Deepseeks R1-Modell nach Update wieder gleichauf mit OpenAIs und Googles Top-Modellen

Mit einem Update hebt Deepseek sein R1-Modell auf ein neues Leistungsniveau. Das chinesische KI-Labor rückt damit erneut in die Spitzengruppe der weltweit führenden KI-Modelle auf – und das mit offenen Gewichten.
Deepseek hat sein R1-Modell mit einem Post-Training-Update unter dem Namen Deepseek-R1-0528 veröffentlicht. Die Architektur bleibt unverändert, doch durch algorithmische Optimierungen und den Einsatz zusätzlicher Rechenressourcen konnte die Leistungsfähigkeit deutlich gesteigert werden.
Insbesondere Reasoning-Aufgaben profitieren laut Deepseek von der überarbeiteten Version, die "tiefere Denkprozesse" im Modell ermöglichen soll. In der AIME-2025-Mathematikbewertung stieg die Genauigkeit von 70 auf 87,5 Prozent. Die durchschnittliche Tokenanzahl pro Frage erhöhte sich dabei von 12.000 auf 23.000 – ein Hinweis auf intensivere Verarbeitungsvorgänge bei gleichbleibender Architektur.
Benchmark-Zuwächse in Mathematik, Code und Logik
In seinen eigenen Benchmarks verzeichnet Deepseek breite Leistungssteigerungen. In Mathematik stieg der AIME-2024-Wert von 79,8 auf 91,4 Prozent, HMMT 2025 von 41,7 auf 79,4 Prozent und CNMO 2024 von 78,8 auf 86,9 Prozent.
Bei Programmierbenchmarks legte das Modell unter anderem bei LiveCodeBench (63,5 auf 73,3 Prozent), Aider-Polyglot (53,3 auf 71,6 Prozent) und SWE Verified (49,2 auf 57,6 Prozent) zu. Auch der Codeforces-Rating kletterte von 1530 auf 1930 Punkte.
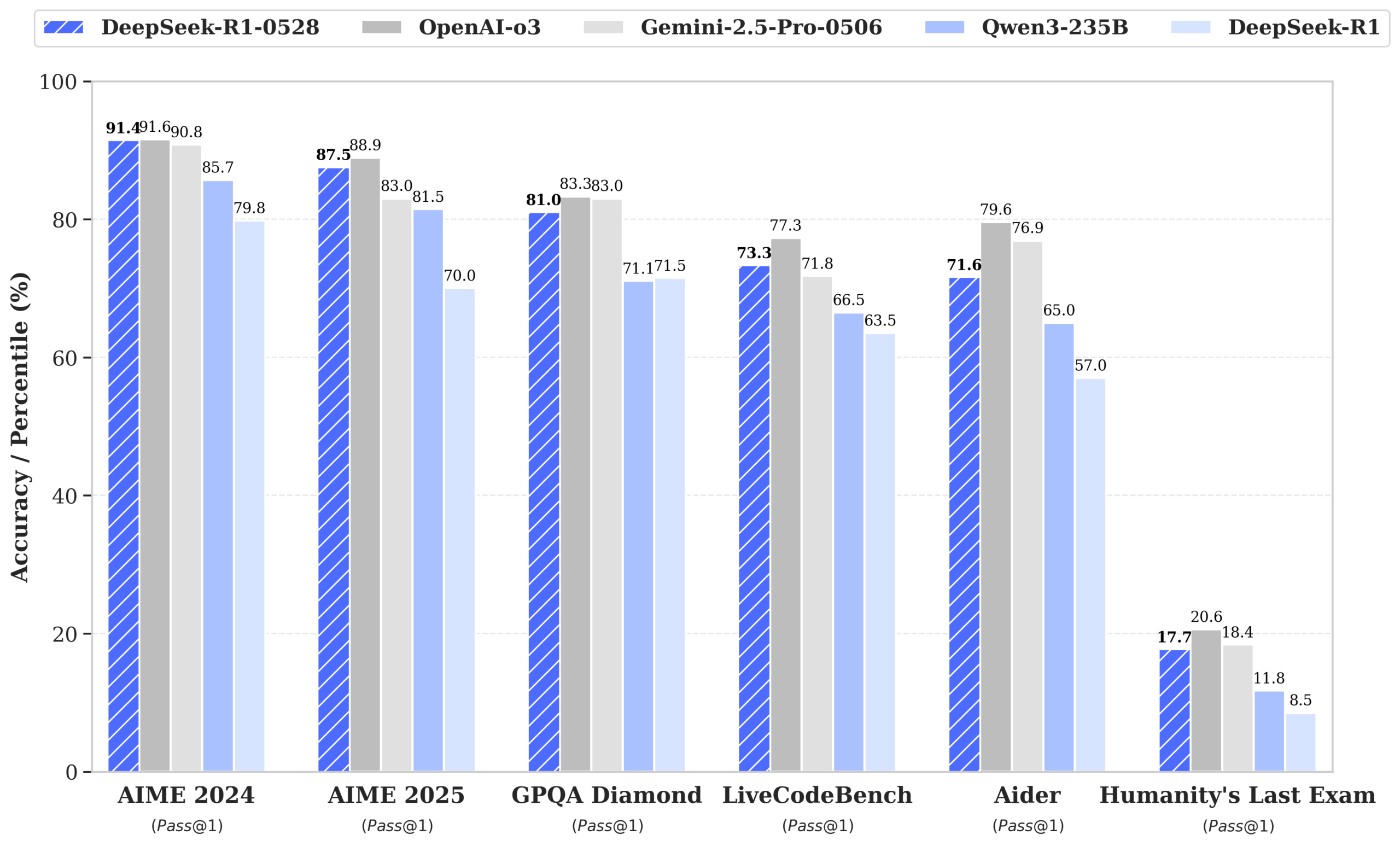
Bei allgemeinen Wissens- und Logiktests meldet Deepseek ebenfalls Zuwächse: GPQA-Diamond stieg von 71,5 auf 81,0 Prozent, Humanity’s Last Exam von 8,5 auf 17,7 Prozent, MMLU-Pro von 84,0 auf 85,0 Prozent und MMLU-Redux von 92,9 auf 93,4 Prozent. Ein Rückgang zeigt sich lediglich bei SimpleQA (30,1 auf 27,8 Prozent). Die Tests wurden laut Deepseek mit standardisierten Parametern und einem maximalen Kontext von 64.000 Tokens durchgeführt.
Artificial Analysis bestätigt Leistungssteigerung
Die unabhängige Bewertungsplattform Artificial Analysis stuft Deepseek-R1-0528 im eigenen Intelligence Index mit 68 Punkten ein – ein Anstieg gegenüber der Januar-Version mit 60 Punkten. Das entspricht einem Leistungssprung vergleichbar mit dem zwischen OpenAI o1 (62) und o3 (70). Damit liegt Deepseek auf dem gleichen Niveau wie Googles Gemini 2.5 Pro.
Artificial Analysis sieht das Modell vor xAIs Grok 3 mini (high), Metas Llama 4 Maverick, Nvidias Nemotron Ultra und Alibabas Qwen3 253. In der Code-Kategorie erreicht Deepseek-R1-0528 ein Niveau knapp unterhalb von OpenAI o4-mini (high) und o3.
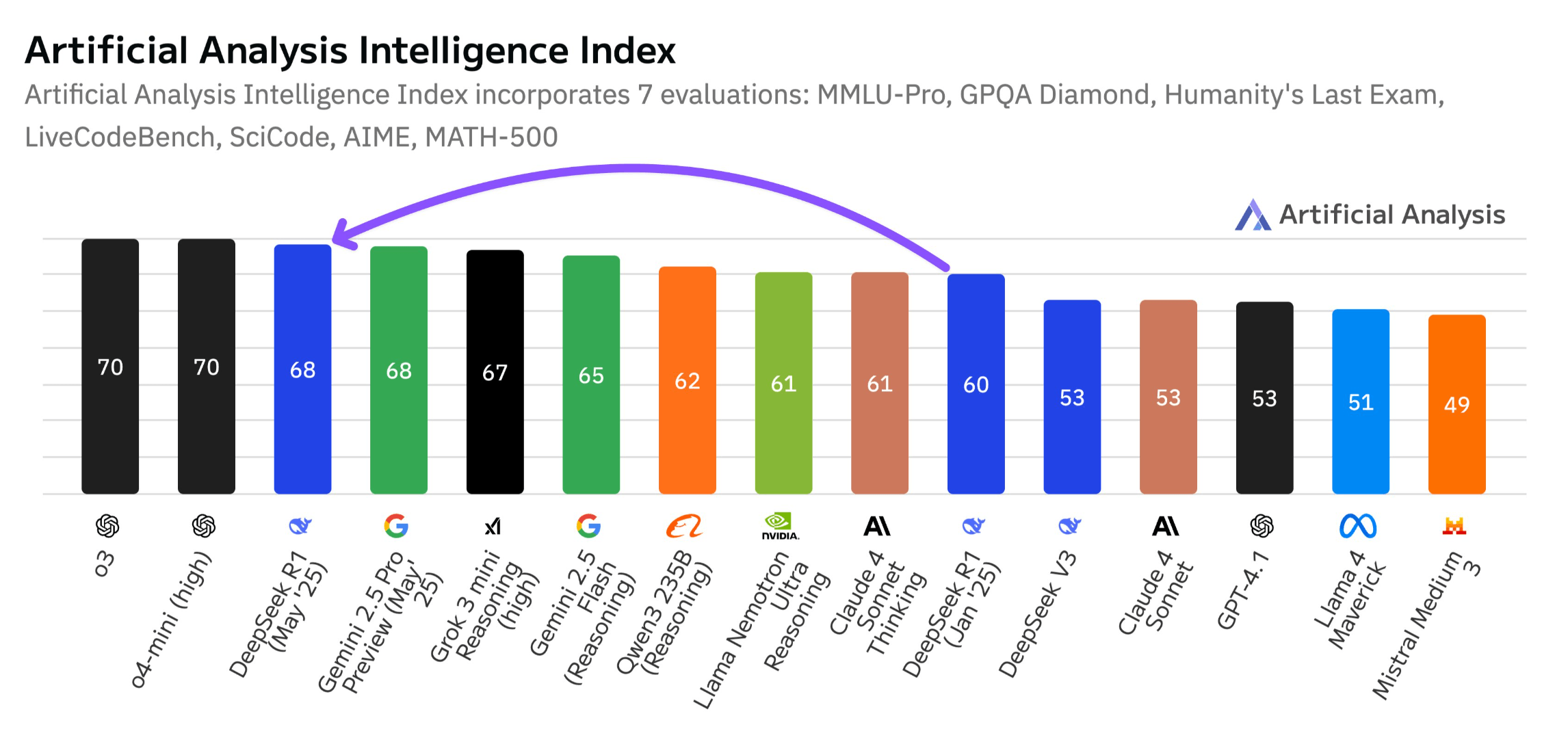
Als Ursache für die Leistungssteigerung nennt Artificial Analysis vorrangig das verstärkte Post-Training mit Reinforcement Learning. Der Tokenverbrauch in der Evaluation stieg um 40 Prozent – von 71 auf 99 Millionen Tokens. Das Modell generiert also längere und tiefere Antworten.
Artificial Analysis sieht offene Modelle wie Deepseek-R1 wieder näher an proprietäre Lösungen der US-Anbieter heranrücken. Das Modell bleibe führend unter den Open-Weight-Modellen – mit einem Leistungssprung ohne Architekturänderung.
Kompaktmodell mit starker Mathematikleistung
Parallel zum R1-Update veröffentlicht Deepseek ein distilliertes Modell: Deepseek-R1-0528-Qwen3-8B basiert auf Alibabas Qwen3 8B und wurde mit der Chain-of-Thought-Methode aus R1-0528 nachtrainiert.
Auf AIME 2024 erreicht es laut Deepseek 86 Prozent Genauigkeit – zehn Prozentpunkte mehr als das ursprüngliche Qwen3 8B – und liegt damit auf Augenhöhe mit dem deutlich größeren Qwen3-235B-thinking, soll aber schon auf einer Nvidia H100 laufen.
Deepseek sieht darin ein Beispiel für die industrielle und akademische Relevanz reasoning-orientierter Kompaktmodelle, die mit geringeren Ressourcen konkurrenzfähige Resultate erzielen können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.