DeepSeeks neues Modell klingt fast zu gut, um wahr zu sein: Es ist leistungsfähiger als einige bisherige LLMs, wird als Open Source entwickelt und ist gleichzeitig über Chat und eine kostengünstige API verfügbar. Die höhere Leistung zeigt sich bisher allerdings nur in einigen Disziplinen.
Das chinesische KI-Start-up DeepSeek hat vor kurzem DeepSeek-V2 veröffentlicht, ein großes Mixture-of-Experts-Sprachmodell (MoE), das eine optimale Balance zwischen hoher Leistung, niedrigen Trainingskosten und einer effizienten Inferenz anstrebt. Das Open-Source-Modell verfügt über insgesamt 236 Milliarden Parameter und unterstützt eine Kontextlänge von 128.000 Token.
Laut DeepSeek Research Paper baut DeepSeek V2 weiterhin auf der bewährten Transformer-Architektur auf, bei der jeder Transformer-Block aus einem Attention-Modul und einem Feed-Forward-Netzwerk besteht. An beiden Stellen gebe es jedoch wesentliche architektonische Neuerungen.
DeepSeek denkt den Transformer weiter
DeepSeek-V2 verwendet im Wesentlichen zwei Techniken: die Multi-Head Latent Attention (MLA) und die DeepSeekMoE-Architektur.
MLA komprimiert Schlüssel und Werte gemeinsam, um den benötigten Speicherplatz zu reduzieren und die Verarbeitungsgeschwindigkeit zu erhöhen. Dabei werden die Informationen, die für die Verarbeitung benötigt werden, in kompakter Form gespeichert, ähnlich wie Lesezeichen in einem Buch, die auf die wichtigsten Stellen hinweisen.
Die DeepSeekMoE-Architektur spezialisiert einzelne Experten und vermeidet Redundanzen, um leistungsfähigere Modelle zu geringeren Kosten zu erstellen. Sie teilt komplexe Aufgaben in kleinere Teilaufgaben auf, die von spezialisierten Experten bearbeitet werden, anstatt alle Informationen in einem einzigen großen Modell zu verarbeiten.
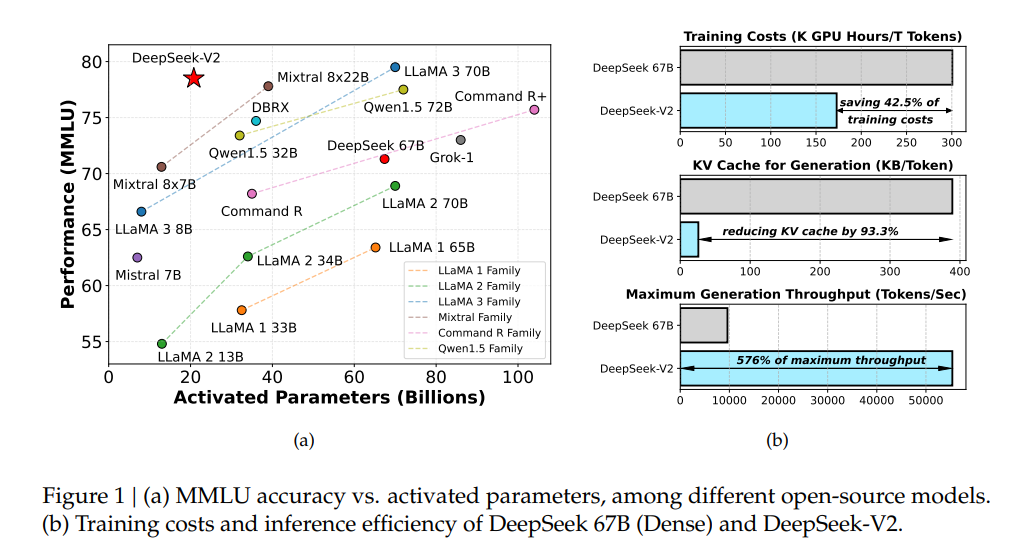
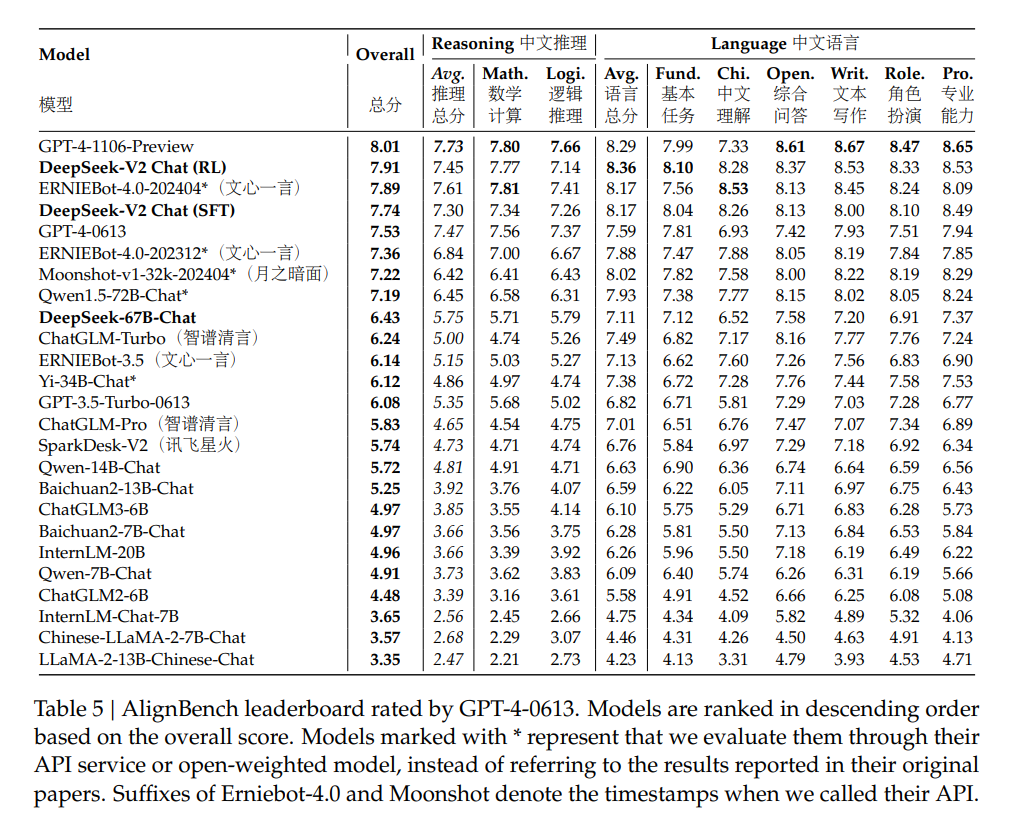
Die Forscherinnen und Forscher haben DeepSeek-V2 auf einem riesigen Korpus von 8,1 Billionen Token trainiert und im Vergleich zum Vorgänger vor allem hochwertige chinesische Daten hinzugefügt. Das erklärt auch die besseren Benchmark-Ergebnisse, besonders im Chinesischen.
Im Vergleich zu DeepSeek 67B spart DeepSeek-V2 42,5 Prozent der Trainingskosten, reduziert den Key-Value-Cache um 93,3 Prozent und erhöht den maximalen Generierungsdurchsatz um das 5,76-fache, generiert also Tokens deutlich schneller.
Großer Vorsprung in einzelnen Disziplinen
Neben dem Standardmodell DeepSeek-V2 haben die Wissenschaftler:innen Supervised Finetuning (SFT) mithilfe von 1,5 Millionen Konversationen sowie Reinforcement Learning (RL) eingesetzt, um die Chat-Varianten DeepSeek-V2 Chat (SFT) und DeepSeek-V2 Chat (RL) zu produzieren.
Die von DeepSeek-AI veröffentlichten Benchmark-Ergebnisse zeigen, dass DeepSeek-V2 mit nur 21 Milliarden aktivierten Parametern eine Spitzenleistung unter den Open-Source-Modellen erreicht und damit das derzeit leistungsstärkste Open-Source-MoE-Sprachmodell ist. Mixtral 8x22B und LLaMA 3-70B schlägt es in manchen Benchmarks um Längen.
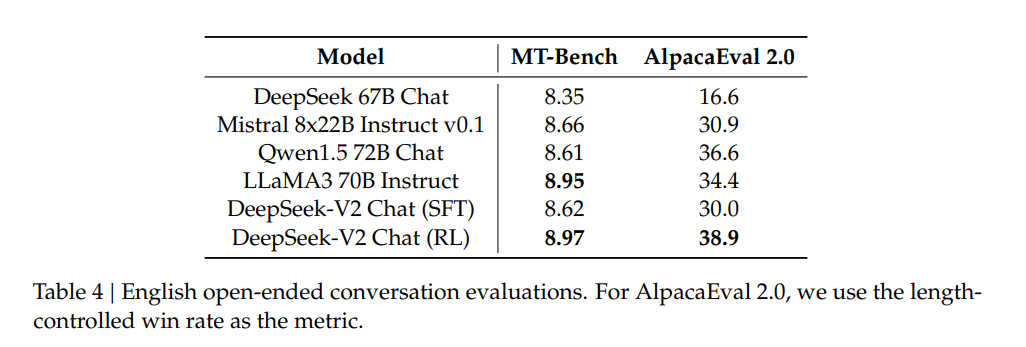
DeepSeek-V2 Chat, sowohl in der SFT- als auch in der RL-Variante, hat in manchen Benchmarks sowohl die bekannten KI-Modelle GPT-4-0613 und Ernie 4.0 übertroffen. Insbesondere die RL-Version von DeepSeek-V2 Chat glänzt mit einem herausragenden Verständnis der chinesischen Sprache und lässt dabei sogar das leistungsstarke GPT-4 Turbo hinter sich. Allerdings bleibe die Fähigkeit zum logischen Schlussfolgern bei DeepSeek-V2 Chat (RL) noch hinter großen Modellen wie Ernie 4.0 und den GPT-4-Modellen zurück.
DeepSeek verfolgt großes AGI-Ziel
DeepSeek wurde erst 2023 gegründet, kann aber bereits eine beachtliche Auswahl an großen Sprachmodellen für verschiedene Anwendungsfälle wie mathematische Aufgaben oder Coding vorweisen.
Die Modelle sind zwar Open Source und damit für die lokale Ausführung kostenlos verfügbar, gleichzeitig bietet DeepSeek sie aber auch über eine Programmierschnittstelle an, um sie ohne die notwendige Rechenleistung in eigene Produkte integrieren zu können. DeepSeek verspricht bei der Implementierung einen nahtlosen Übergang von der OpenAI-API zur eigenen.
Trotz seiner beeindruckenden Leistung hat DeepSeek die üblichen Einschränkungen, die großen Sprachmodellen gemein sind. So fließen keine aktuellen Informationen in die Trainingsdaten ein und Halluzinationen können nicht ausgeschlossen werden.
Dennoch will das Unternehmen weiter in große Open-Source-Modelle investieren, um sich (ähnlich wie OpenAI) schrittweise dem erklärten Ziel der AGI zu nähern. Dafür wollen die Wissenschaftler:innen auch in Zukunft auf die MoE-Architektur setzen und Kosteneffizienz und Leistung gleichermaßen steigern.
Preiswerte API
DeepSeek-V2 ist auf Hugging Face verfügbar und lässt sich nach Registrierung per E-Mail oder Google-Account auf chat.deepseek.com kostenlos ausprobieren.
Für die Chat-API (auf 32.000 Tokens Kontext beschränkt) veranschlagt DeepSeek 0,14 US-Dollar pro einer Million Token in der Ein- und 0,28 US-Dollar pro einer Million Token in der Ausgabe.
Im Vergleich dazu liegt das nächst günstigere, kommerzielle Sprachmodell Claude 3 Haiku bei 0,25 bzw. 1,25 US-Dollar.
DeepSeek-V2 bietet Innovationen durch die Überarbeitung der bewährten Mixture-of-Experts-Architektur und unterstreicht das Potenzial großer Open-Source-Modelle. Zum jetzigen Zeitpunkt stellt es noch keine generelle Alternative zu Claude 3 und GPT-4 dar, da es vor allem in der chinesischen Sprache bzw. bei Mathematik- und Coding-Aufgaben bessere Leistungen erbringt.
Für DeepSeek-V3 ist daher zu hoffen, dass das Start-up die bei der Entwicklung von V2 gewonnenen Erkenntnisse überträgt, sein Modell aber mit höherwertigen Daten in Englisch und anderen Sprachen trainiert. Angesichts der internationalen Vermarktung des Modells ist davon auszugehen.