Deepseeks OCR-Modell könnte das KI-Gedächtnis deutlich ausbauen
Das chinesische KI-Unternehmen Deepseek hat ein System entwickelt, das Textdokumente in Bildform als hochkomprimierten Input verarbeitet. Die Methode soll das Problem zu langer Kontexte in Sprachmodellen lösen.
Das Grundprinzip basiert auf der Annahme, dass ein Bild mit Text weniger Rechenkapazität benötigt als die digitale Verarbeitung des gleichen Textes. Laut dem technischen Paper der Forschenden kann Deepseek-OCR Texte um das bis zu Zehnfache komprimieren und dabei 97 Prozent der ursprünglichen Informationen korrekt wiedergeben.
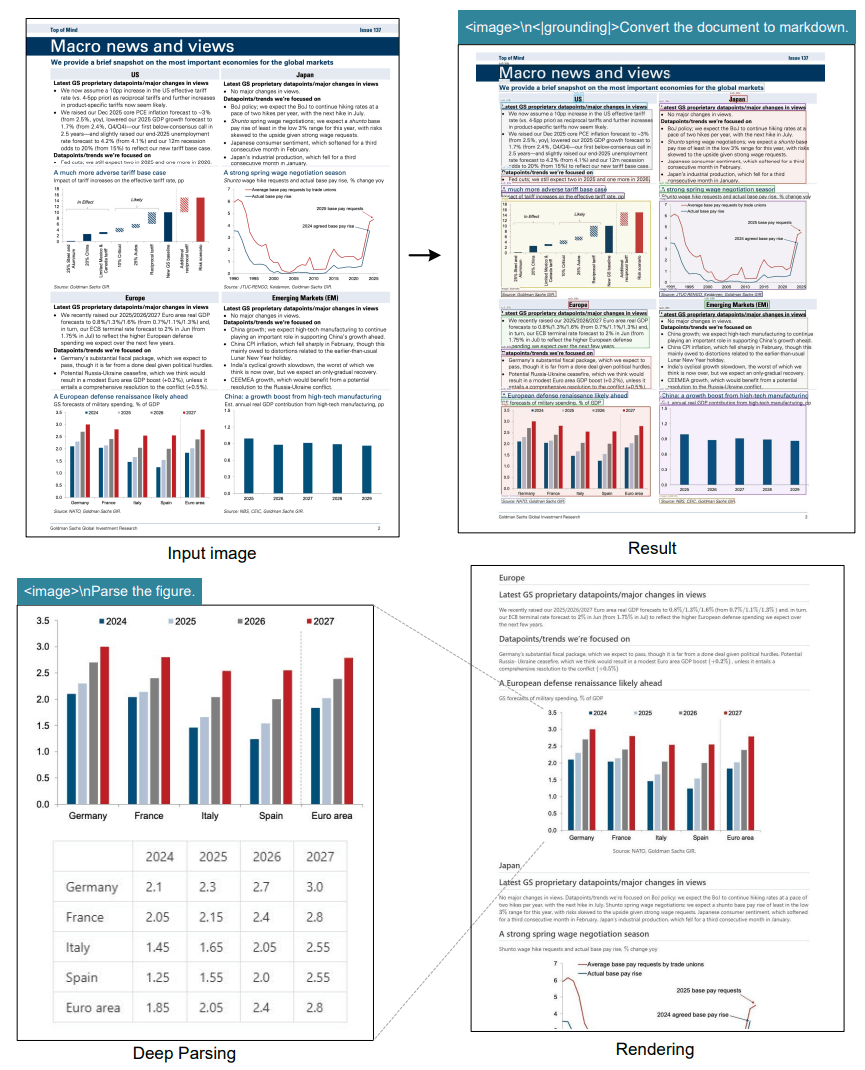
DeepEncoder kombiniert bewährte KI-Bildmodelle
Das System besteht aus zwei Hauptkomponenten: einem Bildverarbeitungsteil namens DeepEncoder und einem Textgenerator auf Basis von Deepseek3B-MoE mit 570 Millionen aktivierten Parametern. Der DeepEncoder mit 380 Millionen Parametern analysiert das eingegebene Bild und wandelt es in eine komprimierte Darstellung um.
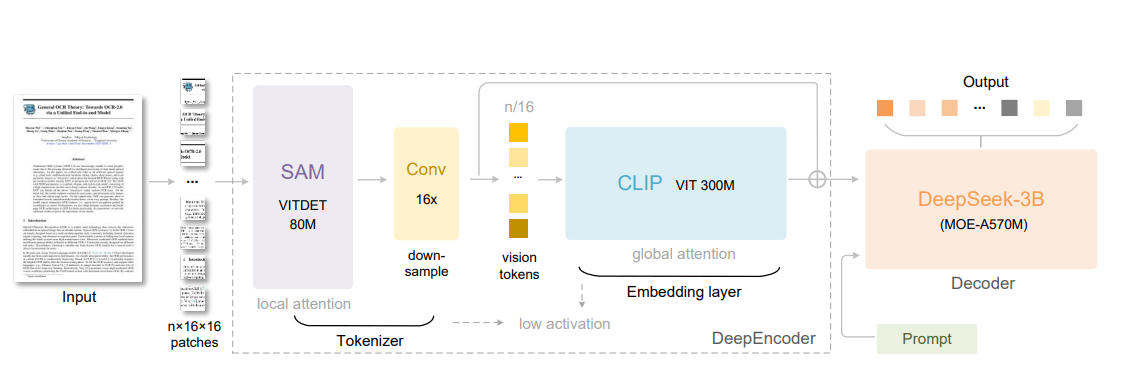
Die Innovation liegt in der Architektur des DeepEncoders. Er kombiniert ein 80-Millionen-Parameter SAM-Modell mit einem 300-Millionen-Parameter CLIP-Modell. SAM (Segment Anything Model) ist Metas KI-System zur präzisen Bildsegmentierung, das einzelne Objekte in Bildern erkennen kann. CLIP stammt von OpenAI und kann Bilder und Text miteinander verknüpfen.
Zwischen beiden Modellen sitzt ein 16-fach-Kompressor, der die Anzahl der Bildtoken drastisch reduziert. Bei einem 1.024 x 1.024 Pixel-Bild entstehen zunächst 4.096 Bildtoken. Das SAM-Modell verarbeitet diese mit geringem Speicherverbrauch, bevor der Kompressor sie auf 256 Token reduziert. Erst diese komprimierten Token gelangen zum rechenintensiven CLIP-Teil.
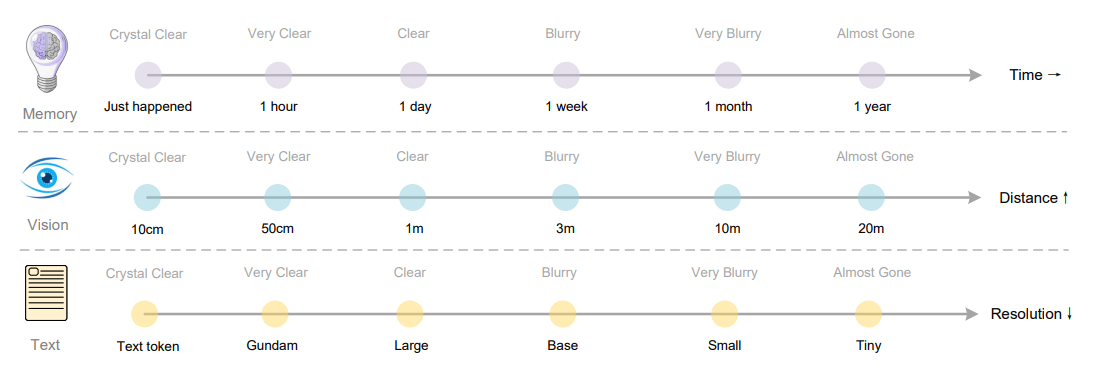
Deepseek-OCR kann mit verschiedenen Bildauflösungen arbeiten. Bei niedrigen Auflösungen benötigt es 64 sogenannte "Vision-Token" um ein Bild zu verarbeiten. Bei höheren Auflösungen sind es bis zu 400 Token. Herkömmliche Systeme benötigen oft mehrere Tausend Token für die gleiche Aufgabe.
System übertrifft Konkurrenz mit einem Zehntel der Token
In Tests auf dem Benchmark OmniDocBench erreichte Deepseek-OCR mit 100 Vision-Token bessere Ergebnisse als GOT-OCR 2.0, das 256 Token verwendet. Mit weniger als 800 Token übertraf es MinerU 2.0, das mehr als 6000 Token pro Seite benötigt.
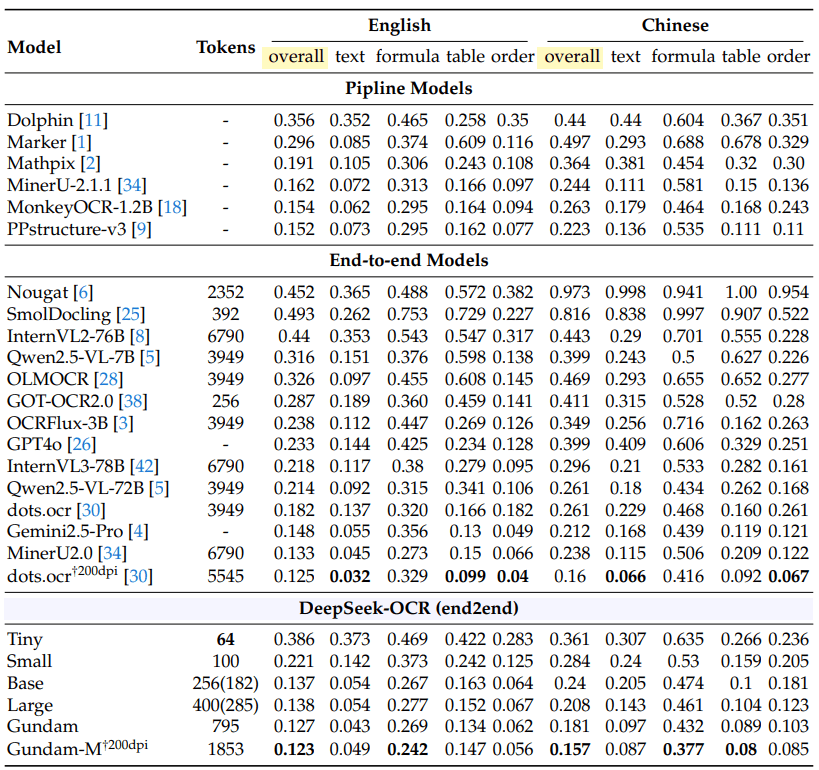
Die Effizienz variiert je nach Dokumenttyp. Einfache Präsentationen können mit 64 Token verarbeitet werden, während Bücher und Berichte etwa 100 Token benötigen. Komplexe Zeitungen erfordern den aufwendigeren "Gundam-Modus" mit bis zu 800 Token.

Das System kann verschiedene Arten von Dokumenten verarbeiten. Dazu gehören einfache Textseiten, Diagramme, chemische Formeln und geometrische Figuren. Es unterstützt etwa 100 Sprachen und kann sowohl die ursprüngliche Formatierung beibehalten als auch reinen Text ausgeben. Zusätzlich verfügt es nach wie vor über seine generellen Fähigkeiten zur Bildbeschreibung.
Für das Training verwendeten die Forschenden 30 Millionen PDF-Seiten in etwa 100 Sprachen, wobei 25 Millionen auf Chinesisch und Englisch entfielen. Zusätzlich flossen zehn Millionen künstlich generierte Diagramme, fünf Millionen chemische Formeln und eine Million geometrische Figuren in das Training ein.
33 Millionen Seiten täglich für KI-Training
In der praktischen Anwendung kann Deepseek-OCR laut den Wissenschaftler:innen über 200.000 Seiten pro Tag auf einer einzelnen Nvidia-A100-GPU verarbeiten. Mit 20 Servern, die jeweils acht solcher Grafikkarten enthalten, steigt die Kapazität auf 33 Millionen Seiten täglich.
Diese Kapazität macht das System für die Erstellung von Trainingsdaten für andere KI-Modelle interessant. Moderne Sprachmodelle benötigen große Mengen an Textdaten für ihr Training, und Deepseek-OCR könnte diese Daten aus Dokumenten extrahieren. Der Code und Modellgewichte sind öffentlich verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.