Deepseek verbessert Hybridmodell v3.1 für agentische KI-Prozesse
Deepseek stellt mit V3.1-Terminus ein Update seines KI-Modells vor, das konsistentere Ausgaben liefert und in Benchmarks mit verbesserter Tool-Nutzung punktet.
Deepseek hat mit V3.1-Terminus eine überarbeitete Version seines Hybrid-KI-Modells Deepseek-V3.1 veröffentlicht. Das Update adressiert laut Hersteller zentrale Schwächen der Vorgängerversion, darunter inkonsistente Sprache und instabile Ausgaben, und bringt Leistungsverbesserungen bei der Nutzung agentischer Prozesse.
So soll V3.1-Terminus zuverlässiger zwischen Chinesisch und Englisch unterscheiden und keine fehlerhaften Sonderzeichen mehr generieren. Auch die Leistung der eingebauten Agenten – darunter Code- und Suchagenten – wurde überarbeitet.
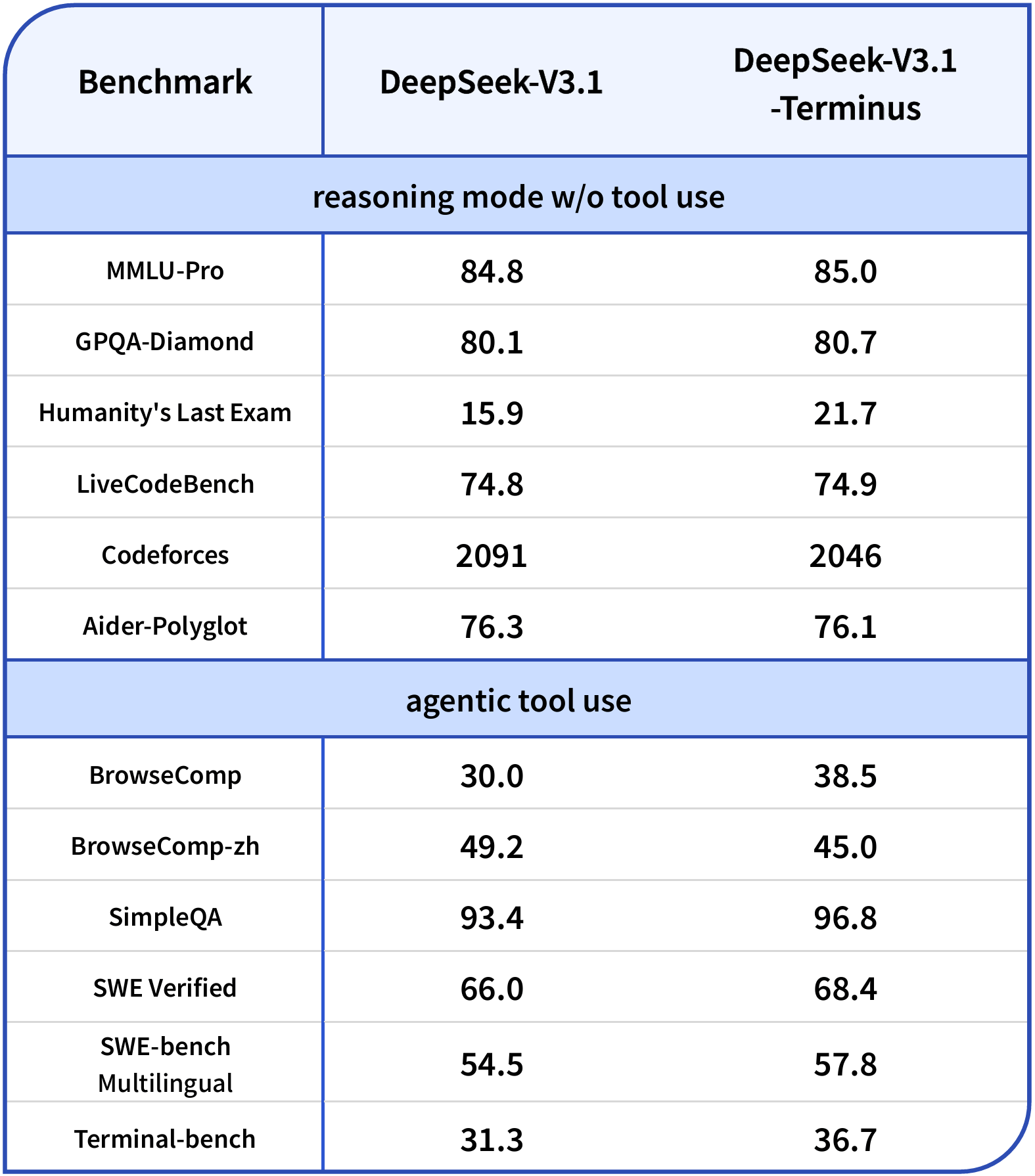
In Benchmarks zeigt sich ein differenziertes Bild: Besonders bei Aufgaben mit Tool-Nutzung erreicht das Modell teils deutliche Zugewinne. Im Benchmark BrowseComp steigt die Punktzahl von 30,0 auf 38,5, im Terminal-bench von 31,3 auf 36,7. Im Reasoning-Modus ohne Tool-Nutzung bleiben die Unterschiede weitgehend gering.
Das Modell ist über App, Web und API zugänglich, die Open-Source-Gewichte stehen auf Hugging Face unter einer MIT-Lizenz zur Verfügung.
Zwei Denkmodi und aggressive Preisstrategie
V3.1-Terminus basiert auf dem im August vorgestellten Modell Deepseek-V3.1, das erstmals zwei Betriebsmodi kombinierte: einen "denkenden" Modus (Deepseek-reasoner) für komplexere Aufgaben mit Tool-Nutzung und einen "nicht-denkenden" Modus (Deepseek-chat) für einfache Konversationen. Beide Modi unterstützen ein Kontextfenster von bis zu 128.000 Tokens.
Das Modell wurde mit 840 Milliarden zusätzlichen Tokens trainiert, ergänzt durch ein neues Tokenizer-Setup und überarbeitete Prompt-Vorlagen. In Tests erzielte Deepseek-V3.1 bereits gute Ergebnisse, etwa im Vergleich zu aktuellen Hybridmodellen von OpenAI und Anthropic.
Auch preislich bleibt Deepseek aggressiv: Die Ausgabe von Tokens kostet 1,68 US-Dollar pro Million Tokens – deutlich günstiger als GPT-5 (10,00 USD) oder Claude Opus 4.1 (bis zu 75,00 USD). Die Input-API kostet bei Cache-Treffer 0,07 US-Dollar pro Million Tokens, bei Cache-Fehlschlag 0,56 US-Dollar.
Wie alle chinesischen KI-Modelle unterliegt auch Deepseeks neuestes Modell chinesischer Staatszensur und wird so speziell bei politischen Themen zu einem Propagandainstrument der chinesischen Regierung. Die Trump-Regierung in den USA will für US-Modelle ähnliche Zensur-Maßnahmen umsetzen. Dass sich solche Eingriffe unmittelbar auf die Performance auswirken können, zeigte kürzlich ein Coding-Review von Deepseek.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.