
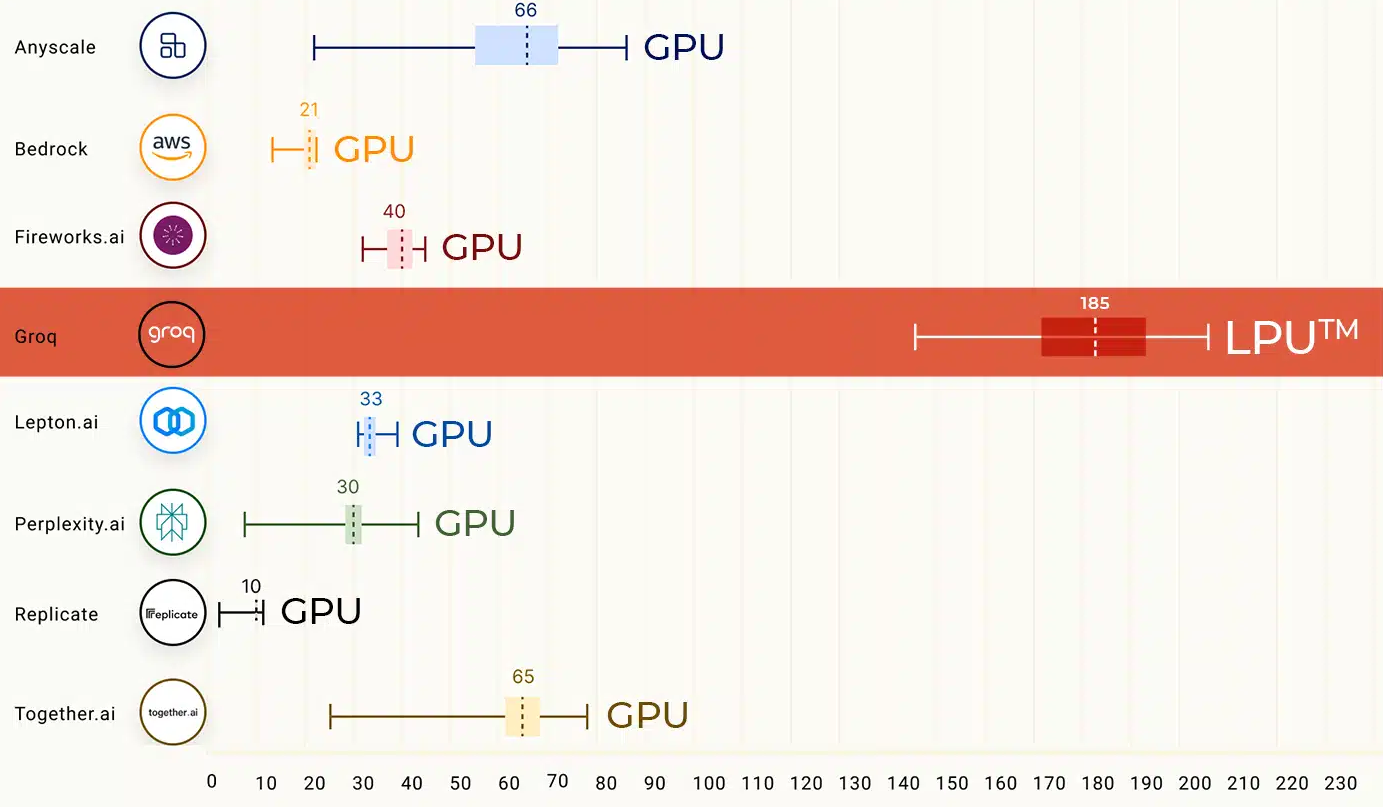
Sprachmodelle können im Vergleich zu Menschen extrem schnell Texte generieren. Doch manchen, wie dem Start-up Groq, ist das nicht schnell genug.
Um noch höhere Geschwindigkeiten bei der KI-Ausführung zu erreichen, hat Groq eine spezielle Hardware entwickelt: LPUs (Language Processing Unit).
Diese LPUs wurden speziell für die Ausführung von Sprachmodellen entwickelt und bieten eine Geschwindigkeit von bis zu 500 Token pro Sekunde. Zum Vergleich: Die relativ schnellen LLMs Gemini Pro und GPT-3.5 schaffen je nach Last, Prompt, Kontext und Ausspielung zwischen 30 und 50 Token pro Sekunde.
Der erste "GroqChip" der LPU-Systemkategorie verwendet eine "Tensor-Streaming-Architektur", die laut Groq auf Leistung, Effizienz, Geschwindigkeit und Genauigkeit ausgelegt ist.
Nach Angaben des Start-ups bietet der Chip im Gegensatz zu herkömmlichen Grafikchips (GPUs) eine vereinfachte Architektur, die eine konstante Latenz und einen konstanten Durchsatz ermöglichen. Insbesondere für Echtzeit-KI-Anwendungen wie Games kann das ein Vorteil sein.

Außerdem sind LPUs laut Groq energieeffizienter. Sie reduzieren den Aufwand für die Verwaltung mehrerer Threads und vermeiden die Unterauslastung von Kernen, wodurch mehr Berechnungen pro Watt durchgeführt werden können.
Das Chip-Design von Groq ermöglicht die Verbindung mehrerer TSPs ohne die traditionellen Engpässe, die bei GPU-Clustern auftreten. Laut Groq macht dies das System skalierbar und vereinfacht die Hardwareanforderungen für große KI-Modelle.
Die Systeme von Groq unterstützen gängige Machine-Learning-Frameworks, was die Integration in bestehende KI-Projekte erleichtern soll. Groq verkauft die eigene Hardware und bietet auch eine Cloud-API mit Open-Source-Modellen wie Mixtral an. Ihr könnt die Geschwindigkeit von Groq hier mit Mixtral und Llama testen.

LPUs könnten die Bereitstellung von KI-Anwendungen verbessern und in diesem Bereich eine Alternative zu den derzeit stark nachgefragten A100- und H100-Chips von Nvidia darstellen.
Das gilt allerdings nur für die Inferenz, also die Ausführung von KI-Modellen. Für das Training der Modelle benötigen Unternehmen derzeit weiter die bisher gängige Hardware von Nvidia oder ähnliche Chips.
Groq wurde 2016 von Jonathan Ross gegründet, der bei Google an den TPU-Chips mitarbeitete.


