
Das französische KI-Start-up Mistral AI hat mit Mixtral 8x22B ein neues Open-Source-Sprachmodell vorgestellt, das in puncto Performance und Effizienz Open-Source-Bestwerte erreicht.
Das Modell ist ein sogenanntes Sparse Mixture-of-Experts (SMoE) Modell, das von 141 Milliarden Parametern nur 39 Milliarden aktiv nutzt.
Damit bietet es nach Angaben des Entwicklerteams ein für seine Größe besonders gutes Kosten-Nutzen-Verhältnis. Bereits das Vorgängermodell Mixtral 8x7B wurde von der Open-Source-Community sehr positiv aufgenommen.
Zu den Stärken von Mixtral 8x22B sollen die Mehrsprachigkeit mit Englisch, Französisch, Italienisch, Deutsch und Spanisch sowie ausgeprägte Fähigkeiten in Mathematik und Programmierung zählen.
Zudem bietet es natives "Function Calling", um externe Werkzeuge einzusetzen. Das Kontextfenster ist mit 64.000 Token kleiner als bei derzeit führenden kommerziellen Modellen wie GPT-4 (128K) oder Claude 3 (200K).
Open Source ohne Einschränkungen
Das Team von Mistral setzt bei der Veröffentlichung von Mixtral 8x22B auf maximale Offenheit unter der Apache 2.0-Lizenz, der permissivsten Open-Source-Lizenz. Sie erlaubt die uneingeschränkte Nutzung des Modells.
Durch den Sparse-Einsatz aktiver Parameter sei es schneller als herkömmliche dicht trainierte 70-Milliarden-Modelle und gleichzeitig leistungsfähiger als andere Open-Source-Modelle, so Mistral.
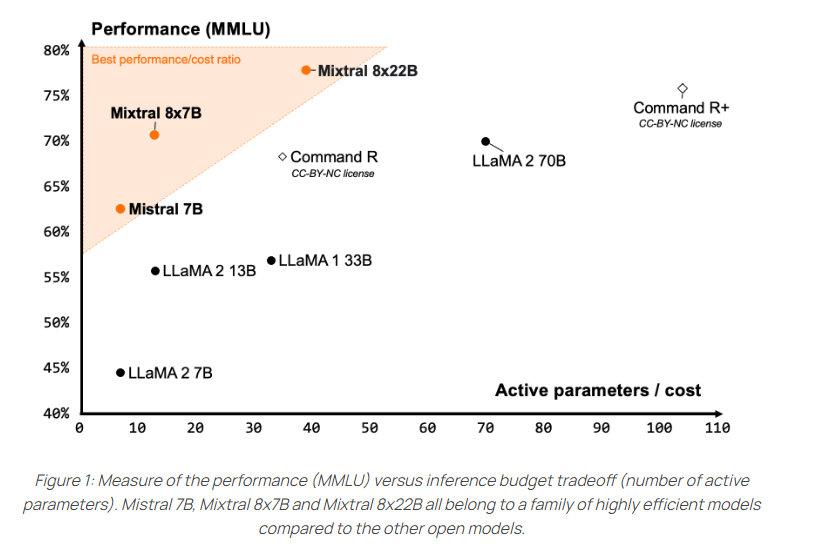
Die Verfügbarkeit des Basismodells mache es zudem zu einer guten Ausgangsbasis für Fine-Tuning-Anwendungen. Das Modell benötigt 258 Gigabyte VRAM.
Im Vergleich zu anderen offenen Modellen erzielt Mixtral 8x22B die besten Ergebnisse in den gängigen Verständnis-, Logik- und Wissenstests wie MMLU, HellaSwag, Wino Grande, Arc Challenge, TriviaQA und NaturalQS.

Auch in den unterstützten Fremdsprachen Französisch, Deutsch, Spanisch und Italienisch übertrifft es das LLaMA-2-Modell mit 70 Milliarden Parametern in den Benchmarks HellaSwag, Arc Challenge und MMLU deutlich.
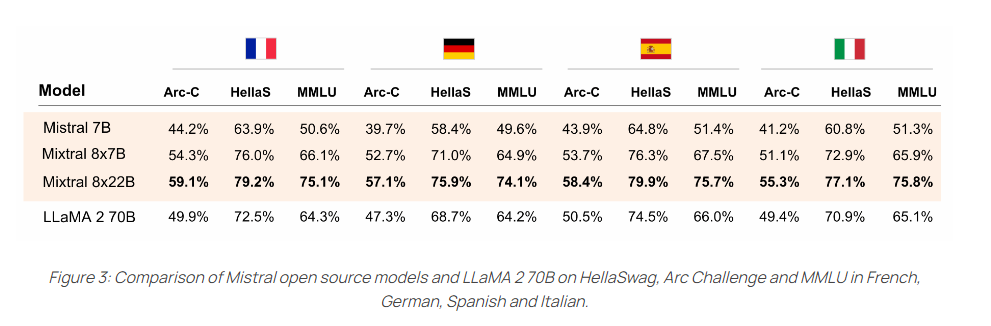
Das neue Modell kann ab sofort auf Mistrals "la Plateforme" getestet werden. Die Open-Source-Variante ist bei Hugging Face verfügbar.


