Deepseeks OCR 2-Modell verarbeitet Bilder so, wie das menschliche Auge sie wahrnimmt
Kurz & Knapp
- Das chinesische KI-Unternehmen Deepseek hat mit Deepseek OCR 2 einen Vision-Encoder vorgestellt, der Bildinformationen nach inhaltlichen Zusammenhängen verarbeitet.
- Das Modell benötigt mit 256 bis 1.120 Token pro Bild deutlich weniger als vergleichbare Systeme. Auf dem OmniDocBench Benchmark erreicht es 91,09 Prozent, ein Plus von 3,73 Prozentpunkten gegenüber dem Vorgänger.
- Die Forscher sehen in der Architektur einen Schritt zu einheitlichen multimodalen Encodern. Diese könnten künftig Text, Sprache und Bilder mit demselben Grundgerüst verarbeiten.
Das chinesische KI-Unternehmen Deepseek hat einen neuartigen Vision-Encoder vorgestellt, der Bildinformationen semantisch neu anordnet, statt sie starr von links oben nach rechts unten zu verarbeiten.
Herkömmliche Vision-Sprach-Modelle zerlegen Bilder in kleine Abschnitte und verarbeiten diese in fester Reihenfolge, immer von oben links nach unten rechts. Laut den Forschern von Deepseek widerspricht das der menschlichen visuellen Wahrnehmung. Das menschliche Auge folge flexiblen Mustern, die sich am Inhalt orientieren. Beim Nachverfolgen einer Spirale etwa springt der Blick nicht zeilenweise über das Bild, er folgt der Form.
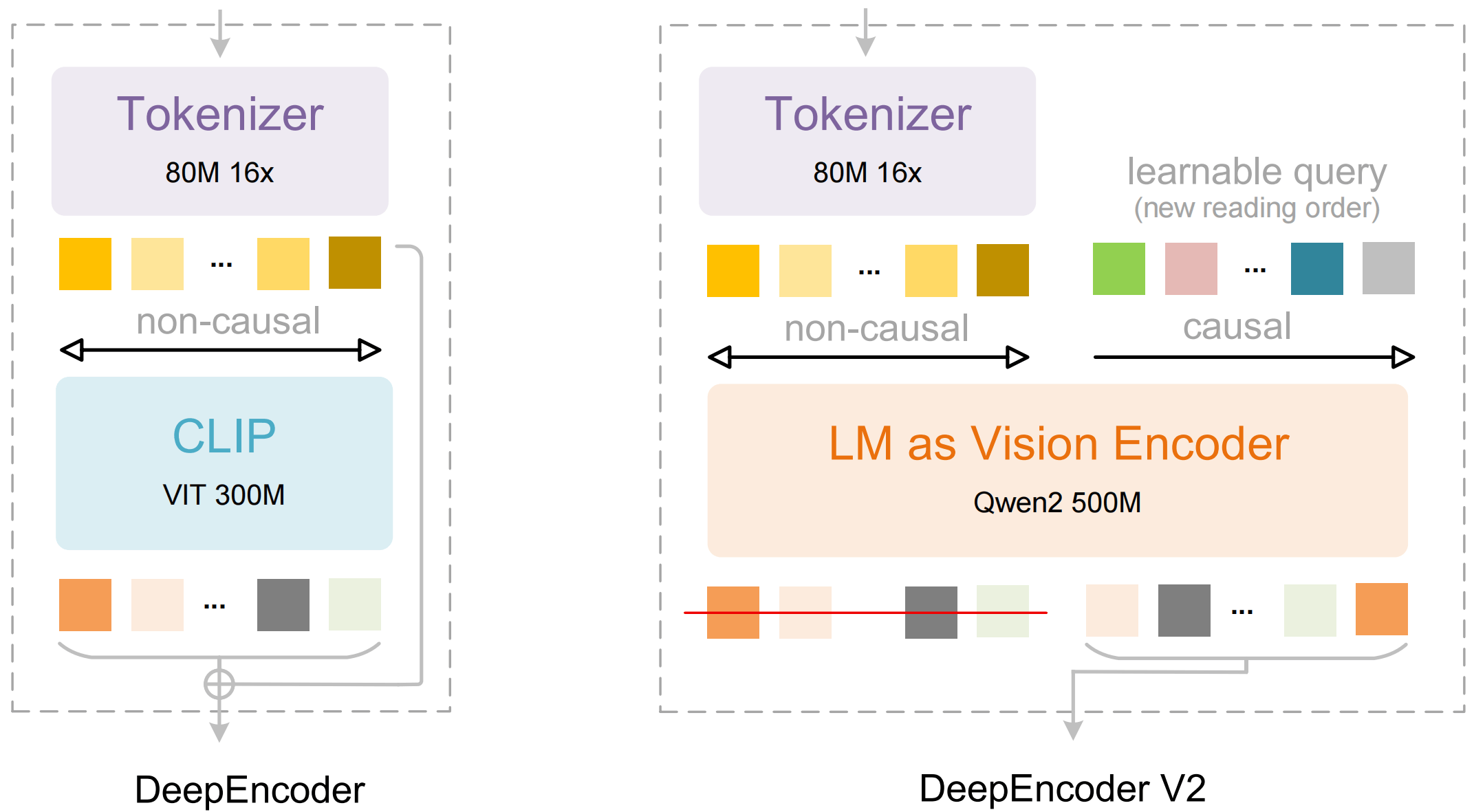
Mit Deepseek OCR 2 präsentiert das Unternehmen einen neuen Ansatz. Der sogenannte DeepEncoder V2 verarbeitet visuelle Token zunächst inhaltlich: Er ordnet sie nach Zusammenhängen neu an, bevor ein Sprachmodell die Inhalte interpretiert. Die Idee dahinter: Zwei hintereinandergeschaltete Verarbeitungsschritte könnten gemeinsam ein echtes Verständnis zweidimensionaler Bildinhalte ermöglichen.
Sprachmodell Architektur ersetzt klassischen Vision Encoder
Der technische Kern von DeepEncoder V2: Deepseek ersetzt die übliche CLIP Komponente durch eine kompakte Sprachmodell Architektur auf Basis von Alibabas Qwen2 0.5B. Dafür führen die Forscher sogenannte Causal Flow Tokens ein. Diese lernbaren Abfrage-Token werden an die visuellen Token angehängt und können alle Bildinformationen sowie alle vorhergehenden Abfragen berücksichtigen.
Aus dem Mechanismus entsteht laut der Publikation eine zweistufige Verarbeitung. Zunächst ordnet der Encoder die visuellen Informationen nach inhaltlichen Kriterien neu. Anschließend schlussfolgert der nachgeschaltete LLM Decoder über die bereits sortierte Sequenz. An den Decoder gehen nur die neu angeordneten Causal Flow Tokens, nicht die ursprünglichen visuellen Token.
Deutlich weniger Token bei besserer Leistung
Deepseek OCR 2 arbeitet je nach Bild mit 256 bis 1.120 visuellen Token. Vergleichbare Modelle benötigen häufig mehr als 6.000 oder 7.000 Token. Auf OmniDocBench v1.5, einem Benchmark für Dokumentenverarbeitung mit 1.355 Seiten in neun Kategorien, erreicht das Modell laut den Forschern eine Gesamtbewertung von 91,09 Prozent.
Das entspreche einem Plus von 3,73 Prozentpunkten gegenüber dem Vorgänger Deepseek OCR. Besonders deutlich sei der Gewinn bei der Erkennung der korrekten Lesereihenfolge. Beim Dokumenten-Parsing übertreffe Deepseek OCR 2 zudem Gemini 3 Pro bei vergleichbarem Token-Budget.
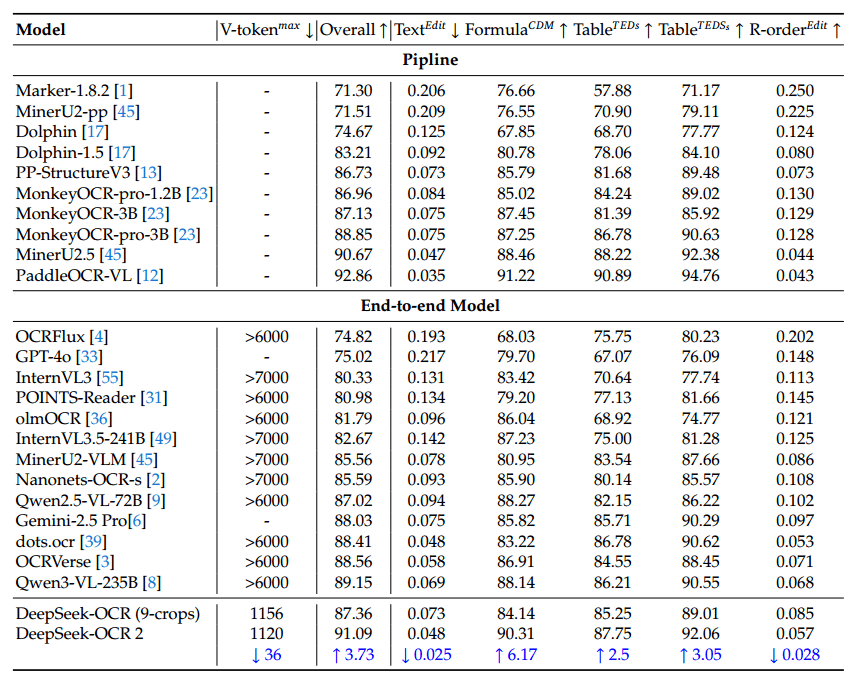
In der praktischen Anwendung habe sich auch die Wiederholungsrate verbessert, also wie oft das Modell in redundante Textschleifen verfällt. Beim Einsatz als OCR Service für die Deepseek Sprachmodelle sank diese Rate von 6,25 auf 4,17 Prozent, bei der Batchverarbeitung von PDFs für Trainingsdaten von 3,69 auf 2,88 Prozent. Das Modell zeigt dem Paper zufolge allerdings Schwächen bei bestimmten Dokumenttypen. Bei Zeitungen etwa schneide es schlechter ab als der Vorgänger.
Die Forscher führen dies auf zwei Faktoren zurück: Die niedrigere Token Obergrenze könne bei textreichen Zeitungsseiten problematisch sein, zudem enthielten die Trainingsdaten mit nur 250.000 Zeitungsseiten zu wenig Material dieser Kategorie.
Ausblick auf einheitliche Multimodal Architektur
Die Forscher sehen in DeepEncoder V2 einen Schritt in Richtung einheitlicher multimodaler Verarbeitung. Die Encoder Architektur könne sich perspektivisch so weiterentwickeln, dass sie Text, Sprache und Bilder mit demselben Grundgerüst verarbeitet und nur die Abfrage Token je nach Modalität anpasst. Langfristig könnte der Ansatz laut dem Paper zu einem echten Verständnis zweidimensionaler Inhalte führen.
Code und Modellgewichte sind öffentlich auf GitHub und Hugging Face verfügbar.
Deepseek hatte erst im Oktober 2025 die erste Generation von Deepseek OCR vorgestellt. Das System verarbeitet Textdokumente als Bild und reduziert dabei den Speicherbedarf um das Zehnfache. Sprachmodelle können dadurch deutlich mehr Kontext im Gedächtnis behalten, was etwa für lange Chatverläufe oder umfangreiche Dokumente relevant ist. Das System kann laut Deepseek täglich bis zu 33 Millionen Seiten verarbeiten und eignet sich besonders zur Generierung großer Trainingsdatensätze.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren