Eine neue Methode ermöglicht das Finetuning großer Sprachmodelle auf einer einzigen GPU. Das Team trainiert damit Guanaco, ein Chatbot, der ChatGPT-Niveau erreicht.
Forschende der University of Washington stellen mit QLoRA (Quantized Low Rank Adapters) eine Methode vor, mit der große Sprachmodelle feinabgestimmt werden können. Zusammen mit QLoRA veröffentlicht das Team auch Guanaco, eine Familie von Chatbots, die auf den LLaMA-Modellen von Meta basieren. Die größte Guanaco-Variante mit 65 Milliarden Parametern erreicht in einem mit GPT-4 durchgeführten Benchmark fast 99 Prozent der Leistung von ChatGPT (GPT-3.5-turbo).
Das Finetuning großer Sprachmodelle ist eine der wichtigsten Techniken, um deren Leistung zu verbessern und erwünschte und unerwünschte Verhaltensmuster zu trainieren. Dieser Prozess ist jedoch für große Modelle wie LLaMA 65B extrem rechenintensiv und erfordert in solchen Fällen mehr als 780 Gigabyte GPU-RAM. Während die Open-Source-Community verschiedene Quantisierungsmethoden verwendet, um die 16-Bit-Modelle auf 4-Bit-Modelle zu reduzieren und damit den Speicherbedarf für die Inferenz erheblich zu verringern, waren ähnliche Methoden für das Finetuning bisher nicht verfügbar.
QLoRA ermöglicht Finetuning von 65 Milliarden Parameter LLM auf einer GPU
Mit QLoRA demonstriert das Team eine Methode, die es erlaubt, ein Modell wie LLaMA auf 4 Bit zu quantisieren und lernfähige Low-Rank-Adapter-Gewichte (LoRA) hinzuzufügen, die dann durch Backpropagation trainiert werden. Auf diese Weise ermöglicht die Methode das Finetuning von 4-Bit-Modellen und reduziert den Speicherbedarf eines 65-Milliarden-Parameter-Modells von über 780 Gigabyte auf weniger als 48 Gigabyte GPU-Ram - bei gleichem Ergebnis im Vergleich zum Finetuning eines 16-Bit-Modells.
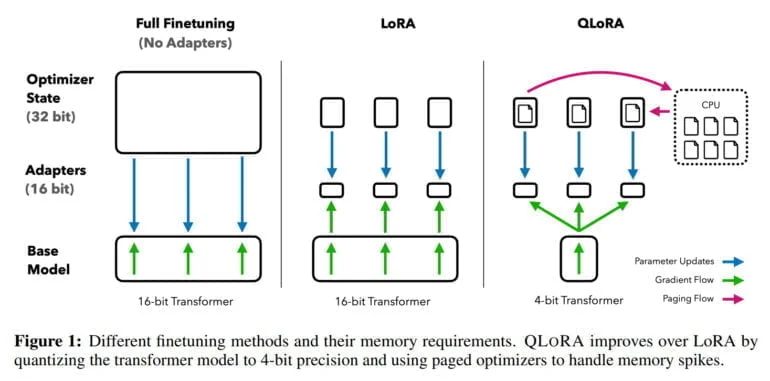
"Dies stellt eine bedeutende Veränderung in der Zugänglichkeit des LLM-Feintunings dar: die größten öffentlich verfügbaren Modelle können nun auf einer einzigen GPU fein abgestimmt werden", so das Team.
Um QLoRA und die Auswirkungen verschiedener Finetuning-Datensätze zu testen, hat das Team mehr als 1.000 Modelle mit acht verschiedenen Datensätzen durchgerechnet. Eine wichtige Erkenntnis: Die Qualität der Daten für die jeweilige Aufgabe ist wichtiger als ihre Quantität. So sind Modelle, die mit den 9.000 Beispielen von OpenAssistant trainiert wurden, bessere Chatbots als solche, die mit FLANv2 mit einer Million Beispielen trainiert wurden. Für Guanaco setzt das Team daher auf OpenAssistant Daten.
Open-Source-Modell Guanaco erreicht ChatGPT-Niveau
Mit QLoRA trainiert das Team die Guanaco-Modellfamilie, wobei das zweitbeste Modell mit 33 Milliarden Parametern in einem Benchmark 97,8 Prozent der Leistung von ChatGPT erreicht, während es auf einer einzelnen Consumer-GPU in weniger als 12 Stunden trainiert werden kann. Auf einer professionellen GPU trainiert das Team das größte Modell mit 65 Milliarden Parametern mit 99,3 Prozent der Leistung von ChatGPT in nur 24 Stunden.
Das kleinste Guanaco-Modell mit 7 Milliarden Parametern benötigt nur 5 Gigabyte GPU-Ram und übertrifft das 26 Gigabyte Alpaca-Modell im Vicuna-Benchmark um mehr als 20 Prozentpunkte.
Neben QLoRA und Guanaco veröffentlicht das Team auch den "OpenAssistant-Benchmark", der Modelle in 953 Prompt-Beispielen gegeneinander antreten lässt. Die Ergebnisse können dann von Menschen oder GPT-4 bewertet werden. Der Vicuna-Benchmark liefert nur 80.

Guanaco ist schlecht in Mathe, QLoRA könnte für mobiles Finetuning verwendet werden
Als Einschränkungen nennt das Team die mathematischen Fähigkeiten und die Tatsache, dass die 4-Bit-Inferenz derzeit sehr langsam ist. Als nächstes will das Team diese verbessern und erwartet einen Geschwindigkeitsgewinn von 8 bis 16 Mal.
Da das Finetuning ein wesentliches Werkzeug sei, um große Sprachmodelle in ChatGPT-ähnliche Chatbots zu verwandeln, glaubt das Team, dass die QLoRA-Methode das Finetuning zugänglicher machen wird - vor allem für Forschende mit geringeren Ressourcen. Das sei ein großer Gewinn für die Zugänglichkeit von Spitzentechnologie in der maschinellen Verarbeitung natürlicher Sprache. "QLoRA kann als ausgleichender Faktor gesehen werden, der hilft, die Ressourcenlücke zwischen großen Unternehmen und kleinen Teams mit Verbraucher-GPUs zu schließen", so das Team.
Abgesehen vom Finetuning der aktuell größten Sprachmodelle sieht das Team auch Anwendungen für private Modelle auf mobiler Hardware: "QLoRA ermöglicht auch datenschutzkonformes Finetuning auf dem Telefon. Wir schätzen, dass man mit einem iPhone 12 Plus jede Nacht 3 Millionen Wörter verfeinern kann. Das bedeutet, dass wir bald LLMs auf Telefonen haben werden, die auf jede einzelne Anwendung spezialisiert sind".
Eine Demo von Guanaco-33B gibt es auf Hugging Face. Mehr Informationen und Code gibt es auf GitHub. Da Guanaco auf Metas LLaMA aufbaut ist eine kommerzielle Nutzung nicht möglich.