Deepseek V3: Chinas stärkstes Open-Source-LLM schlägt teilweise GPT-4o und Claude
Das chinesische KI-Unternehmen Deepseek stellt sein bisher leistungsstärkstes Sprachmodell V3 vor, das insbesondere bei logischen Aufgaben verbessert wurde und in Benchmarks mit führenden proprietären Modellen mithalten und diese sogar übertreffen kann.
Deepseek hat sein neues Sprachmodell Deepseek-V3 vorgestellt, es steht ab sofort bei Github zum Download bereit. Laut des technischen Berichts handelt es sich um ein Mixture-of-Experts-Modell (MoE) mit insgesamt 671 Milliarden Parametern, von denen für jedes Token 37 Milliarden aktiviert werden.
Das Vorgängermodell Deepseek-V2 hatte insgesamt 236 Milliarden Parameter, von denen 21 Milliarden für die Inferenz aktiv waren. V3 wurde zudem auf 14,8 Billionen Token trainiert, fast doppelt so viele wie sein Vorgänger.
Nach Angaben von Deepseek dauerte das gesamte Training 2,788 Millionen H800-GPU-Stunden und kostete rund 5,576 Millionen US-Dollar. Trainiert wurde auf einem Cluster mit "nur" rund 2.000 GPUs - im Vergleich zu den 100.000 Grafikkarten, die Meta, xAI, OpenAI und Co. für das KI-Training einsetzen. Diese Effizienzsteigerung führt Deepseek auf sein optimiertes Co-Design von Algorithmen, Frameworks und Hardware zurück.

Ein besonderer Fokus lag auf der Verbesserung des logischen Denkens. Dafür nutzte Deepseek beim Post-Training ein spezielles Verfahren: Das Modell lernte von einem Ende November vorgestellten "Deepseek-R1"-Modell, das ähnlich wie OpenAIs o1 speziell für komplexe Denkketten entwickelt wurde.
Deutlich schneller als der Vorgänger
Nach Unternehmensangaben erreicht Deepseek-V3 eine Geschwindigkeit von 60 Token pro Sekunde und ist damit etwa dreimal schneller als sein Vorgänger. Die API-Preise bleiben im Vergleich zu Deepseek-V2 zunächst unverändert. Ab dem 8. Februar werden dann für Eingaben 0,27 US-Dollar pro Million Token berechnet (0,07 US-Dollar bei Cache-Treffern) und für Ausgaben 1,10 US-Dollar pro Million Token.
In Evaluierungen zeigt sich Deepseek-V3 als das derzeit stärkste Open-Source-Modell. Besonders bei Code- und Mathematikaufgaben übertrifft es andere quelloffene LLMs deutlich.
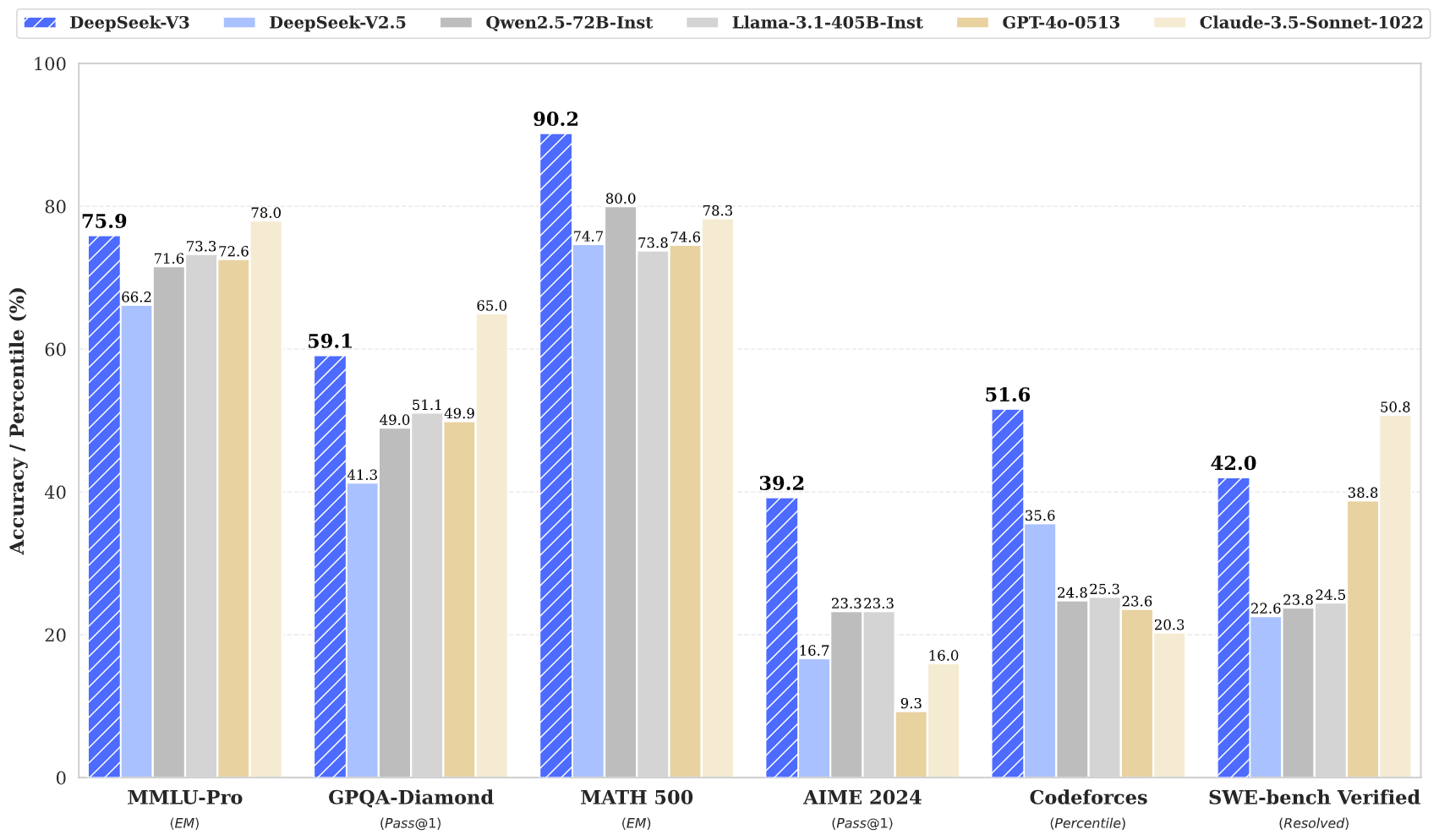
In vielen Benchmarks erreicht es laut Deepseek eine mit führenden proprietären Modellen wie GPT-4o und Claude-3.5-Sonnet vergleichbare Leistung. DeepkSee-v3 dürfte damit der klare Preis-Leistungs-Sieger am Markt sein.
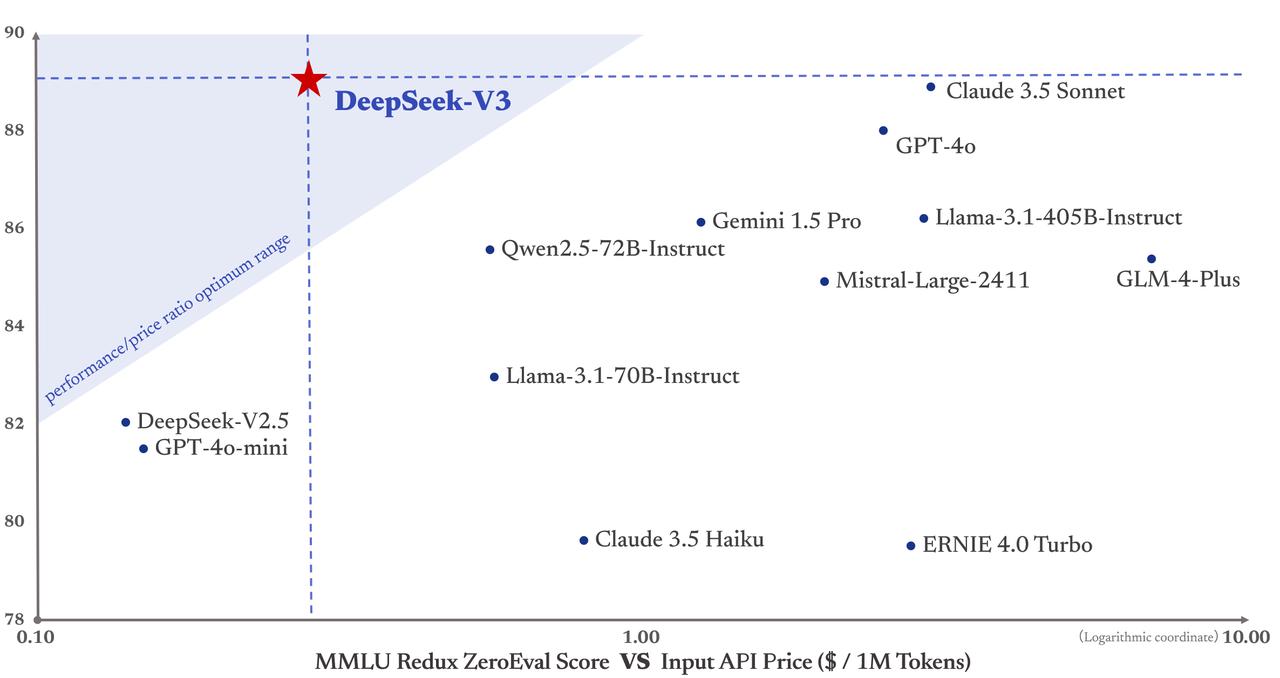
Deepseek-V3 wird unter der Deepseek License Agreement (Version 1.0) veröffentlicht. Diese Lizenz gewährt Nutzern eine kostenlose, weltweite, nicht-exklusive und unwiderrufliche Copyright- und Patentlizenz. Sie erlaubt die Vervielfältigung, Änderung und Verbreitung des Modells, auch zu kommerziellen Zwecken. Verboten ist unter anderem die militärische Nutzung oder die vollautomatisierte Nutzung im Rahmen von Rechtsfragen.
Für die Zukunft plant Deepseek weitere Verbesserungen der Modellarchitektur, die Firma möchte die "künstlichen Grenzen" der Transformer-Architektur durchbrechen, und die Unterstützung für unbegrenzte Kontextlängen. Langfristig strebt Deepseek nach eigenen Angaben ähnlich wie OpenAI eine schrittweise Annäherung an eine künstliche allgemeine Intelligenz (AGI) an.
Deepseek wurde 2023 gegründet und bietet verschiedene große Sprachmodelle für unterschiedliche Anwendungsfälle wie Mathematik und Coding an. Die Modelle sind Open Source und kostenlos für lokale Ausführung verfügbar, können aber auch über eine API genutzt werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.