
OpenAIs GPT-4 Turbo kann 16 Mal mehr Tokens gleichzeitig verarbeiten als das alte GPT-4 in ChatGPT. Allerdings kommt dieses Feature mit einem großen Aber.
GPT-4 Turbo kann bis zu 100.000 Wörter (128.000 Token) oder 300 Seiten eines Standardbuches auf einmal verarbeiten. Das vorherige GPT-4 Modell in ChatGPT schaffte nur 8.000 Token, was etwa 4.000 bis 6.000 Wörtern entspricht.
Theoretisch könnte GPT-4 Turbo also wesentlich größere Gesamtzusammenhänge in Dokumenten aufdecken und Detailfragen zu komplexen Themen beantworten. Erste Tests zeigen jedoch, dass man sich auf diese Fähigkeit nicht verlassen sollte.
Ende Juli bewiesen Forschende der Stanford University, der University of California, Berkeley, und von Samaya AI erstmals, dass große Sprachmodelle Inhalte am Anfang und am Ende eines Dokuments besonders gut abrufen können.
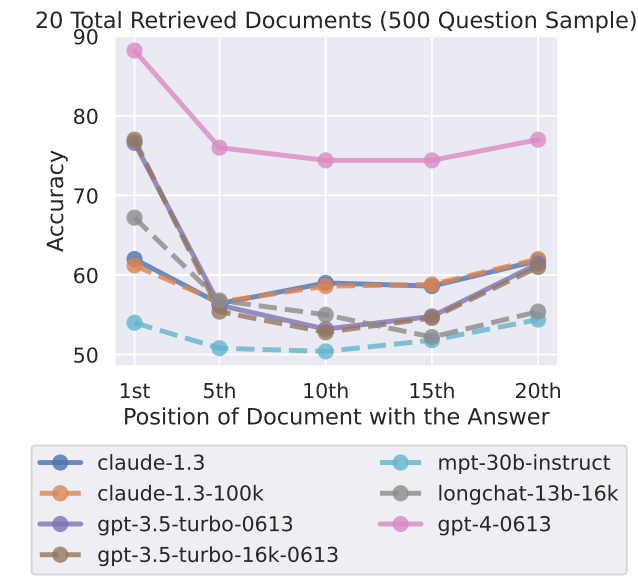
Inhalte in der Mitte werden eher übersehen, ein Effekt, der sich verstärkt, wenn die Modelle sehr viel Input gleichzeitig verarbeiten. Die Forscherinnen und Forscher tauften diesen Effekt "Lost in the Middle".
Auch GPT-4-Turbo übersieht Informationen in der Mitte und am Ende von Dokumenten
Angeregt durch diese Forschungsarbeit haben Greg Kamradt, Shawn Wang und Jerry Liu nun in ersten Tests untersucht, ob dieses Phänomen auch bei GPT-4 Turbo auftritt. Immerhin betonte OpenAI CEO Sam Altman bei der Vorstellung von GPT-4 Turbo sogar die Genauigkeit des neuen Modells in großen Kontexten.
Kamradts Testmethode bestand darin, Aufsätze von Paul Graham in das System zu laden und eine zufällige Aussage ("The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day") an verschiedenen Stellen des Dokuments zu platzieren.
Dann versuchte er, diese Information zu extrahieren, und ließ eine andere GPT-4-Instanz bewerten, wie gut dies funktionierte.
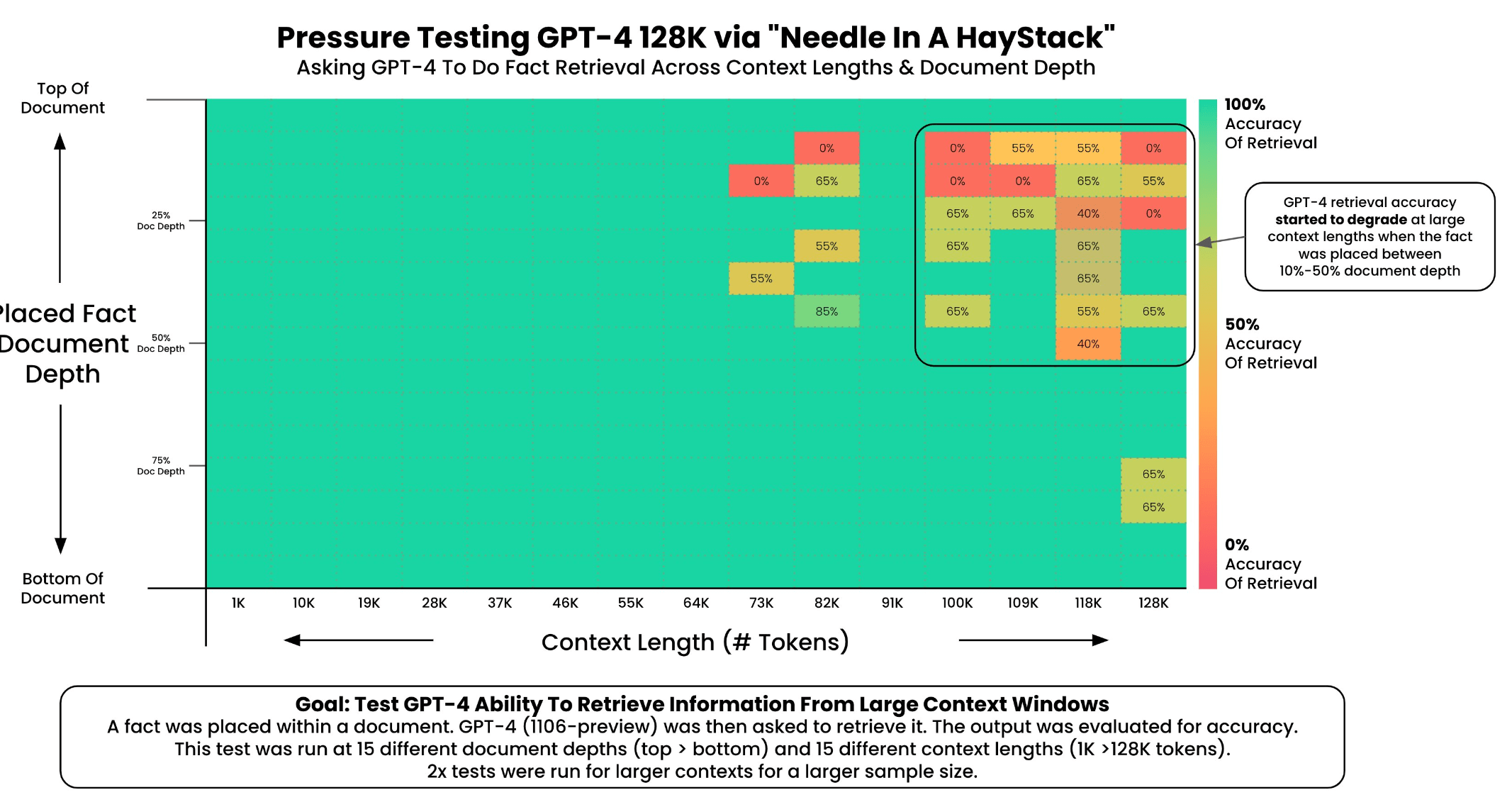
In seiner Analyse stellte Kamradt fest, dass die Auffindbarkeit durch GPT-4 oberhalb von 73.000 Token abnahm und mit der geringen Auffindbarkeit der Aussage korrelierte, die zwischen 7 Prozent und 50 Prozent der Dokumenttiefe platziert war. Befand sich die Aussage jedoch am Anfang des Dokuments, wurde sie unabhängig von der Kontextlänge gefunden.

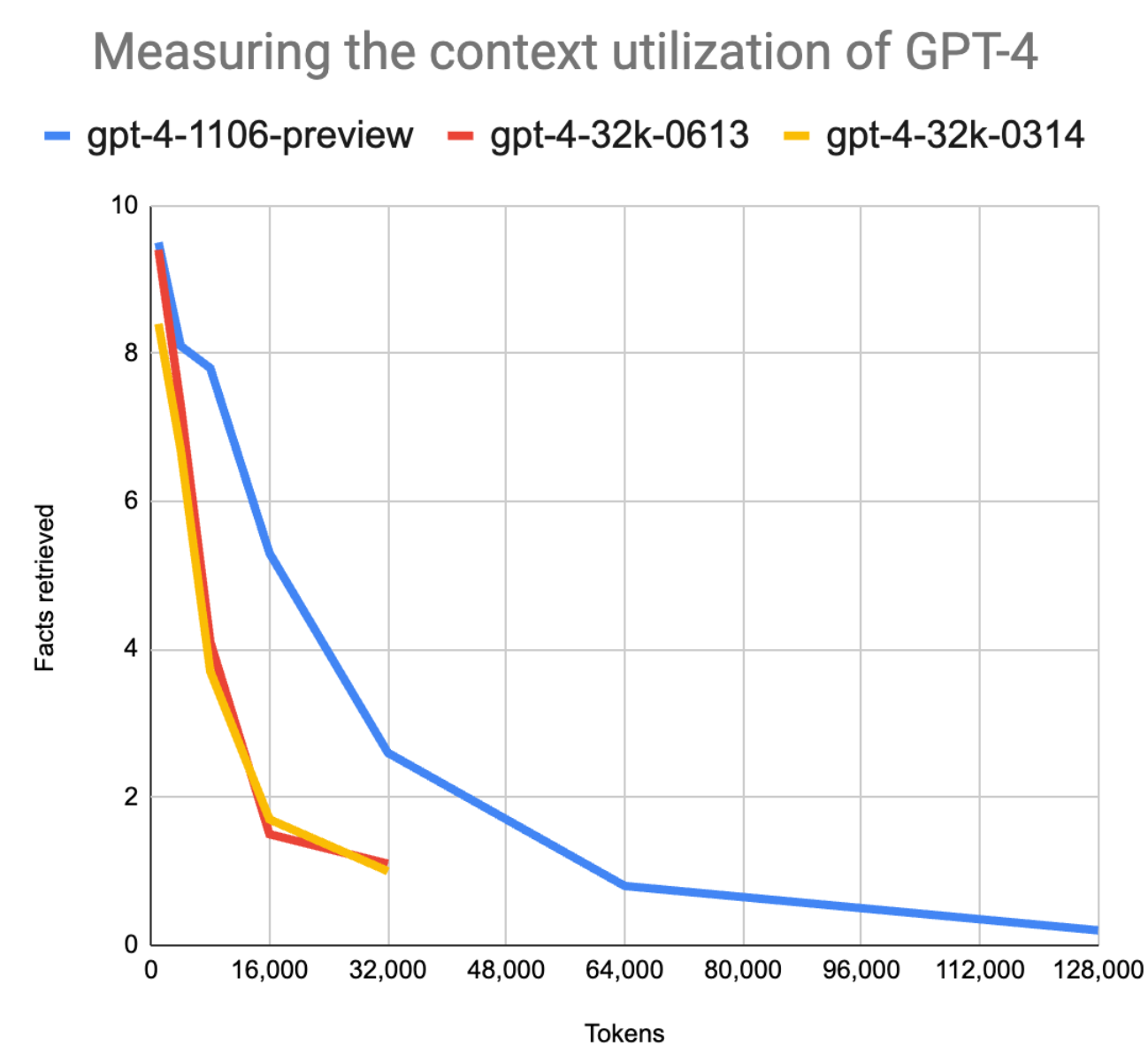
Wangs Test zeigte, dass GPT-4 Turbo bei 16.000 Token zwar 3,5 Mal mehr genaue Informationen abrufen konnte als das bisherige GPT-4. Allerdings zeigte sich auch hier, dass die Zuverlässigkeit der Informationsabfrage am Anfang des Dokuments besonders hoch ist und danach stark abnimmt.

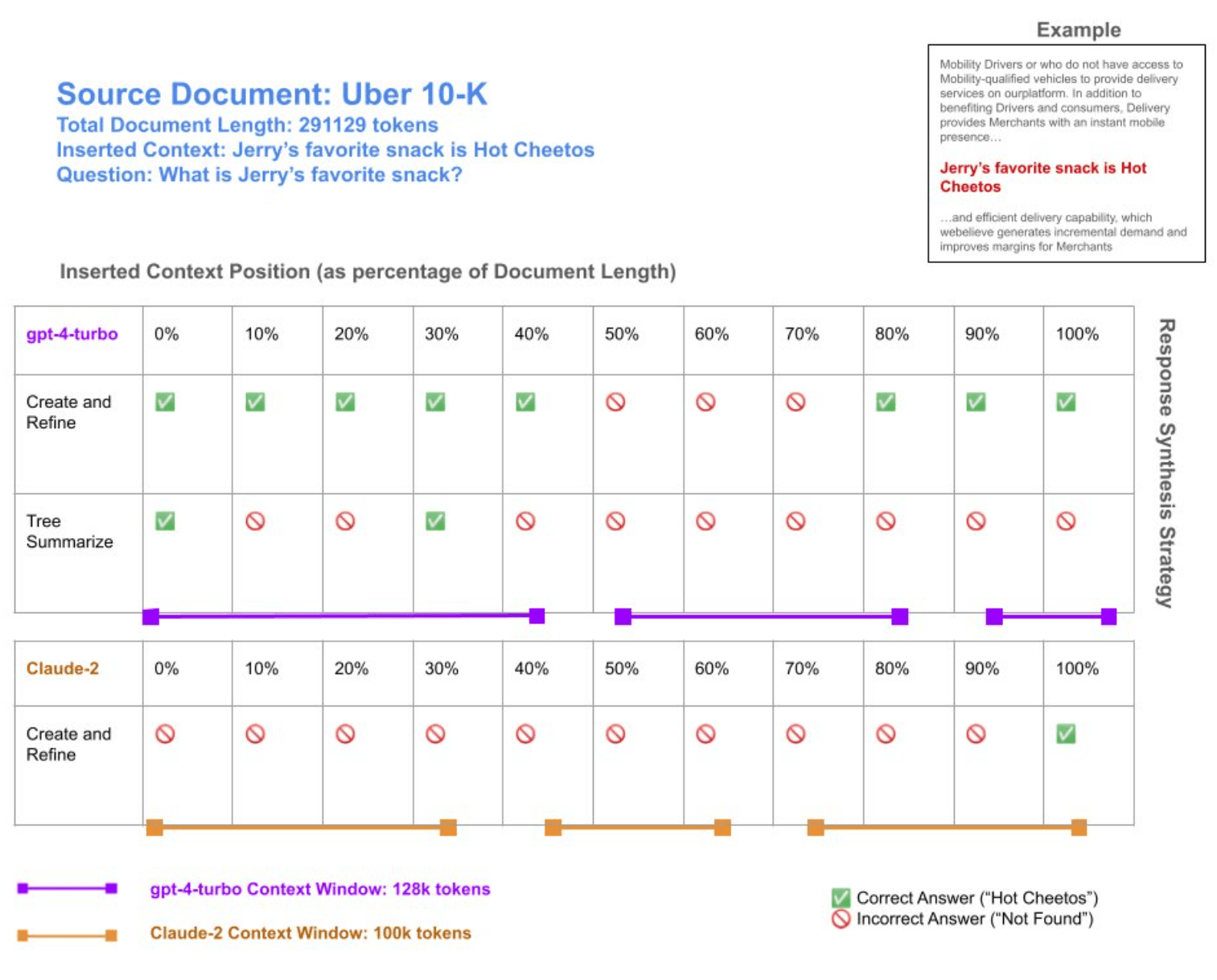
Liu untersuchte GPT-4 Turbo und Claude-2 hinsichtlich der Extraktion von Informationen aus sehr großen Dokumenten (>= 250.000 Token). Auch er kam zu dem Schluss, dass die Zusammenfassung und Analyse großer Dokumente immer noch problematisch ist. GPT-4 Turbo schnitt jedoch mit 128.000 Token signifikant besser ab als Claude-2 mit 100.000 Token.
Präzise Informationsabfrage weiter lieber per Vektordatenbank
Alle drei Tests sind zwar bisher nicht statistisch signifikant. Sie zeigen aber recht deutlich, dass OpenAI das Problem der großen Kontextfenster zwar verbessern, aber bisher nicht lösen konnte.
Die wichtigsten Erkenntnisse für Anwender aus diesen Tests sind, dass Fakten in großen Dokumente nicht garantiert wiedergefunden werden, dass eine Reduzierung des Kontextes die Genauigkeit erhöhen kann und die Position für die Wiederauffindbarkeit wichtig ist.
Der Nutzen eines großen Kontextfensters ist also nicht so offensichtlich, wie es auf den ersten Blick erscheinen mag, und die Unzuverlässigkeit der Informationen in der Mitte kann sich in der Praxis sogar als hinderlich erweisen.
Eingebettete Suchfunktionen oder Vektordatenbanken haben daher trotz großer Kontextfenster weiterhin ihre Daseinsberechtigung, da sie bei der gezielten Suche nach Informationen genauer und preiswerter sind. Die Ausführung von Modellen mit großen Kontextfenstern ist deutlich teurer als die Inferenz von Modellen mit kleinen Kontextfenstern.


