Große Sprachmodelle und das Phänomen der vergessenen Mitte

In einem Punkt scheinen sich Menschen und Maschinen zu ähneln: Sie reagieren besonders gut auf Informationen am Anfang oder Ende eines Inhalts. Informationen in der Mitte gehen eher verloren.
Forschende der Stanford University, der University of California, Berkeley, und von Samaya AI haben bei LLMs einen Effekt entdeckt, der an den vom Menschen bekannten Primacy-Recency-Effekt erinnert. Dieser besagt, dass Menschen sich Inhalte am Anfang und am Ende einer Aussage besonders gut merken. Inhalte in der Mitte werden eher vergessen.
Ein ähnlicher Effekt tritt laut der Studie "Lost in the Middle" auch bei großen Sprachmodellen auf: Haben die Modelle beispielsweise die Aufgabe, eine Information aus einem Dokument zu extrahieren, erzielen sie die beste Leistung, wenn diese Information am Anfang oder am Ende einer Eingabe steht.
Befindet sich die relevante Information jedoch in der Mitte der Eingabe, sinkt die Leistung signifikant. Dieser Leistungsrückgang war besonders ausgeprägt, wenn das Modell eine Frage beantworten musste, für die es Informationen aus mehreren Dokumenten extrahierte - das Äquivalent zu einem Studenten, der relevante Informationen aus mehreren Kapiteln identifizieren muss, um eine Prüfungsfrage zu beantworten.
Je mehr Input das Modell gleichzeitig verarbeiten muss, desto schlechter ist in der Regel seine Leistung. Dies könnte ein Problem in realen Szenarien darstellen, in denen es wichtig ist, große Mengen an Informationen gleichzeitig und gleichwertig zu verarbeiten.
Das Ergebnis deutet auch darauf hin, dass es eine Grenze gibt, wie effektiv große Sprachmodelle zusätzliche Informationen nutzen können, und dass "Mega-Prompts" mit besonders detaillierten Anweisungen wahrscheinlich eher schädlich als nützlich sind.
Zweifel am Nutzen großer Kontextfenster in Sprachmodellen
Das Phänomen der vergessenen Mitte tritt auch bei Modellen auf, die speziell für die Verarbeitung von viel Kontext entwickelt wurden, wie GPT-4 32K oder Claude mit einem Kontextfenster von 100K Token.
Die Forscherinnen und Forscher testeten sieben offene und geschlossene Sprachmodelle, darunter das neue GPT-3.5 16K und Claude 1.3 mit 100K. Alle Modelle zeigten je nach Test eine mehr oder weniger stark ausgeprägte U-Kurve mit einer besseren Leistung bei Aufgaben, deren Lösung sich am Anfang und am Ende des Textes befindet.
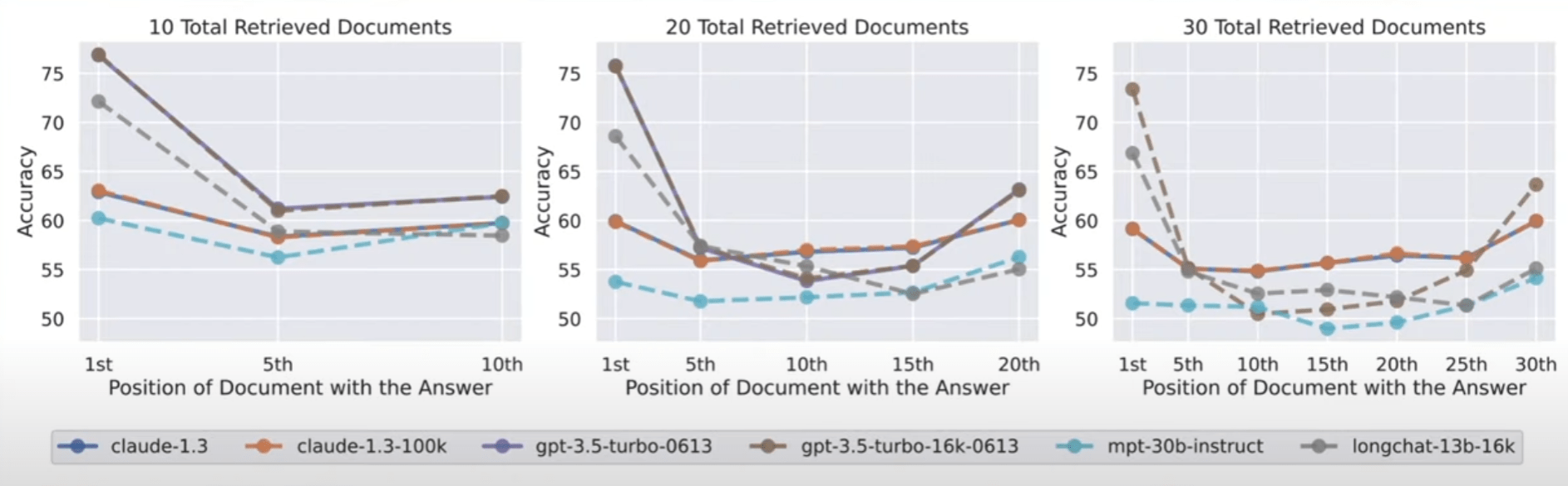
Dies wirft die Frage nach dem Nutzen von Modellen mit einem großen Kontextfenster auf, wenn bessere Ergebnisse erzielt werden können, wenn der Kontext schrittweise in kleineren Einheiten verarbeitet wird. Auch das derzeit leistungsfähigste Modell GPT-4 zeigt den Mitte-Effekt, wenn auch auf einem insgesamt höheren Niveau.
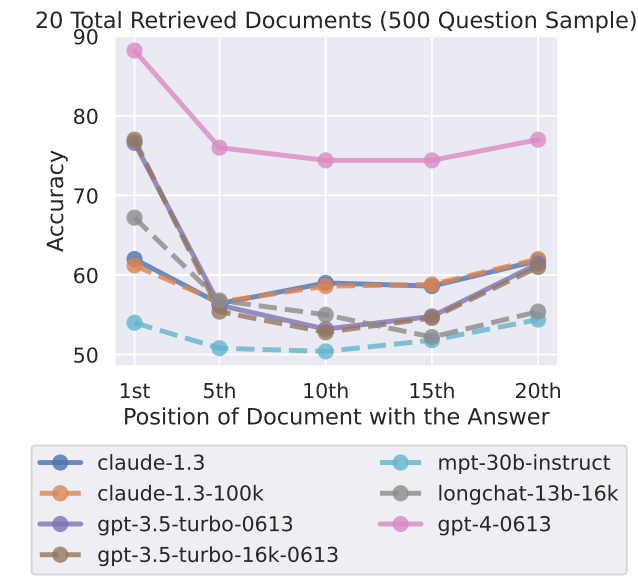
Das Forschungsteam räumt ein, dass man noch nicht genau versteht, wie Modelle Sprache verarbeiten. Dieses Verständnis muss durch neue Evaluierungsmethoden verbessert werden, und möglicherweise sind auch neue Architekturen erforderlich.
Außerdem muss untersucht werden, wie sich das Prompt-Design auf die Modellleistung auswirkt: Indem KI-Systeme durch Prompts besser mit der spezifischen Aufgabe vertraut gemacht werden, könnte ihre Fähigkeit, relevante Informationen zu extrahieren, verbessert werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.