Ein einzelner Prompt soll langweilige KI-Antworten verhindern

Sprachmodelle neigen nach dem Training zu immer ähnlicheren Antworten. Das "Verbalized Sampling" soll gegen die zunehmende Stereotypisierung von Sprachmodellen nach dem Training helfen.
Forschende verschiedener US-Universitäten führen das Problem auf menschliche Bewertungsmuster zurück. Ihre Analyse zeigt, dass Menschen bei der Bewertung von KI-Antworten systematisch vertraute und typische Texte bevorzugen. Diese Tendenz überträgt sich auf die Modelle und führt zu weniger vielfältigen Ausgaben.
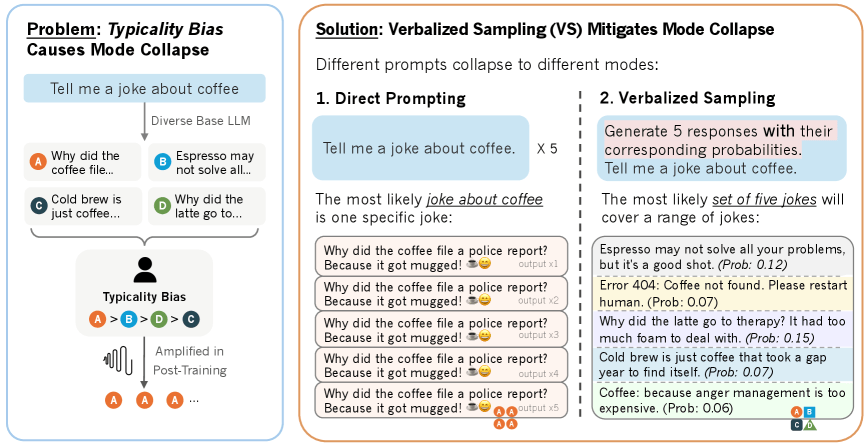
Die Wissenschaftler untersuchten diese Hypothese am HELPSTEER-Datensatz mit 6.874 Antwortpaaren. Menschliche Bewerter:innen bevorzugten durchweg Antworten, die von Basismodellen als wahrscheinlicher eingestuft wurden. Dieser Effekt zeigte sich unabhängig von der faktischen Korrektheit der Antworten und bestätigte sich über mehrere Datensätze hinweg.
Einfache Prompt-Änderung mit großer Wirkung
Der Lösungsansatz besteht darin, Sprachmodelle nicht nach einer einzelnen Antwort zu fragen, sondern nach mehreren Antworten mit entsprechenden Wahrscheinlichkeiten. Ein typischer Prompt sieht folgendermaßen aus:
<instruction>
Generate 5 responses to the user query, each within a separate <response> tag. Each <response> must include a <text> and a numeric <probability>.
Randomly sample the responses from the full distribution.
</instruction>
Write a 100-word story about a bear.
Das Team entwickelte drei Varianten der Methode. Die Standardversion fragt direkt nach mehreren Antworten mit Wahrscheinlichkeiten. Eine erweiterte Version nutzt schrittweises Reasoning vor der Antwortgenerierung. Die dritte Variante arbeitet über mehrere Gesprächsrunden hinweg. Alle Varianten funktionieren ohne zusätzliches Training der Modelle und benötigen keinen Zugang zu den internen Wahrscheinlichkeiten.
Tests zeigen deutliche Verbesserungen
Bei kreativen Schreibaufgaben steigerte Verbalized Sampling die Vielfalt um das 1,6- bis 2,1-fache. Direkte Prompts für Witze über Autos führten in allen fünf Versuchen zur exakt gleichen Antwort ("Why did the car get a flat tire? Because it ran over a fork in the road!"), während die neue Methode fünf völlig unterschiedliche Witze generierte (etwa "What kind of car does a Jedi drive? A Toy-Yoda!").
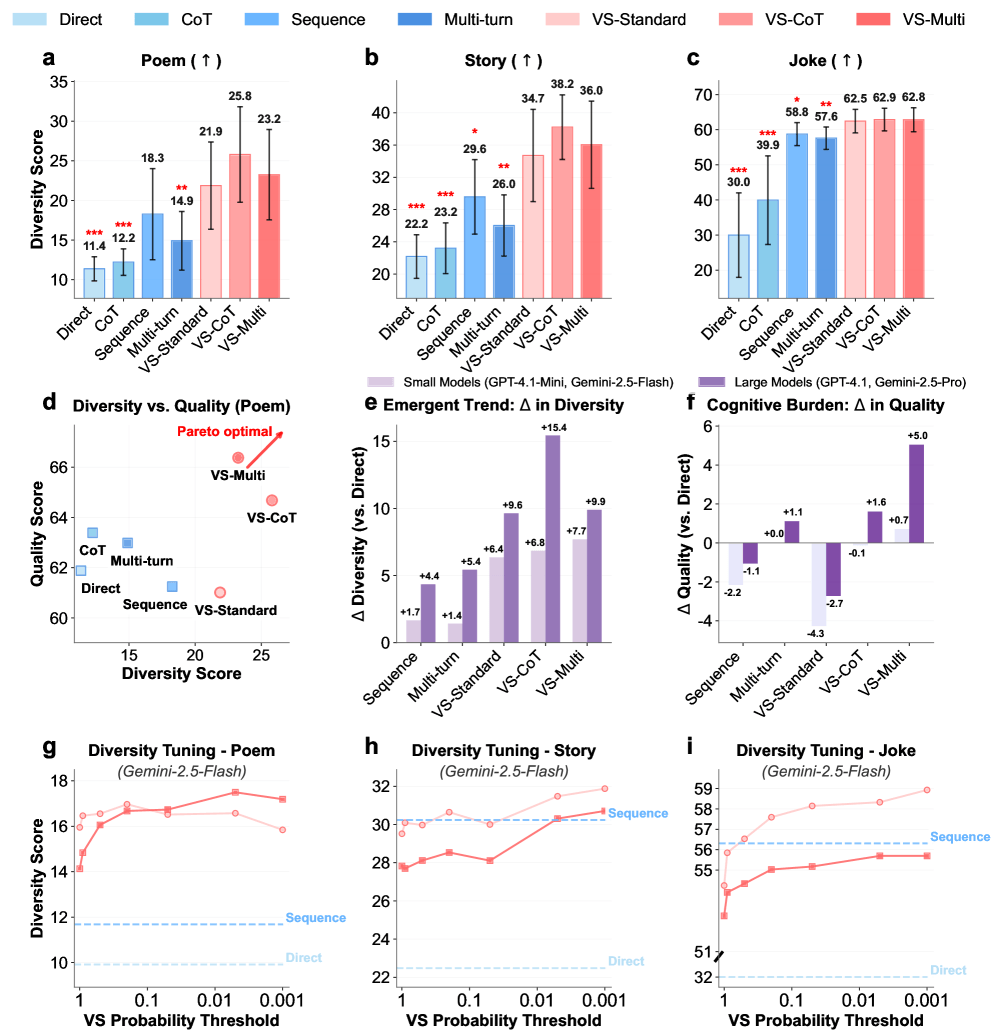
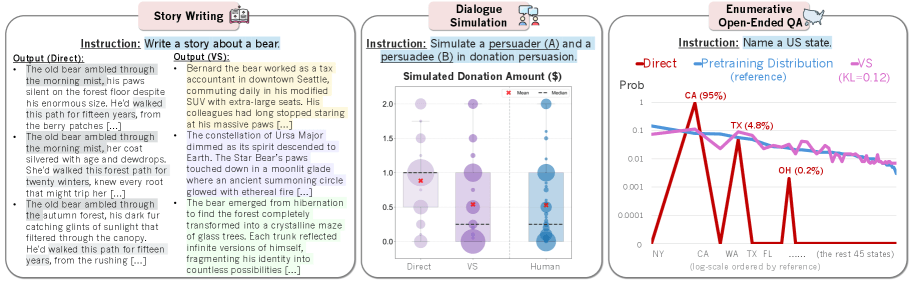
In Dialogsimulationen zeigten die Modelle menschenähnlichere Verhaltensweisen wie Widerstand gegen Überzeugungsversuche und realistische Meinungsänderungen. Bei der Simulation von Spendenbeträgen stimmten die Ergebnisse deutlich besser mit echtem menschlichen Verhalten überein.
Bei offenen Fragen wie "Name a US state" stimmte die Antwortverteilung fast perfekt mit den ursprünglichen Trainingsdaten überein. Standard-Prompts konzentrierten sich hingegen auf wenige häufige Antworten wie Kalifornien und Texas.
Modelle, die mit vielfältigeren synthetischen Mathematikaufgaben trainiert wurden, erreichten bessere Leistungen. Die durchschnittliche Genauigkeit stieg von 32,8 auf 37,5 Prozent.
Größere Modelle profitieren überproportional von der Methode. Die Verbesserungen waren bei leistungsfähigeren Modellen 1,5 bis 2 Mal höher als bei kleineren Versionen.
Die Wissenschaftler:innen testeten die Kombination von Verbalized Sampling mit verschiedenen Generierungsparametern wie der Temperatureinstellung. Dabei zeigte sich, dass die Methode unabhängig von diesen Parametern funktioniert und sich zugleich mit ihnen zur weiteren Leistungssteigerung kombinieren lässt.
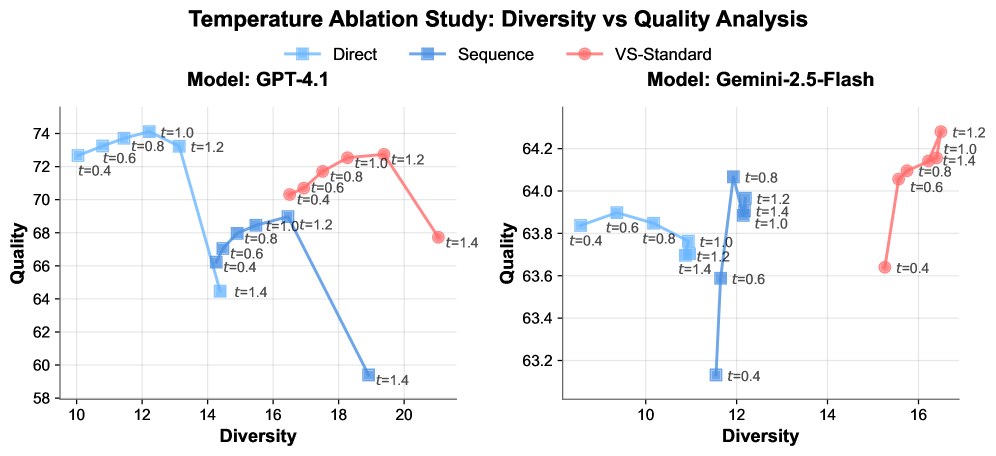
Verbalized Sampling erzielte bei allen getesteten Temperatureinstellungen eine bessere Balance zwischen Qualität und Vielfalt als Standard-Prompts.
Auch kreativere Bildbeschreibungen
Die Methode zeigt außerdem Potenzial für die Bildgenerierung. Die Forschenden testeten Verbalized Sampling zur Erstellung von Bildbeschreibungen, die anschließend in Bildgeneratoren verwendet wurden. Für das Thema "Astronaut on a Horse" erzeugten Standard-Prompts durchweg fotorealistische Wüstenszenen mit ähnlicher Bildkomposition. Verbalized Sampling generierte hingegen deutlich vielfältigere Beschreibungen.

Tests mit über 350 problematischen Prompts bestätigten, dass die Sicherheit nicht beeinträchtigt wird. Die Ablehnungsraten blieben über 97 Prozent. Auch die Faktentreue blieb erhalten.
Die Forschenden haben Code und Anleitungen zur Methode veröffentlicht und sehen Anwendungsmöglichkeiten in Bereichen wie kreativem Schreiben, sozialer Simulation und Ideengenerierung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.