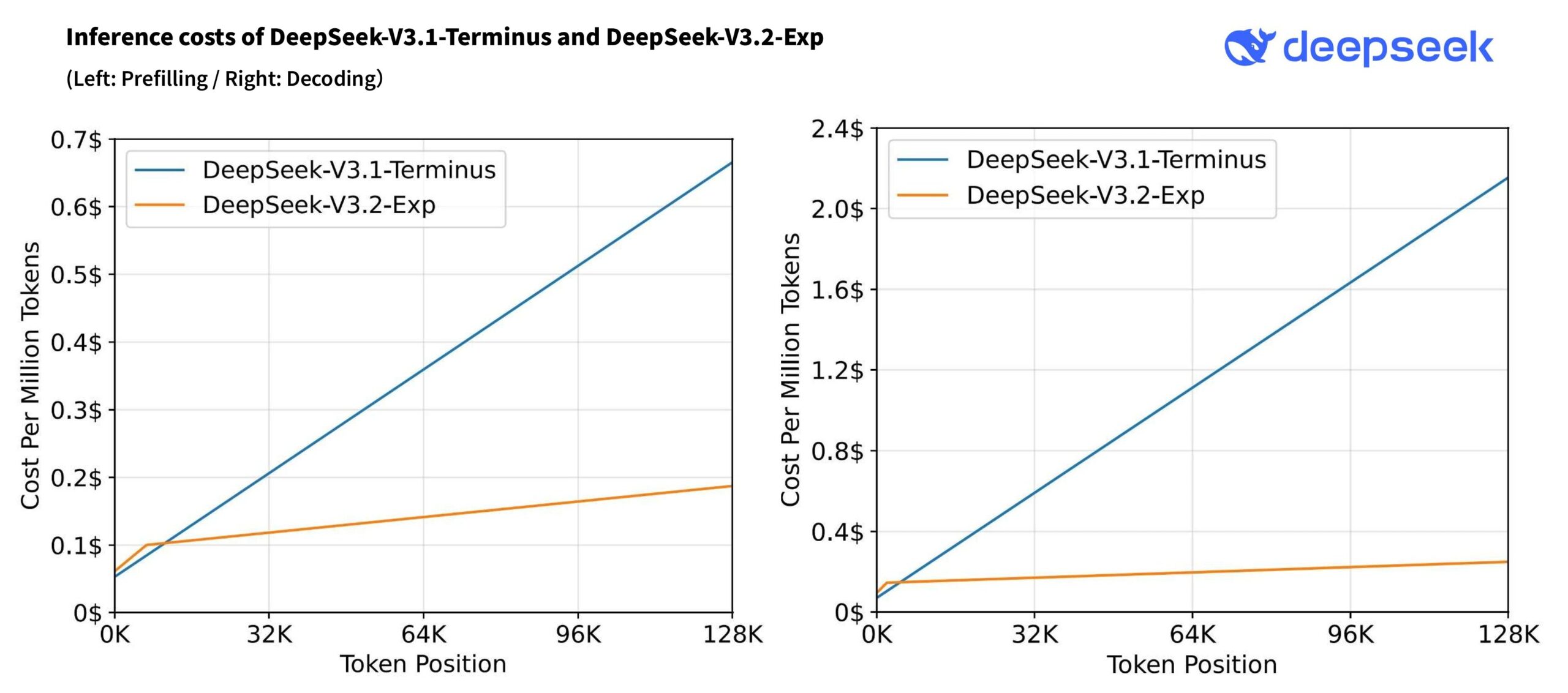
Kern der Aktualisierung ist DeepSeek Sparse Attention (DSA). Sie wählt nur die relevanten Teile des Kontexts aus und macht die Inferenz bei sehr langen Eingaben bis 128.000 Tokens deutlich günstiger; laut Diagramm im Tech-Report sind die Kosten bei 128K grob ~3,5× niedriger fürs Prefilling und ~6–7× fürs Decoding.
Ein weiterer Kernaspekt ist der Einsatz von TileLang als High-Level-Programmiermodell, das nicht auf eine einzelne Hardware-Plattform beschränkt ist. Dadurch kann das neue Modell vom Start weg auch auf KI-Chips chinesischer Anbieter wie Huawei Ascend und Cambricon laufen. Deepseek dürfte sich mit dem neuen Modell hier strategisch für die Zukunft ausgerichtet haben; China möchte sich aus der Abhängigkeit von KI-Chips des US-Herstellers Nvidias lösen.
Ähnliche Leistung für weniger als die Hälfte des Preises
In Benchmarks liegt Deepseek-V3.2-Exp laut Deepseek insgesamt auf Augenhöhe mit V3.1-Terminus. In einzelnen Tests gibt es leichte Gewinne oder Verluste, die das Unternehmen bei reasoning-lastigen Aufgaben auf kürzere Antworten zurückführt. Diese Lücke schließe sich bei Tests mit vergleichbarer Tokenlänge.
| Benchmark | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp |
|---|---|---|
| Reasoning Mode w/o Tool Use | ||
| MMLU-Pro | 85.0 | 85.0 |
| GPQA-Diamond | 80.7 | 79.9 |
| Humanity's Last Exam | 21.7 | 19.8 |
| LiveCodeBench | 74.9 | 74.1 |
| AIME 2025 | 88.4 | 89.3 |
| HMMT 2025 | 86.1 | 83.6 |
| Codeforces | 2046 | 2121 |
| Aider-Polyglot | 76.1 | 74.5 |
| Agentic Tool Use | ||
| BrowseComp | 38.5 | 40.1 |
| BrowseComp_zh | 45.0 | 47.9 |
| SimpleQA | 96.8 | 97.1 |
| SWE Verified | 68.4 | 67.8 |
| SWE-bench Multilingual | 57.8 | 57.9 |
| Terminal-bench | 36.7 | 37.7 |
Zwar bleibt die Leistung unverändert im Vergleich zum Vorgänger, aber die dazu gewonnene Effizienz wirkt sich massiv auf die Kosten aus: Die API-Preise wurden um 50 bis 75 Prozent gesenkt. Das wiederum könnte den Druck auf westliche Anbieter weiter verstärken, die proprietäre Modelle auf ähnlichem Niveau zu viel höheren Preisen anbieten, insbesondere Anthropic. Gleichzeitig gibt es jedoch ein teils begründetes Misstrauen gegenüber chinesischen Modellen, das den Schaden hier begrenzen dürfte.
| Neuer Preis | Alter Preis | Reduktion | |
|---|---|---|---|
| Input (Cache Hit) | 0,028 US-Dollar / 1 Mio. Tokens | 0,07 US-Dollar / 1 Mio. Tokens | -60% |
| Input (Cache Miss) | 0,28 US-Dollar / 1 Mio. Tokens | 0,56 US-Dollar / 1 Mio. Tokens | -50% |
| Output | 0,42 US-Dollar / 1 Mio. Tokens | 1,68 US-Dollar / 1 Mio. Tokens | -75% |
Verfügbarkeit und Zugang
Deepseek-V3.2-Exp ist ab sofort über mehrere Kanäle verfügbar: Die Web-Oberfläche bietet direkten Zugang zum Chatbot, während die mobile App für iOS und Android unterwegs genutzt werden kann. Entwickler können das Modell über die API in eigene Anwendungen integrieren. Die Modell-Checkpoints stehen zudem auf Hugging Face zum Download bereit. V3.1-Terminus bleibt für Vergleichstests über eine temporäre API bis zum 15. Oktober 2025 erreichbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.