
Hugging Face bietet den neuen KI-Service "Training Cluster as a Service" an, mit dem Unternehmen ohne eigene Rechenfarm KI-Modelle trainieren können.
Das KI-Unternehmen Hugging Face startet "Training Cluster as a Service": Mit dem neuen Service können Nutzer:innen auf leistungsstarke GPU-Cluster zugreifen, um ihre KI-Modelle schneller und einfacher zu trainieren.
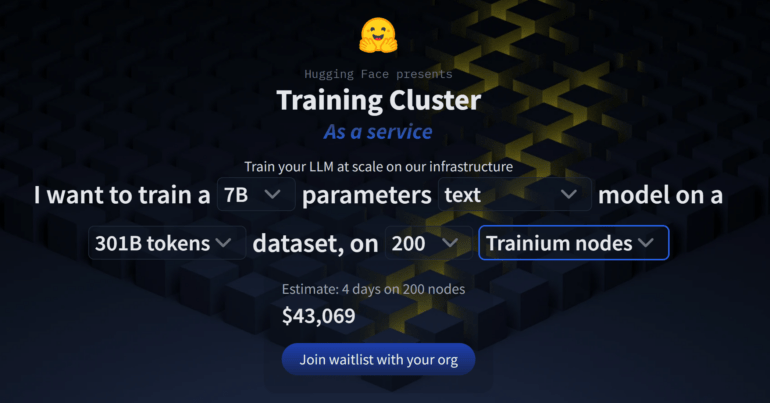
Besonders interessant ist der dazugehörige Preisrechner: Hier können Nutzer:innen ihr gewünschtes Modell anhand der Anzahl der Parameter, der Fähigkeiten, der Anzahl der Trainingsdaten und der gewünschten Trainingsgeschwindigkeit konfigurieren.
Das günstigste Textmodell mit 7 Milliarden Parametern kostet geschätzte 43.069 US-Dollar und würde etwa vier Tage Trainingszeit benötigen.
Das teuerste multimodale Modell (Text und Bild) würde 18.461.354 US-Dollar kosten: 70 Milliarden Parameter, 7 Billionen Token Trainingsdaten und 184 Tage Trainingszeit auf 1000 Nvidia H100 GPUs.
Ein solches Modell zu trainieren wäre dann sinnvoll, wenn man aus Sicherheitsgründen völlig autonom agieren will oder wenn man sehr spezifische Anwendungsszenarien hat, für die man das Modell optimieren kann.
Allerdings bieten auch hier die großen KI-Unternehmen wie Google oder OpenAI eigene Dienste für das Feintuning ihrer Modelle an, die beim Preis-Leistungs-Verhältnis vermutlich besser aufgestellt sind.
KI-Training ist teuer
Da die Leistungsfähigkeit eines Modells auch und vor allem von der Datenqualität abhängt, ist es schwierig, eine generelle Aussage über die Leistungsfähigkeit der selbsttrainierten HF-Modelle zu treffen.
Man kann aber davon ausgehen, dass selbst das leistungsfähigste multimodale Modell mit 70 Milliarden Parametern, das derzeit über den HF-Dienst trainiert werden kann, keine Chance gegen GPT-4 oder Googles Gemini hätte, wenn es darum geht, möglichst viele Aufgaben in möglichst hoher Qualität zu erledigen. Allein GPT-4 soll rund 1,8 Billionen Parameter haben, also 25-Mal größer sein, und kostet laut Schätzungen zwischen rund 70 und mehr als 100 Millionen US-Dollar.

Das zeigt, dass KI-Spitzenmodelle allein aus finanzieller Sicht noch einen starken Burggraben haben. Und dass deutsche und europäische KI-Start-ups vermutlich unterfinanziert sind, auch wenn es perspektivisch möglich ist, dass Fortschritte bei Chips, effizientere Architekturen und weniger benötigte, weil hochwertigere Trainingsdaten die Preise fürs Training senken.





