
Google Gemini 1.5 bietet ein Kontextfenster mit bis zu einer Million Token. Damit kann es riesige Datenmengen auf einen Schlag verarbeiten. Aber ist es auch präzise?
Denn was nützt die Zusammenfassung eines Textes oder die Analyse eines Geschäftsberichts, wenn man immer damit rechnen muss, dass wichtige Details fehlen oder ein Sachverhalt ungenau wiedergegeben wird.
Tatsächlich ist das derzeit bei anderen Sprachmodellen mit großen Kontextfenstern wie GPT-4 Turbo mit 128K oder Claude 2 mit bis zu 200K der Fall. In der Praxis zeigt sich, dass selbst Modelle mit "kleinen" Kontextfenstern von 8K bis 32K relevante Details, insbesondere in der Mitte des Textes, auslassen können, obwohl sie nur mit kleinen Textmengen gefüttert und im Prompt spezifisch angewiesen werden, jedes Detail im Quelltext zu beachten. Dieses LLM-Phänomen wird als "Lost in the middle" bezeichnet.
Beim Auffinden einer einzelnen, spezifischen Information im "Needle in the haystack"-Test erreicht Gemini 1.5 über die gesamte Kontextlänge zwar eine in den sozialen Medien viel zitierte Trefferquote von bis zu 100 Prozent. Das schafft in Googles Tests allerdings auch GPT-4 Turbo bis 128K. Und aus Theorie und Praxis wissen wir, dass GPT-4 Turbo 128K bei langen Zusammenfassungen und Analysen nicht zuverlässig arbeitet.
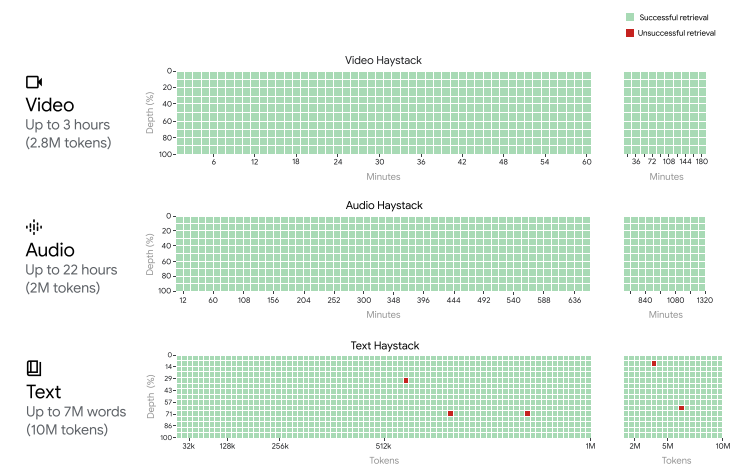
Irreführende Benchmarks für Kontextfenster-Leistung
Schaut man sich Googles Modellbericht zu Gemini 1.5 genauer an, findet man eine Grafik, die zeigt, dass Google das Lost-in-the-Middle-Problem nicht gelöst hat. Der Test "Multiple needles in a haystack", bei dem bis zu 100 spezifische Informationen aus dem Text extrahiert werden sollen, zeigt eine durchschnittliche Genauigkeit zwischen 60 und 70 Prozent, mit zahlreichen Ausreißern unter die 60-Prozent-Marke.
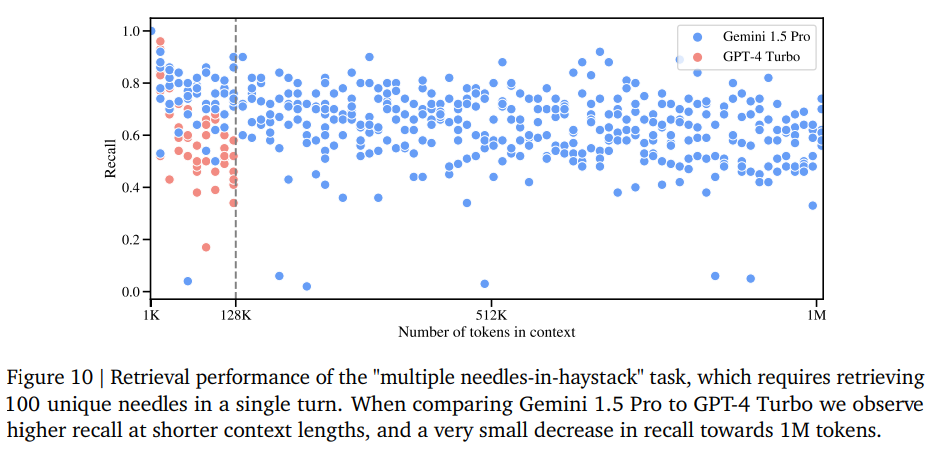
Das scheint bis 128K eine Verbesserung gegenüber GPT-4 Turbo zu sein, und die Genauigkeit scheint sich recht gleichmäßig über das Kontextfenster verteilt zu sein, was gut ist.
Aber würde man einen Textanalysten damit beauftragen, eine Zusammenfassung eines Dokuments zu erstellen, wenn man von vornherein weiß, dass er wahrscheinlich 30 Prozent des Inhalts einfach ignorieren wird?
Darüber hinaus ist selbst der "Multiple Needle in the Haystack"-Test noch zu einfach im Vergleich zu den meisten realen Anwendungsszenarien, in denen nicht nach bestimmten Informationen in einer Datenmenge gesucht wird, sondern komplexe, unkonkrete Probleme wie Zusammenfassungen und Analysen gelöst werden sollen.
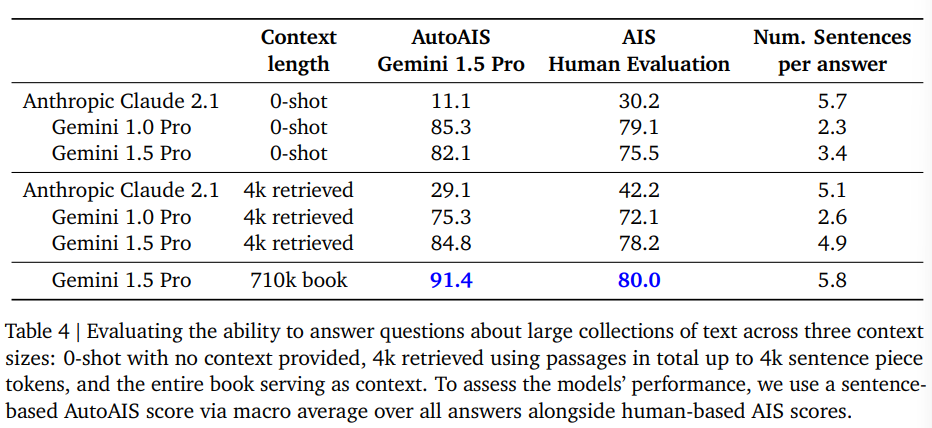
Google hat in einem komplexeren Test 100 Fragen zum Buch "Les Misérables" von Victor Hugo mit insgesamt 710.000 Token gestellt und die Antworten nach der Methode "Attributable to Identified Sources" ausgewertet. Bei der menschlichen Auswertung konnten 80 Prozent der Antworten dem Quelldokument zugeordnet werden, bei der maschinellen Auswertung 91 Prozent.

Das sagt jedoch nichts über die Vollständigkeit der Aussagen und deren Nuancierung aus. Ob das Buch und die Charaktere so wiedergegeben werden, wie von Victor Hugo beabsichtigt, kann mit diesem Benchmark nicht beurteilt werden. Zudem lag Gemini 1.5 Pro bei Prompts ohne zusätzlichen Kontext hinter Gemini 1.0 mit zusätzlicher Wissensdatenbank (RAG).
Zwar gibt es derzeit viele begeisterte Tests in sozialen Medien von Personen, die bereits Zugang zu Gemini 1.5 haben. Es scheint jedoch, dass die Ergebnisse oft nur oberflächlich ausgewertet werden, eher im Sinne eines Funktionstests.
Ja, das Modell kann das gesamte Kontextfenster durchleuchten. Bei diesen analytischen Aufgaben steckt der Teufel jedoch im Detail. Ob eine Zusammenfassung wirklich auf den Punkt gebracht ist, kann nur bei hervorragender Kenntnis des Ausgangsmaterials beurteilt werden.
Solange die Zuverlässigkeit des Informationsabrufs auch bei komplexen Abfragen nicht deutlich über 90 Prozent liegt, bleibt ein riesiges Kontextfenster zwar ein beeindruckender technischer Benchmark, aber in der Praxis wahrscheinlich ein Feature ohne großen Wert oder sogar mit dem Risiko, die Informationsqualität zu mindern, wenn es unüberlegt oder zu vertrauensselig eingesetzt wird.

