Qwen2 setzt neue Maßstäbe bei Open-Source-Sprachmodellen
Das neuste Modell aus Alibabas Cloud-Computing-Abteilung setzt sich im Vergleich zu anderen Open-Source-Modellen in Benchmarks souverän an die Spitze.
Die Cloud-Computing-Einheit des chinesischen E-Commerce-Giganten Alibaba arbeitet seit längerer Zeit unter dem Namen Qwen an einem leistungsfähigen Sprachmodell. Jetzt erschien mit Qwen2 die neuste Version, die mit bedeutenden Verbesserungen in verschiedenen Bereichen wie Programmierung, Mathematik, Logik und mehrsprachigem Verständnis aufwarten kann. Die erste Generation veröffentlichten die Forschenden erst im August 2023.
Mit viel mehr Sprachen trainiert
Laut dem Blogbeitrag des Qwen-Teams umfasst Qwen2 vortrainierte und instruktionsoptimierte Modelle in fünf Größen, die von 0,5 Milliarden bis zu 72 Milliarden Parametern reichen. Die Modelle wurden mit Daten in 27 weiteren Sprachen, darunter auch Deutsch, Französisch, Spanisch, Italienisch, Russisch, neben Englisch und Chinesisch trainiert, was nach Ansicht des Teams ihre mehrsprachigen Fähigkeiten stärken wird.
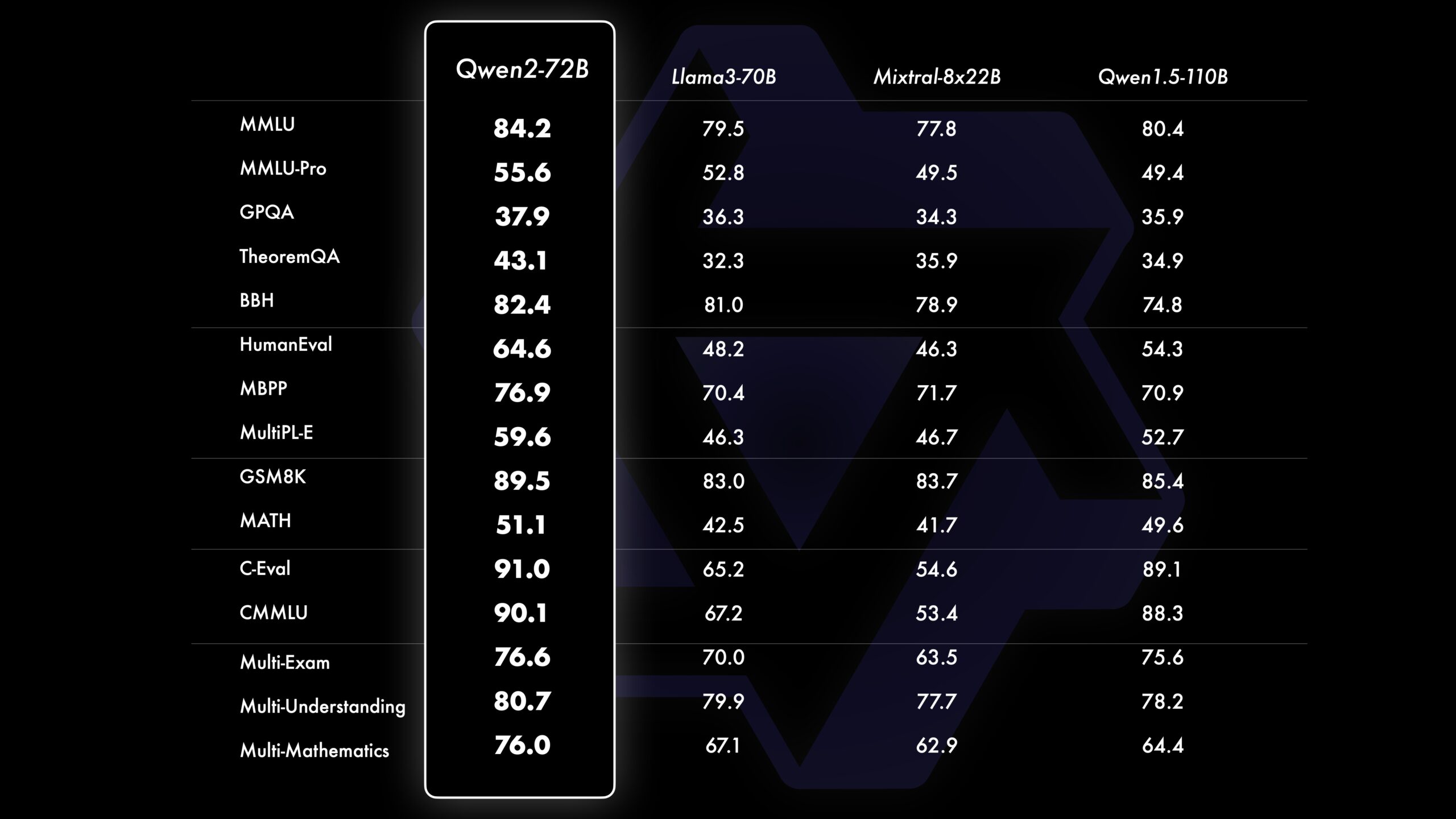
Gegenüber dem Vorgänger bietet Qwen2 zudem verbesserte Leistung in den Bereichen Programmierung und Mathematik. Insbesondere Qwen2-72B-Instruct zeigt laut dem Team signifikante Verbesserungen in verschiedenen Programmiersprachen durch die Integration von Erfahrungen und Daten aus CodeQwen1.5. In einem vom Team gezeigten Vergleich übertrifft Qwen2-72B Metas Llama3-70B in allen getesteten Benchmarks, teilweise mit deutlichem Abstand.
Qwen2 findet Nadel im Heuhaufen zuverlässig
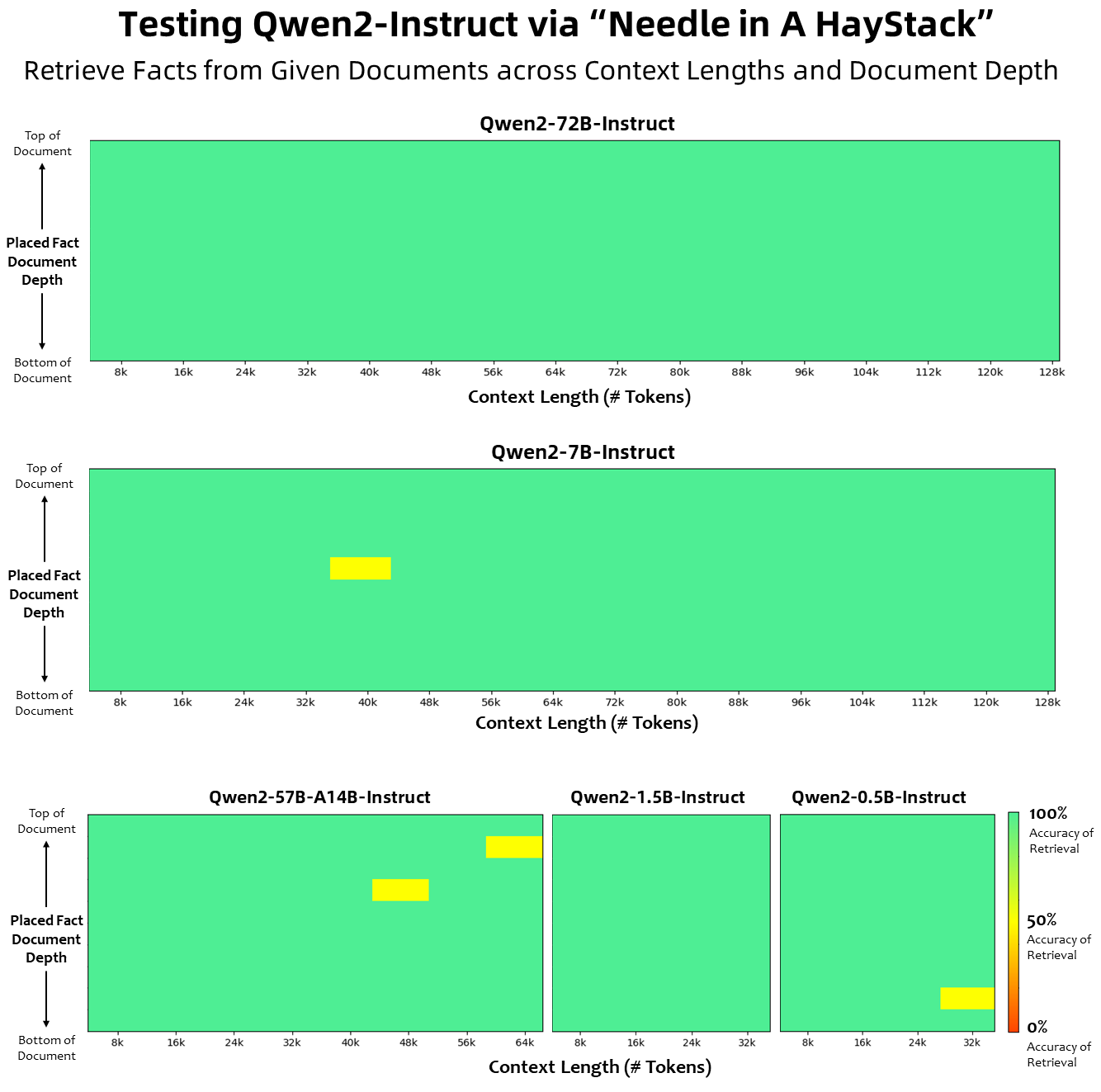
Die Qwen2-Modelle zeigen auch ein beeindruckendes Verständnis für lange Kontexte. Alle instruktionsoptimierten Modelle wurden mit Kontextlängen von mindestens 32.000 Tokens trainiert. Qwen2-72B-Instruct ist in der Lage, Informationsextraktionsaufgaben innerhalb eines Kontextes von 128.000 Tokens fehlerfrei zu bewältigen, Qwen2-57B-A14B unterstützt 64.000 Tokens. Mit diesem "Needle in a Haystack" genannten Problem haben Sprachmodelle vor allem mit großen Kontextfenstern traditionell schwer zu kämpfen.
In Bezug auf Sicherheit und Verantwortung führte das Qwen-Team Tests mit unsicheren Abfragen durch, die in mehrere Sprachen übersetzt wurden. Sie stellten fest, dass das Qwen2-72B-Instruct-Modell in puncto Sicherheit vergleichbar mit GPT-4 abschneidet und Mistral-8x22B deutlich übertrifft.
Wie bei chinesischen Sprachmodellen üblich, verweigert auch Qwen2 allerdings auch Antworten auf Fragen zum Tian’anmen-Massaker und anderen Themen, die im chinesischen Diskurs tabu sind.
Neue Open-Source-Lizenz für meiste Modelle
Mit dieser Veröffentlichung hat das Qwen-Team außerdem die Lizenzen für seine Modelle geändert. Während Qwen2-72B und seine instruktionsoptimierten Modelle weiterhin die ursprüngliche Qianwen-Lizenz verwenden, haben alle anderen Modelle Apache 2.0 übernommen. Das Team ist der Ansicht, dass die verbesserte Offenheit ihrer Modelle gegenüber der Community die Anwendungen und die kommerzielle Nutzung von Qwen2 weltweit beschleunigen kann.
In Zukunft will das Qwen-Team noch größere Qwen2-Modelle trainieren, darunter auch multimodale Varianten mit Bild- und Audiodaten. Künftige Modelle wollen die Forschenden ebenfalls Open Source veröffentlichen.
Code und Gewichte haben die Forschenden bei GitHub bzw. Hugging Face hochgeladen. Eine Demo für Qwen2-72B-Instruct findet sich hier. Ein technisches Paper mit genaueren Informationen zu Aufbau und Trainingsmaterial fehlt bislang, soll jedoch ebenfalls bald folgen.
Das Qwen-Team setzt auf ein großes Feld an Partner*innen, die beispielsweise Finetuning, lokale Ausführung oder Anbindung an RAG-Systeme erleichtern.
![]()
Open-Source-Modelle befinden sich damit weiterhin auf Erfolgskurs, nicht was deren Verbreitung, aber zumindest, was deren technische Möglichkeiten anbelangt. In den letzten Monaten wurde nicht nur Metas LLaMA 3 veröffentlicht, sondern etwa auch Mixtral-8x22B und DeepSeek-V2, die sich alle ein Kopf-an-Kopf-Rennen in Benchmarklisten liefern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.